


當手機取代了錢包,支付寶甚至比現金更常用,與螞蟻金服的產品端一同忙碌起來的還有公司的服務端。95188 服務熱線就是其中之一。
然而當我們談起客服電話,想到的仍然是傳統的按鍵菜單(「普通話服務請按 1,for English service please press 2」)和在機械而漫長的語音播報里等待的焦躁。「在過去的統計里,只要用戶沒轉接人工,就算作『問題被自助解決了』,其實在我們看來那不叫『解決』,叫『損耗』。」 螞蟻金服的產品運營專家弈客說。秉承著這樣的理念,團隊開發了 MISA(Machine Intelligence Service Assistant),一個能夠通過識別用戶的語音中包含的業務需求來直接進行回應的客服系統,他們稱之為「37攝氏度的自助語音交互」。
在金融業務領域,客戶服務涉及許多環節,通過人工智能的技術解決客服問題,為廣大用戶提供高效、個性化的普惠金融服務,成為金融科技領域非常基礎、非常具有挑戰性的課題。
最近,在螞蟻金服發起的「ATEC螞蟻開發者大賽——人工智能大賽」上,這支團隊在初賽就拿出了來自實際應用場景的 10 萬對標注問題集,并開放相關資源與專家指導,邀請人工智能開發者來挑戰「問題相似度計算」這一客服領域最基礎也最核心的任務。
如今,賽事已經集結了來自全球超過兩千支隊伍報名,并開啟了激烈的準確率打榜競賽。近日機器之心也有幸探訪螞蟻金服,采訪了 MISA 團隊中的三位核心成員:人工智能部資深算法專家深空(張家興 )、客戶服務及權益保障事業部產品運營專家弈客 (于浩淼 ) 以及人工智能部算法專家千瞳(崔恒斌 ),聊了聊如何利用深度學習算法構建能夠「未卜先知」的客服系統。以下內容根據采訪實錄整理,機器之心對內容作了不改變原意的調整。
MISA 的「成長故事」與「近照」
機器之心:開發 MISA 系統的初衷是什么?
弈客:95188 支付寶服務熱線是一個典型的 IVR 場景(Interactive Voice Response,互動式語音應答),作為一個語音渠道,它的業務目標很簡單,就是「定位用戶的問題,匹配相應解答方案」。一開始,它就是一個傳統的按鍵菜單,后來隨著螞蟻金服業務線的日益增長,按鍵菜單無法滿足業務需求,同時語音識別技術也進入了一個基本可以投入應用的階段,所以從 16 年初開始,我們和算法工程師一起,嘗試找新的解決方法。
最初的想法是讓用戶描述自己的問題與場景,然后將描述與我們的業務與知識進行一次匹配。后來,我們發現單次匹配也很難做到特別精準,因為用戶很難在單次描述里給出全部所需要素,所以就嘗試以多輪交互的形式,用一個對話系統來幫助用戶補全其描述中缺失的部分。
再后來,我們發現與其讓用戶完全清楚地描述自己的問題,不如我們率先發問。我們做了大量的市場調研,發現如今市面上的客服系統也基本上以「描述與匹配」模式為主,涉及多輪交互的本身就很少,在多輪基礎上發展方向也沒有那么明確。因此我們就回到了螞蟻自身。我們就想,能不能基于用戶在提問時所積累的行為特征,以「猜問題」的形式讓系統率先發起對話,降低用戶的使用難度。相比于「你有什么問題?」,「你是不是想問XXX 問題?」就要容易回答得多,即使用戶回答「不是」,我們的問題也會為他接下來的描述提供一個示例。
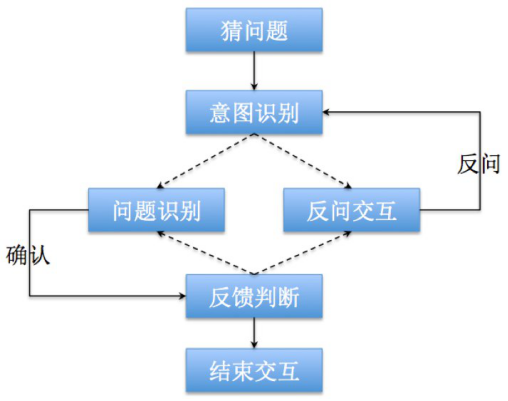
圖:如今的 95188 語音服務流程
機器之心:現在 MISA 的系統由哪些部分組成?分別完成什么任務?
深空:MISA 的主要模塊有猜問題、問題識別、反問交互三個。「猜問題」是螞蟻金服在客服領域的首創,是一個利用用戶可能與本次致電相關的信息,基于深度學習算法框架構建的問題識別模型。「問題識別」是根據用戶的描述定位他可能遇到的問題。「反問交互」是在用戶給出的信息不全時,利用「要素拆解和補全」的方式幫助問題識別模塊圈定范圍,降低問題識別的難度,以反問的形式與用戶進行交互。
機器之心: 除了用戶轉為文本的語音輸入外,MISA 的系統還會接收哪些輸入?如何分類?
深空:我們將輸入分為因子、軌跡、文本三類。因子是由業務方定義的、具有明確含義的特征,例如:過去24小時是否有還款行為、過去24小時是否發生過轉賬行為等。因子大約有數百個。軌跡是用戶最近的 120 個「行為」組成的時間序列,其中一個行為指對遠程服務器發生一次請求。行為的種類超過一萬種。文本是用戶的描述以文本形式表達;在「猜問題」環節,文本指用戶的歷史描述,在正常的「問題識別」環節,文本即把本次電話里用戶對問題的語音描述轉換成文本。文本是一個長度各不相同,甚至可能空缺的輸入。
機器之心:作為一個以識別為主要目的的系統,MISA 會將用戶的問題匹配到多少種類型里?如何給出應答?
弈客:需要匹配的問題類型的具體數字隨著業務上線與下線會有浮動,規模大約在「數千」這個量級。
大框架上,應答可以分為三類。第一類,如果用戶的問題很簡單,能用一兩句話說清楚,我們就以播報的形式輸出。比如之前余額寶一個業務的產品方案進行了調整,從不限轉入金額到每天最多只能轉入兩萬。這時候當用戶轉入出錯前來咨詢,我們就會以播報形式把業務調整通知給用戶。第二類,如果方案需要用戶在某一個產品頁面進行操作與交互,我們就會把相應頁面在用戶的 app 里拉起來。用戶掛掉電話打開 app,就能看到解決方案頁面的推送,點開就可以完成操作了。最后一類,我們判斷相對復雜的問題,就轉接人工小二處理。
機器之心:一位用戶平均需要與系統進行多少輪對話能夠定位到自己的問題呢?
弈客:一開始系統能力還沒有那么強的時候,我們把最多對話輪數設置為 4 輪,如果 4 輪對話之后用戶的問題仍然沒有得到解決,就轉交人工客服。通過不斷的優化,現在用戶的平均對話輪數不超過兩輪,大概在 1.8-1.9 左右。
客服系統是怎樣煉成的:模型選擇、評估與優化
機器之心:在處理自然語言文本時,用到了哪些深度學習模型?
千瞳:我們首先用自己預訓練的詞向量對文本進行表示,然后分別用到了卷積神經網絡(CNN)和以 LSTM 為基本單位的循環神經網絡(RNN)對文本進行處理。
卷積神經網絡中,模型對由詞向量組成的文本做一維單層卷積與池化,形成一個向量,RNN 則把文本視為一個序列,處理后也得到一個向量,最后,將兩個向量相加,得到一個代表本段文本的新向量,然后與代表因子和軌跡的向量加在一起,進行分類。
機器之心:為什么同時采用 CNN 和 RNN?
千瞳:兩種模型提取特征的能力不同。CNN 的能力在于提取關鍵詞。RNN更善于捕捉序列關系。
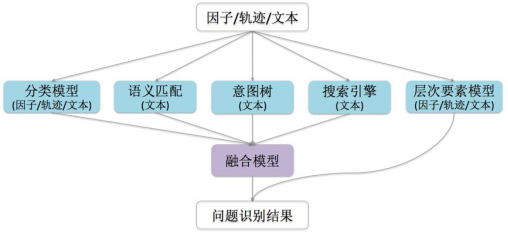
機器之心:分類模型與問題識別模塊的關系是?
千瞳:問題識別模型是由多個子模型+融合模型的形式組織的。分類模型只是其中一種子模型,除此之外,還有搜索、意圖樹等多個結構化子模型。不同模型的輸出格式也各不相同,分類模型返回不同類別的可能性打分,而意圖樹可能只返回某一個最可能的類別。在子模型各自進行問題識別后,我們會通過一個GBDT的模型,對前四個模型的結果進行融合。在融合模型階段,我們取每一個模型的 top1 輸出,根據標注數據來選擇輸出可能性最高的那個模型的結果。
機器之心:反問交互是如何實現的?
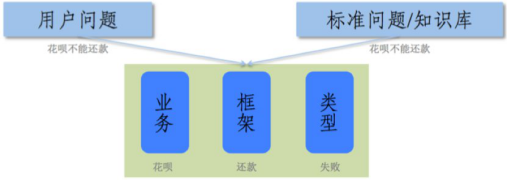
弈客:如今一百通電話里,有三十通會率先通過猜問題的形式對用戶進行發問。如果沒有猜中,就要思考如何在較短的輪數內摸清用戶的需求。用戶的大多數問題都能夠以「業務、框架、類型」三要素方式進行拆分。例如「花唄不能還款」,「花唄」就是涉及的業務,問題的核心動詞「還款」就是框架,「失敗」是導致用戶提問的訴求類型。有超過一千個用戶問題都可以被拆解成三要素的形式,其中包括一百多類業務、不到一百類框架和不超過十種問題類型。
三要素拆分方式的方式能夠幫助快速縮小識別范圍。用戶在描述中,可能不能一次把三要素都描述清楚,但是如果給出了某部分要素,比如用戶說「我要還款」,就給出了框架「還款」和類型「如何」,這時我們就可以就缺失的「業務」要素進行反問,比如,「您是要進行花唄還款、借唄還款還是信用卡還款?」
千瞳:從技術的角度上來講,我們在構建了語義要素庫之后,是可以實現 zero-shot 的問題識別的。即,不需要見到特定的要素組合的訓練樣本,只要在其他訓練樣本中見過單獨的要素在其他場景下出現,一樣可以識別這個要素組合,對應到相應問題。
另外,我們也構建了多任務學習的框架。三要素識別任務的目標是非常類似的,都可以看做是多分類問題。多任務學習讓不同任務間的數據可以共享。雖然每一個單獨的任務都有足夠的數據,但是不同任務間目標會讓特征提取各有側重,提高模型效果。相比單模型,識別準確率可以提升7個百分點。
機器之心:如何評估匹配的精確程度?這些評估是否會反過來影響模型的優化?
千瞳:匹配的評估指標有多個層級,第一個是CTR(Click Through Rate),比如在「猜問題」階段,用戶會確認系統猜的是不是他的問題。第二個是分流的準確率,如果分配到人工還有小二派單準確率,最后是問題解決率。
至于用戶的評估如何影響模型優化,一言以蔽之,用戶的反饋就是模型的訓練數據,系統自己能形成一個閉環迭代體系。 MISA 的大部分模型一周迭代兩次。
關于比賽:客服領域里的相似度計算
機器之心:比賽中的「判斷兩句話是否為同義句」任務和利用分類法進行問題識別任務之間的關系是什么?
深空:當我們拿到一個用戶的自然語言問句,想判斷它是知識庫里的哪一類問題時,通常有兩種做法:一是做分類,也就是上面講到的問題識別;還有一種做法就是判斷同義句,給出每一類問題的幾條例句后,當一個新的問句出現,就計算新問句與每一條例句之間的相似度。
相比于識別,同義句是一類相對昂貴但具有重大意義的做法。對于許多拿不到豐富數據的場景來說,訓練分類器變得不可能,而搜集例句、計算相似度相較之下更為可行和合適。
基于相似度計算的分類算法對于數據的需求要靈活得多,可以根據數據的情況分層次安排:有的方法可以不需要訓練數據,基于規則來做;有的方法可以基于領域無關的、有公開語料的通用數據進行訓練;當然,如果提供領域相關的數據,可以讓相似度計算得更好,就像我們這次提供的數據這樣。
從工程的角度來講,這種一開始對訓練數據依賴較小的辦法,有利于工程師按部就班把一個問題解決掉。
機器之心:選擇判斷同義句作為本次大賽賽題的原因都有哪些?
深空:第一,在將用戶的問句分類的場景下,相似度計算是一種基礎而實用的做法。在客服領域里,大多數應用場景仍然是缺少數據的。第二,問題的相似度計算在其他場景下也有廣泛的應用,例如,在「挖掘用戶常見問題」任務里,就要對用戶問句進行聚類,將每一類常見問題歸為一類。聚類的基礎就是計算每兩個問句之間的相似度。還有許多其他類似的應用。總而言之,相似度計算是客服大領域中非常基礎、非常核心的一個問題。
這次比賽的重點就是鼓勵選手找到好的相似度計算方法。本次我們在初賽就提供了 10 萬條數據。作為對比,現在的相似度計算比賽中最大的公開數據集大概在 1 萬條左右。但是我們不強制選手使用提供的數據,完全不基于數據或者引入外部數據的做法都是被允許的,希望選手們不拘一格,找到最好的相似度計算方法。
機器之心:是否會考慮將比賽中出現的做法投入到實際生產中?
千瞳:這是肯定的。螞蟻的業務發展非常快,因此在設計算法的過程中會遇到很多現實的問題:比如用戶描述口語化、描述多樣性、糾錯以長句問題等等,都需要相似度計算方法去解決,我們自己也在進行大量相似度計算方面的探索,希望能夠和選手們一起,找到最合適的方法。








 京公網安備 11010502049343號
京公網安備 11010502049343號