









上周二,因為一條錯誤指令導致的AWS 宕機事件,影響了大量流行的網站和服務。此事件對用戶來說,是服務的中斷;對AWS來說,是巨額的損失;對旁觀者來說,是寶貴的經驗。
編者按
想象一下:一個工作日的上午,你使用的云服務的可用性瞬間從平均水平跌至0;丟包率則上升到100%。作為一名用戶,你會做出怎樣的判斷?這應該不是著名的DDoS攻擊,因為在遭遇DDoS攻擊時,丟包率與可用性是隨著時間推移而發生變化的。而這種瞬間的停機現象應該是云服務商出現了故障。
上個周二,云計算鼻祖AWS就發生了這樣的事故。AWS美國東一服務區基礎設施的出入流量瞬間消失。那么,AWS是如何解決這次事故?接下來會有哪些優化舉措?技術人應該從中學習到什么經驗?
事件回顧
2月28日上午(太平洋時間)AWS發生了服務宕機事件。事件的起因是AWS S3(云存儲)團隊在進行調試時輸入了一條錯誤指令,本應該將少部分的S3計費流程服務器移除,可是最終意外移除了大量服務器。被錯誤移除的服務其中運行著兩套S3的子系統,從而導致S3不能正常工作,S3 API處于不可用狀態。
由于S3負責存儲文件,為AWS體系中的核心組成部分,這導致北弗吉尼亞日(美國東一)服務區中,依賴于S3存儲服務的其他AWS的S3 控制臺、Amazon彈性計算云(簡稱EC2)新實例啟動、Amazon彈性塊存儲(簡稱EBS)分卷(限于需要讀取S3快照的數據)以及AWS Lambda均受到影響。
AWS的修復動作
一條錯誤命令直接導致了AWS兩套子系統無法工作:
第一套子系統為索引子系統(Index):負責管理該服務區內全部S3對象的元數據與位置信息。此子系統為一切GET、LIST、PUT與DELETE請求正常運作的必要基礎。
第二套子系統為位置子系統(Palcement):負責管理新存儲空間的分配并需要配合之前的索引子系統以實現正常運作。這套位置子系統用于在響應PUT請求時為新對象分配存儲空間。
兩套子系統容量被大量移除,發生故障重啟,但是S3依然無法正常響應請求。位置子系統依賴于索引子系統,因此AWS選擇了按照順序修復兩個子系統,再解決S3和其他服務的問題。

哪些用戶受到了影響?
S3于2006年發布,是 AWS 最早的諸多服務之一,官方曾稱其具備99.999999999% 的持久性(durability)和 99.99% 的可用性(availability)。
它的一些典型使用場景如下:
存儲用戶上傳的文件,如頭像,照片,視頻等靜態內容
靜態網站的托管
當作一個的key value store,承擔簡單的數據庫服務功能
數據備份
大數據分析
S3擁有很多明星用戶:Airbnb(處理超過10PB的用戶圖像)、Nasdaq(支持 FinQloud 的監管記錄保留 (R3) 數據存儲解決方案和 Query)、Netflix(分發數十億小時的內容)。
此次事故波及眾多公司,外媒的統計名單中A-Z的26個字母全部占滿,其中包括Adobe、Docker、GitHub、Slack、GE、Quora等知名公司。在此期間,部分Apple用戶們也受到影響;不過蘋果一直在打造自己的數據中心,報道稱蘋果預計斥資五千余萬美元進行數據中心的擴建。
對AWS而言,這次事故意味著?
Thousandeyes公司是AWS S3的使用者,產品營銷高級主管Nick Kephart在接受采訪中認為,根據S3服務水平協議,此次停機(持續達3小時)可能意味著S3已經無法達到協議中指定的99.9%正常運行閾值。因此,美國東一服務區內最具人氣的S3服務以及其它受影響AWS服務可能給Amazon帶來高達10%的月度營收影響。根據粗略估算,這一服務水平協議違約可能造成數百萬乃至數千萬美元的損失。
AWS在Amazon公司的財務構成當中扮演著越來越重要的角色;2016年第四季度,AWS為其母公司貢獻了高達35.3億美元營收,利潤則為9.26億美元。
其實除了經濟損失之外,這也不失為AWS的技術學習機會。
AWS的技術反思
為什么這么久?
存儲量龐大
AWS在其官方聲明中成雖然S3子系統的有故障承受能力,但是此次事故中涉及的兩個子系統再數年來在大規模服務區未曾重啟。S3的服務規模快速提升,而對這些服務進行重啟并運行必要安全檢查以驗證元數據完整性,這些流程最終所需時間遠超AWS預期。對于此說法,曾經在Amazon工作過的陳皓表示認同,他稱AWS沒有公布的存儲數量級相當驚人;要先恢復索引子系統再恢復位置子系統,就像個人的操作系統從異常關機后啟動,文件系統要做系統自檢那樣,硬盤越大,文件越多,這個過程就越慢。
服務沒有被拆分成更小
同時AWS表示,服務需要被進一步分解成更小的單元:S3團隊已經計劃于今年晚些時候對該索引子系統進一步拆分,很可能立刻著手進行。
為什么Dashboard失效?
從此次事故開始直到上午11:37(太平洋時間),AWS服務運行狀態儀表板(簡稱SHD)上一直無法更新各項個別服務的運行狀態,這是由于該儀表板的管理控制臺運行依賴于Amazon S3。因此,AWS轉而使用AWS Twitter Feed(@AWSCloud)與SHD橫幅通知文本發布狀態更新,直到重新恢復在SHD之上更新個別服務狀態的能力。AWS表示其了解SHD在業務運行期間為客戶提供提示信息的重要意義,因此目前已經將SHD管理控制臺調整為跨多個AWS服務區運行。
改進措施?
AWS在此次官方聲明中不僅公布事故起因、解決過程,而且分析了技術問題并決定了改進措施。大致分為以下兩個方面:
事故的發生:大量移除操作不應該如此容易
AWS稱其正在根據此項事故進行數項調整,盡管移除容量屬于一項關鍵性操作實踐;但在目前的情況下,AWS使用的工具在移除容量時的執行速度過快,已經對此工具進行了修改以更慢進行容量清除。同時,AWS增加了安全措施以防止任何子系統在容量移除后遭遇現有容量低于最低容量需求的情況。此外,AWS也在審查當前使用的其它操作工具,以確保在其中引入類似的安全檢查機制。
事故發生后:恢復時間不應該如此漫長
AWS會采以多種技術以確保服務能從任何故障中迅速恢復,其中最為重要的舉措之一在于將服務拆分成更小分區(AWS將其稱為Cell)。通過將服務進一步分解為Cell,工程技術團隊能夠評估并全面測試各類大規模服務或子系統的恢復流程。
吃瓜群眾應該從中學到什么?
AWS的官方聲明最后一段寫到:“最后,我們要對此次事故給客戶造成的影響誠摯道歉。雖然我們對于Amazon S3長期以來的可用性表現感到自豪,但我們清楚這項服務對于我們的客戶、其應用程序、最終用戶以及業務的重要意義。我們將盡一切努力從這次事件中積累經驗教訓,并以此為基礎進一步提升我們的服務可用性。”
那么,對于其他人而言,從這次事故中我們能學到什么呢?InfoQ收集整合了三位技術專家陳皓、陳天、Nick Kephart給出的思考整理如下:
要注意Error Handling
當問題出現時,一個普通的 S3 GET 返回什么:
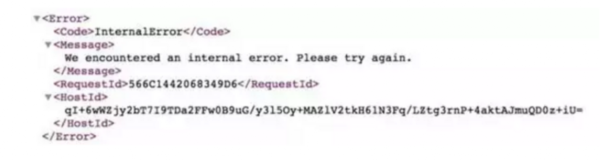
所以AWS 告訴你Internal Error 了。
從 error handling 的角度,陳天認為在寫代碼的時候都應該捕捉這個異常,然后做合適的錯誤處理。很遺憾的是,S3 這樣的服務是如此基礎,就像互聯網的水和電一樣,大家默認為它永遠不會出錯。因此,好多工程師干脆不做錯誤處理。
除了代碼編寫層面的處理,當云服務商的宕機發生時,盡量控制它影響面。像 Trello連 landing page 都一并掛掉實在不可取,因為起碼 S3 影響不到的頁面,如 landing page,用戶注冊 / 登錄頁面,應該還保持正常服務;而像 Quora的服務,其實是可以準備一個靜態化的鏡像,一旦出問題,起碼讓讀者可以無障礙地閱讀。
盡可能地把動態內容緩存起來,甚至靜態化
Redis cache、Nginx cache、HAProxy、CDN 都是把內容緩存甚至靜態化的一些手段。陳天認為:盡管多級緩存維護起來是個麻煩,但當底層服務出現問題時,它們就是難得的戰略緩沖區。cache 為你爭取到的半個小時到幾個小時幾乎是續命的靈芝,它能幫你撐過最艱難的時刻(這次 S3 宕機前后大概 4 小時,最嚴重的時候是 11點到1點),相對從容地尋找解決方案,緊急發布新的頁面,或者遷移服務,把損失降到最低。否則,只能像這次事件中的諸多公司一樣,聽天由命,雙手合十祈禱 AWS 的工程師給力些解決問題。
云用戶應檢查核心依賴關系,提升關鍵性服務的冗余水平
S3是多種Amazon服務的核心組成部分之一。無論是利用其進行簡單文件存儲、對象存儲抑或是用于存儲網站或者應用程序中的內容,其間復雜的依賴性都必須會引發級聯效應。S3能影響到的組件包括用戶會話管理、媒體存儲、內容存儲、用戶數據、第三方對象和自動化機制等。
在Thousandeyes公司的Nick Kephart看來,云用戶應檢查核心依賴關系,提升關鍵性服務的冗余水平。AWS的系統在構建當中具備冗余特性,能夠實現跨數據中心自動復制存儲對象與文件。而作為另一種冗余層,云用戶需要利用額外AWS服務區或者其它云服務供應商以徹底避免此類事故;不過這會增加大量管理復雜性與成本支出,因為跨環境間的數據同步工作需要由云用戶負責打理。大多數企業并沒有選擇上述選項,可是單純的數據備份在數小時的短周期內并不能發揮作用。
雖然面向云環境的遷移確實能夠在穩定性與彈性方面為企業帶來巨大幫助,但是各種不易被發現的依賴性也因此增加,單一服務失敗可能引發大規模服務癱瘓。Nick建議云用戶的開發與運營團隊審查與云服務供應商間的核心依賴關系,制定策略以監控各項服務可能受到的影響,同時調整現有架構以提升關鍵性用戶的冗余水平。
故障演習很重要
對于這次事件,陳皓在其博客中表示美國東一區作為老牌的服務區擁有海量對象,能在數小時恢復已屬不易,并且幸運的是沒有丟失重要數據。
陳皓重申了其觀點:一個系統的高可用的因素很多,不僅僅只是系統架構,更重要的是——高可用運維。并且,他認為對于高可用的運維,平時的故障演習是很重要的。AWS 平時應該沒有相應的故障演習,所以導致要么長期不出故障,一出就出個大的讓你措手不及。比如,Facebook每個季度扔個骰子,隨機關掉一個IDC一天。Netflix 有 Chaos Monkey,路透每年也會做一次大規模的故障演練——災難演習。
在陳天看來,這種容錯的操練適合大一些且工程團隊有余力的公司。為什么Netflix 重度使用 AWS,卻在歷次 AWS 的宕機中毫發無損?其實Netflix之前也深深地被云的「不穩定性」刺痛過,而如今他們的 Chaos Monkey(之后發展為 simian army)服務,會隨時隨地模擬各種宕機情況,擾亂生產環境。比如說對于此次事件的演練,可以配置 simian army 去擾亂 S3:simianarmy.chaos.fails3.enabled = true。
這樣,這群討厭的猴子就會在不知情的情況下隨機把服務器的 /etc/hosts 改掉,讓所有的 S3 API 不可用。如此就可以體驗平時很難遇到的 S3 不可訪問的場景,進而找到相應的對策(注意:請在 staging 環境下謹慎嘗試)。
處理危機的方式能看出一個公司的高度
陳皓表示非常喜歡GitLab、AWS這樣向大眾公開其故障及處理流程,哪怕起因是一個低級的人為錯誤,也不會掩蓋、不會文過飾非。AWS公布的后續改進方案都是為了讓系統更加高可用,這是很技術范兒的表現。恐怕對比國內公司對于此類故障,基本上會是下面這樣的畫風:更多更為嚴格的變更和審批流程,限制更多的權限系統和審批系統,更多的人進行操作,使用更為厚重的測試和發布過程,懲罰故障人,用價值觀教育工程師。
在陳皓看來——如果你是一個技術公司,你就會更多的相信技術而不是管理。相信技術會用技術來解決問題,相信管理,那就只會有制度、流程和價值觀來解決問題。(注意:并非隔離技術和管理,只是更為傾向于用技術解決問題)
事故發生后,InfoQ聯系了AWS工作人員并表達了采訪意愿。AWS雖然最終婉拒,但是稱媒體的客觀報道可以督促其提升技術服務質量。
這段時間,IT界尤其是大公司發生的技術故障并不少見。當IT技術服務越來越多的人的時候,宕機之事也自然也會影響并引得廣泛的關注。眾目睽睽之下,如GitLab和AWS這樣保持坦誠踏實的態度,其實是在用另一種方式贏得對技術的尊重。沒有人愿意看到問題的發生;但是問題出現后,最重要的解決反思并從中汲取教訓:這難道不是技術人應有的傲骨嗎?
參考文章
https://aws.amazon.com/cn/message/41926/
http://coolshell.cn/articles/17737.html
http://www.channelnews.fr/panne-service-s3-damazon-a-dure-pres-de-15-heures-70575
https://www.infoq.com/news/2017/03/aws-s3-disruption
https://www.infoq.com/news/2011/04/Amazon-EC2-Outage-Explained
















 京公網安備 11010502049343號
京公網安備 11010502049343號