


在初創科技公司工作就像在救火隊,需要對抗不時出現的火情(如果你迭代速度越快,則會越頻繁)。每一次撲滅能換來幾個月的平靜,但你心底特別清楚,這事兒沒完。因此如何徹底贏得這場戰斗變得很重要。
手頭的問題
首先,一些背景 -- 我們每天晚上都會運行一個Celery任務,執行一些重要而且耗時的計算,以保持數據庫中某個表的“新鮮度”。它是我們代碼庫的關鍵組件之一,確保每天都能成功完成該項任務相當重要。由于它涉及的數據量相對較大,早期就帶來了一些麻煩,現在已經在該任務上使用了不止一種優化。該任務最近完全停止執行,而且為解決其他問題而查看生產環境上的日志時還發現了段錯誤信息。

思考該任務代碼的一個超簡化版本 -:
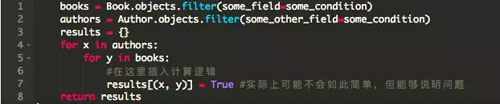
`books`和`authors`都是Django查詢結果集,當然不能完全代表我們的實際模型。在我撰寫本文時后者有2012個對象,前者約有17k個對象。自從這個任務開始以來,這個雙層for循環一直能夠很好地如期工作。后來,我們去年遇到了第一次內存故障,以及最近的段錯誤。我決定將代碼剝離為基本要素,類似于上面所示的代碼的樣子,并使用htop命令運行一些測試。下圖的gif動圖是我在測試機器上調查該問題時情形,測試機器有4G內存,生產機器上是10G內存

(每次增加約200M內存)
(按照簡化代碼)內存使用率增加得相當快,蹭蹭地達到了機器上4G的上限。如果我要用空間復雜度來度量,那么這就是OMN),其中M和N都是(近似的)線性函數,它跟蹤兩個查詢集隨時間的增長。M明顯比N慢。
批量處理查詢集(Queryset)
然后,我重新使用了一年前采用的第一個優化 -- 批量處理查詢集。在我們的腳本中有兩個主要的消耗內存的地方,第一個地方是Python數據庫連接(在本例中是Python MySQL DB連接),它的任務是執行SQL查詢并返回結果,第二個是查詢集緩存。查詢集批量處理是首選方法。
以下是使用了查詢集批處理的第二個版本的代碼 - :
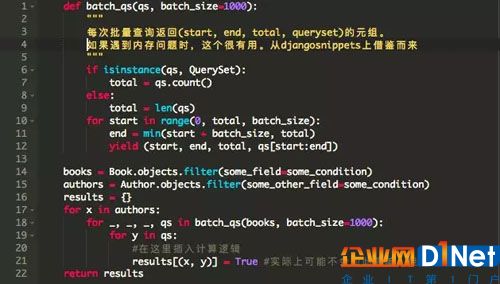
我們再次執行這個任務,并查看htop。

(增長放緩了,但終究還是會達到上限)
嗯。內存使用率增長的速度比上次更慢,但它不可避免地會達到了上限或出現段錯誤。這能夠說得通,因為queryset批處理不會減少從數據庫中獲取的結果的數量。只是通過配置批量的大小,每次盡可能少地將指定內容保留內存中。這最終導致了我們當前遇到的困境,因此有了第二次優化的需求。
查詢集(Queryset)的本質
據說Django的查詢集具有延遲加載和緩存的機制。延遲加載意味著,除非對查詢集執行了某些操作(例如遍歷它),否則將不會事先執行那些數據庫查詢。緩存意味著如果您重新使用相同的查詢集,則不會重復執行多次相同的數據庫查詢。
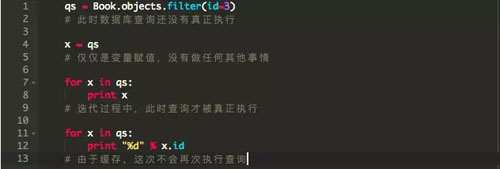
緩存在這里如何起作用?事實證明,由于緩存機制,我們不能“扔掉”(垃圾收集)已經使用的批量結果。在我們的例子中,我們只需要使用一次批量結果,緩存它們是浪費內存。直到函數結束緩存才會被清除。為了解決這個問題,我們在查詢結果集上使用iterator()函數。

讓我們再來試一下。按道理內存使用量增長速度應該減慢。

(似乎還是不對)
但實際上沒有...
破釜沉舟,背水一戰
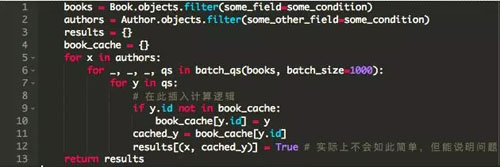
不管怎么樣,盡管使用了迭代器,我們仍將某些東西存儲在內存中。讓我們仔細看看代碼。是否存在可能阻止垃圾回收器回收內存的對象引用?發現真有一個地方 -- 字典使用元組作為鍵來存儲對象。
我運行了一個簡單的測試就是將這一行注釋掉,看看這個任務需要多少內存。內存使用不再瘋狂攀升,而是停止在一個特定的值上。
對于來自外層循環的author,我們在內部循環中遍歷book不同“拷貝”。對于兩個不同的author A1和A2,由于使用迭代器,元組(A1,B)和(A2,B)指向內存中B的不同副本。因此,我們必須按照特定規則重新引入緩存。

(不再快速增長了)
再次運行測試。內存使用量增長緩慢,在某些值附近徘徊,并在一段時間后顯著下降(圖中并未顯示出來)。book_cache的目的是遍歷一次所有book對象后將所有book對象保存起來,以便在隨后的多次遍歷中重新使用。y在隨后的遍歷中所指向的對象會被垃圾回收,之后便會使用緩存的版本。現在,對于(A1,B)和(A2,B),兩個B都指向內存中的同一個對象。最后,iterator()允許我們控制我們如何使用我們的空閑內存。這個最終代碼的空間復雜度為O(M + N),因為我們在內存中只保留了每個book對象的一個副本
請注意,這僅僅解決了我們眼前的問題。隨著數據庫規模的擴大,會出現更多導致離線問題。這意味著代碼并不完美,但是,目標永遠不會是“完美代碼”,而是“優化當前代碼”。
順便說一句:為了回復一些評論中的建議 - 我確實可以將對象的ID(ID和對象組合)作為關鍵字進行存儲。這是理想的解決方案。但是在這種情況下這對我并不適用,因為上面的代碼是較大工作流程實際案例的一小部分






 京公網安備 11010502049343號
京公網安備 11010502049343號