


好在每個主要的公共云供應商都提供了構建高度可用環境的選項,這些環境可以在某種類型的中斷得以恢復和幸免。例如,AWS公司提出了利用多個地理區域的四個選項。這些選項(其他公共云供應商也可以使用)具有不同的價格,并提供不同的恢復點目標(RPO)和不同的恢復時間目標(RTO)。
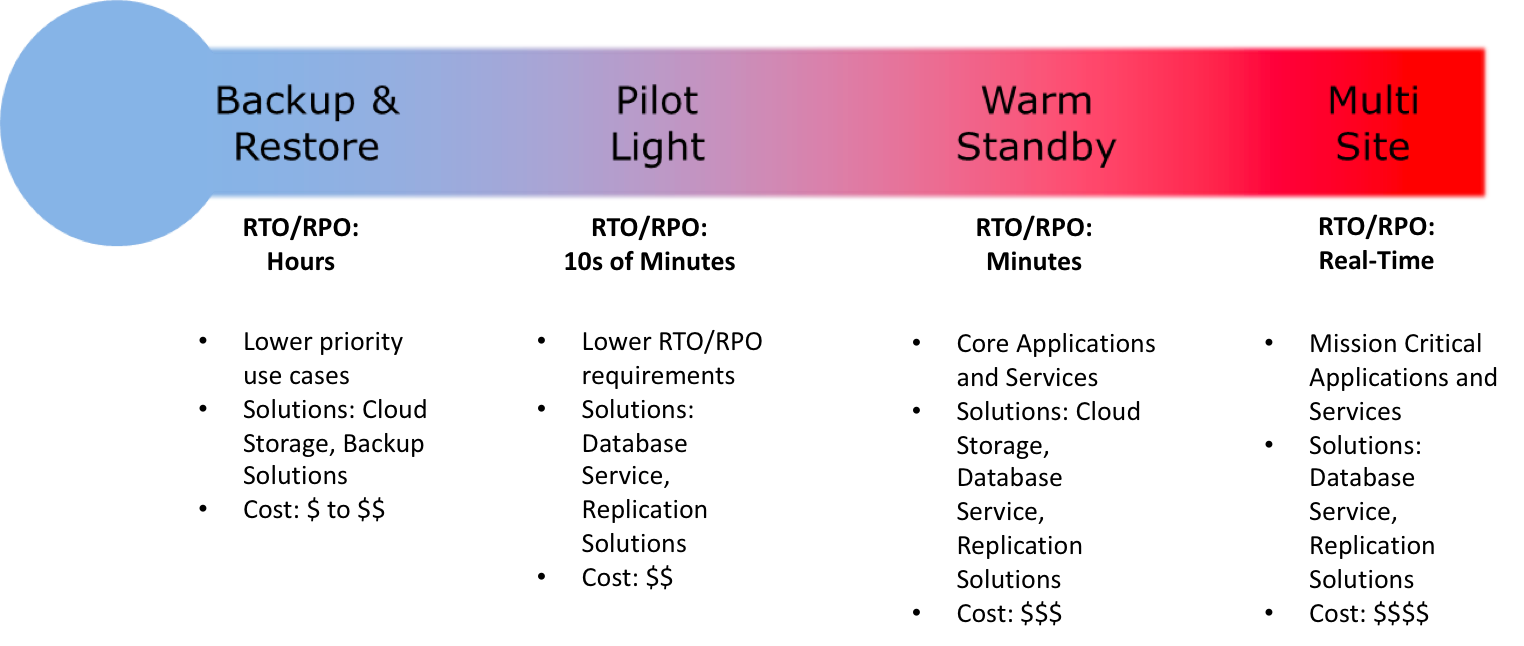
企業可以選擇最符合其恢復點目標(RPO)和不同的恢復時間目標(RTO)的要求和預算的選項。關鍵是公共云提供商能夠幫助客戶在其全球基礎設施上構建高可用性解決方案。
以下簡要介紹一下這些選項,并回顧一些使用公共云構建高可用環境的基本原則。以AWS公共云作為示例,但這些原則適用于所有公共云提供商。
首先,企業需要了解每個應用程序的恢復點目標(RPO)和恢復時間目標(RTO),以便為每個用例提供正確的解決方案。其次,對于利用多個地理區域來說,沒有一個萬能的解決方案。企業根據恢復點目標(RPO)、恢復時間目標(RTO)、愿意和能夠承擔的成本數量,以及愿意做出的權衡,可以采取不同的方法。
以AWS為例,其中一些方法包括:
•從備份恢復到其他區域,人們將環境備份到S3,包括EBS快照、RDS快照、AMI和常規文件備份。由于S3在默認情況下僅將數據復制到單個區域內的可用區域,因此企業需要啟用到災難恢復區域的跨區域復制。企業將承擔在第二個區域傳輸和存儲數據的成本,但不會產生計算、EBS或數據庫成本,直到企業需要在其災難恢復區內生效。而權衡是啟動應用程序所需的時間。
•在另一個區域進行熱備份,將數據復制到第二個區域,這里企業將運行一個縮小版的生產環境。這個環境始終處于活動狀態,并且其大小適合恢復業務所需的最小容量。企業根據需要使用Route 53切換到災難恢復區域。根據需要將環境擴展到全部容量。有了這些選項,企業可以更快恢復數據,但會產生更高的成本。
•多區域“Active/Active”解決方案,在這個方案中,數據在兩個區域之間同步,并且兩個區域都用于為請求提供服務。這是最復雜的設置和最昂貴的方案。然而,即使整個區域出現故障,停機時間也會很少或根本沒有。雖然上述方法實際上是災難恢復解決方案,但這個方案是關于構建真正高度可用的解決方案。
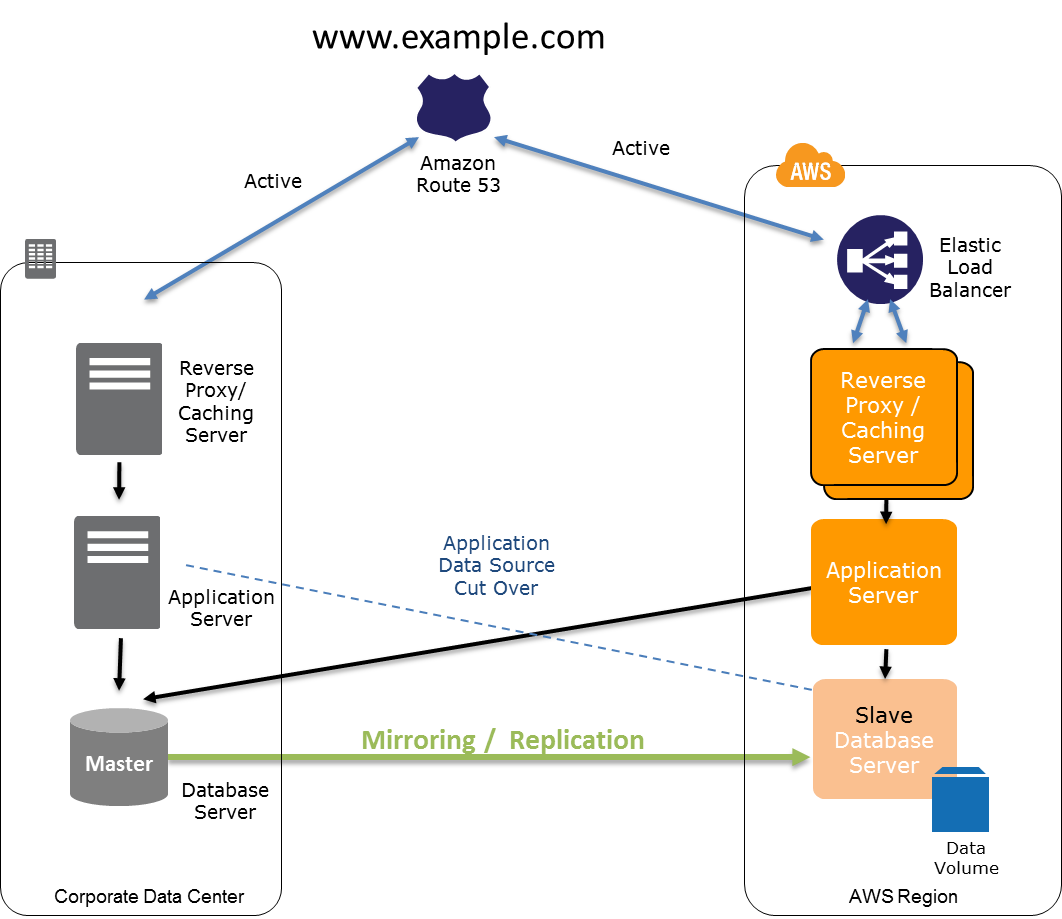
成功的多區域設置和災難恢復流程的關鍵之一是盡可能采用自動化工具。這其中包括備份、復制和啟動企業的應用程序。利用Ansible和Terraform等自動化工具來捕捉環境狀態并自動啟動資源。此外,重復測試以確保企業能夠成功從可用區域或區域故障中恢復。這不僅要測試工具,還要測試其過程。
版權聲明:本文為企業網D1Net編譯,轉載需注明出處為:企業網D1Net,如果不注明出處,企業網D1Net將保留追究其法律責任的權利。








 京公網安備 11010502049343號
京公網安備 11010502049343號