









要實(shí)現(xiàn)這個目標(biāo),架構(gòu)設(shè)計(jì)至少要滿足三個總體技術(shù)要求:
- 一是把分布式大數(shù)據(jù)平臺的基礎(chǔ)數(shù)據(jù)服務(wù)能力建設(shè)擺在首位。規(guī)劃出支撐PB級規(guī)模數(shù)據(jù)運(yùn)營能力的云平臺架構(gòu),運(yùn)用經(jīng)典設(shè)計(jì)原則和設(shè)計(jì)模式的架構(gòu)之美,吸納業(yè)內(nèi)主流分布式技術(shù)的思想精髓,深耕主流平臺服務(wù)模式到現(xiàn)代微架構(gòu)的演變內(nèi)涵;
- 二是用系統(tǒng)架構(gòu)設(shè)計(jì)和微服務(wù)建設(shè)思想武裝團(tuán)隊(duì),持續(xù)撰寫多維度的架構(gòu)藍(lán)圖,推動團(tuán)隊(duì)協(xié)同作戰(zhàn);
- 三是圍繞大數(shù)據(jù)全棧技術(shù)體系解決項(xiàng)目實(shí)戰(zhàn)中的各類難題,制定主流技術(shù)規(guī)范和設(shè)計(jì)標(biāo)準(zhǔn),通過平臺核心組件方式快速迭代出新型業(yè)務(wù)。從設(shè)計(jì)要求來講,大數(shù)據(jù)平臺服務(wù)的整體設(shè)計(jì)要具備全面、全局、權(quán)衡的關(guān)鍵技術(shù)要求,不僅能全面提煉國內(nèi)外優(yōu)秀架構(gòu)和解決方案的精華,而且要理解分布式技術(shù)的底層設(shè)計(jì)思想;不僅能全局了解上下游技術(shù)生態(tài)和業(yè)務(wù)結(jié)合的設(shè)計(jì)過程,而且要游刃有余的處理系統(tǒng)功能和性能問題;不僅能權(quán)衡新技術(shù)引入和改造舊系統(tǒng)的成本估算,而且要推動作戰(zhàn)團(tuán)隊(duì)輕松駕馭新技術(shù)。
- 第一個總體技術(shù)要求:把分布式大數(shù)據(jù)平臺的基礎(chǔ)數(shù)據(jù)服務(wù)能力建設(shè)擺在首位。規(guī)劃出支撐PB級規(guī)模數(shù)據(jù)運(yùn)營能力的創(chuàng)新云平臺架構(gòu),運(yùn)用經(jīng)典設(shè)計(jì)原則和設(shè)計(jì)模式的架構(gòu)之美,吸納業(yè)內(nèi)主流分布式技術(shù)的思想精髓,深耕主流平臺服務(wù)模式到現(xiàn)代微架構(gòu)的演變內(nèi)涵。
- 第二個總體技術(shù)要求:用系統(tǒng)架構(gòu)設(shè)計(jì)和微服務(wù)建設(shè)思想武裝團(tuán)隊(duì),持續(xù)撰寫多維度的架構(gòu)藍(lán)圖,推動團(tuán)隊(duì)協(xié)同作戰(zhàn)。架構(gòu)師不僅要具備大型云平臺架構(gòu)的實(shí)戰(zhàn)經(jīng)驗(yàn)之外,更要有大智慧和戰(zhàn)略思維,通過藍(lán)圖來推動和管理好每一個產(chǎn)品的全生命周期。
- 第三個總體技術(shù)要求:圍繞大數(shù)據(jù)全棧技術(shù)體系解決項(xiàng)目實(shí)戰(zhàn)中的各類難題,制定主流技術(shù)規(guī)范和設(shè)計(jì)標(biāo)準(zhǔn),通過平臺核心組件方式快速迭代出新型業(yè)務(wù)。針對設(shè)計(jì)規(guī)范的重要性,我們不妨用《孫子兵法》的大智慧來分析一下。
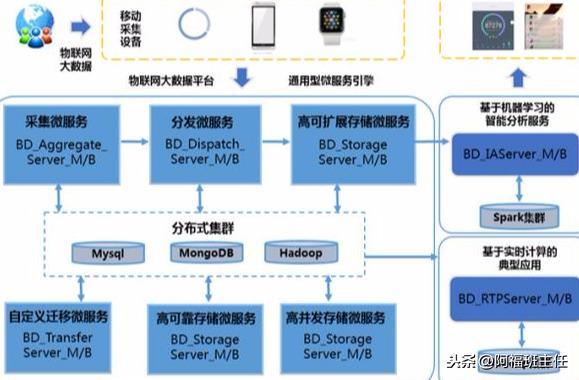
從系統(tǒng)整體技術(shù)能力出發(fā),提出物聯(lián)網(wǎng)大數(shù)據(jù)平臺的八個通用微服務(wù)的技術(shù)要求,包括大數(shù)據(jù)的高并發(fā)采集服務(wù)、靈活分發(fā)服務(wù)、高可擴(kuò)展海量存儲服務(wù)、高并發(fā)展海量存儲服務(wù)、高可靠海量存儲服務(wù)、自定義遷移服務(wù)、基于機(jī)器學(xué)習(xí)的智能分析服務(wù)和基于Spark生態(tài)的實(shí)時計(jì)算服務(wù),具體如下:
高并發(fā)采集服務(wù):
- 支持多種移動終端和物聯(lián)網(wǎng)數(shù)據(jù)的可擴(kuò)展接入,并具備大規(guī)模接入并發(fā)處理能力。能夠兼容主流行業(yè)通用的可擴(kuò)展協(xié)議和規(guī)范,并采用高可靠的集群或者負(fù)載均衡技術(shù)框架來解決。如引入Mina或者Netty技術(shù)框架后適配各種多種移動終端接入。標(biāo)準(zhǔn)化接入要求常用的字節(jié)流、文件、Json等數(shù)據(jù)格式符合主流標(biāo)準(zhǔn)格式。
靈活分發(fā)服務(wù):
- 按照分析應(yīng)用需求,轉(zhuǎn)發(fā)不同的數(shù)據(jù)類型和數(shù)據(jù)格式,交互方式之一是主流的消息中間件MQ或者Kafka,保證高效的轉(zhuǎn)發(fā)并轉(zhuǎn)換數(shù)據(jù)給數(shù)據(jù)服務(wù)運(yùn)營方。交互的方式之二是Restful 方式,保證數(shù)據(jù)可以按照協(xié)議規(guī)范進(jìn)行安全可靠的數(shù)據(jù)轉(zhuǎn)發(fā)和傳輸。
高可擴(kuò)展海量存儲服務(wù):
- 支持?jǐn)?shù)據(jù)類型和數(shù)據(jù)表可擴(kuò)展,對物聯(lián)網(wǎng)大數(shù)據(jù)進(jìn)行海量存儲和計(jì)算,尤其適用于初創(chuàng)公司研發(fā)百萬級用戶之內(nèi)的大數(shù)據(jù)平臺。
高可并發(fā)海量存儲服務(wù):
- 支持?jǐn)?shù)據(jù)類型和數(shù)據(jù)量的高速增長,對物聯(lián)網(wǎng)大數(shù)據(jù)進(jìn)行批處理,適合構(gòu)建PB級數(shù)據(jù)量和千萬級用戶量的云平臺。
高可靠海量存儲服務(wù):
- 支持物聯(lián)網(wǎng)多源異構(gòu)數(shù)據(jù)的統(tǒng)一高效和海量存儲,并提供易于擴(kuò)展的行業(yè)數(shù)據(jù)的離線計(jì)算和批處理架構(gòu),適合構(gòu)建ZB級數(shù)據(jù)量和億級用戶量的分布式大平臺。
基于Spark生態(tài)的實(shí)時計(jì)算服務(wù):
- 支持對物聯(lián)網(wǎng)大數(shù)據(jù)智能分析能力,通過企業(yè)級中間件服務(wù)框架提供安全可靠接口,實(shí)現(xiàn)數(shù)據(jù)實(shí)時統(tǒng)計(jì)和計(jì)算。
基于機(jī)器學(xué)習(xí)的智能分析服務(wù):
- 支持安全高效的機(jī)器學(xué)習(xí)算法,通過支持分布式分類、聚類、關(guān)聯(lián)規(guī)則等算法,為用戶和物聯(lián)網(wǎng)機(jī)構(gòu)提供個性化的智能分析服務(wù)。
自定義遷移服務(wù):
- 支持對物聯(lián)網(wǎng)大數(shù)據(jù)的整體遷移和同步,通過數(shù)據(jù)轉(zhuǎn)換和數(shù)據(jù)遷移工具對不同數(shù)據(jù)類型和數(shù)據(jù)格式進(jìn)行整體遷移,實(shí)現(xiàn)數(shù)據(jù)集的自定義生成。
01高并發(fā)采集微服務(wù)
面對千倍用戶量和萬倍數(shù)據(jù)量的增長速度,如何保證物聯(lián)網(wǎng)大數(shù)據(jù)在比較快的時間內(nèi)進(jìn)入平臺?應(yīng)對用戶量的增長,如何在規(guī)定的時間內(nèi)完成采集?在硬件設(shè)備處理能力之外,讓數(shù)據(jù)更快的匯聚到平臺是核心需求。具體考慮如下:
滿足采集來自不同的廠家、移動設(shè)備類型、傳輸協(xié)議的行業(yè)數(shù)據(jù)的需求。我們在接口設(shè)計(jì)中完全可以針對不同設(shè)備和傳輸協(xié)議來設(shè)計(jì),就是借用“分而治之”的用兵之道,“分而治之” 就是把一個復(fù)雜的算法問題按一定的“分解”方法分為等價(jià)的規(guī)模較小的若干部分,然后逐個解決,分別找出各部分的解,把各部分的解組成整個問題的解,這種樸素的思想也完全適合于技術(shù)設(shè)計(jì),軟件的體系結(jié)構(gòu)設(shè)計(jì)、模塊化設(shè)計(jì)都是分而治之的具體表現(xiàn)。其中策略模式就是這個思想的集中體現(xiàn)。策略模式定義了一個公共接口,各種不同的算法以不同的方式實(shí)現(xiàn)這個接口。
滿足高并發(fā)需求。需要借助消息隊(duì)列、緩存、分布式處理、集群、負(fù)載均衡等核心技術(shù),實(shí)現(xiàn)數(shù)據(jù)的高可靠、高并發(fā)處理,有效降低端到端的數(shù)據(jù)傳輸時延,提升用戶體驗(yàn)。借用“因糧于敵”的思想。“因糧于敵”的精髓是取之于敵,勝之于敵,以戰(zhàn)養(yǎng)戰(zhàn),動態(tài)共存。我們常說的借用對手優(yōu)勢發(fā)展自己并整合資源就是這個思想的集中體現(xiàn)。正式商用的系統(tǒng)需要借助高性能中間件來并行處理數(shù)據(jù),達(dá)到不丟包下的低延遲。我們采用商用的Mina 負(fù)載均衡技術(shù)框架,可以支持多種設(shè)備和傳輸協(xié)議(HTTP、TCP、UDP)的數(shù)據(jù)接入,可以滿足每秒上萬并發(fā)數(shù)的數(shù)據(jù)接入需求。針對以上的核心需求分析和技術(shù)定位,我們可以借助第三方中間件和采用設(shè)計(jì)模式實(shí)現(xiàn)個性化業(yè)務(wù),來解決接口的集中化、可擴(kuò)展性、靈活性等問題,借助Mina的Socket NIO技術(shù)魅力,適配高并發(fā)的數(shù)據(jù)接口IOFilterAdapter進(jìn)行反序列化編碼,適配高并發(fā)的數(shù)據(jù)接口IOHandlerAdapter進(jìn)行業(yè)務(wù)處理。
02 靈活轉(zhuǎn)發(fā)微服務(wù)
靈活轉(zhuǎn)發(fā)能力的總體設(shè)計(jì)中要考慮接口和消息中間件兩種方式,其中消息中間件可支撐千萬級用戶規(guī)模的消息并發(fā),適用于物聯(lián)網(wǎng)、車聯(lián)網(wǎng)、移動 Apps、互動直播等領(lǐng)域。它的應(yīng)用場景包括:
- 一是在傳統(tǒng)的系統(tǒng)架構(gòu),用戶從注冊到跳轉(zhuǎn)成功頁面,中間需要等待系統(tǒng)接口返回?cái)?shù)據(jù)。這不僅影響系統(tǒng)響應(yīng)時間,降低了CPU吞吐量,同時還影響了用戶的體驗(yàn)。
- 二是通過消息中間件實(shí)現(xiàn)業(yè)務(wù)邏輯異步處理,用戶注冊成功后發(fā)送數(shù)據(jù)到消息中間件,再跳轉(zhuǎn)成功頁面,消息發(fā)送的邏輯再由訂閱該消息中間件的其他系統(tǒng)負(fù)責(zé)處理。
- 三是消息中間件的讀寫速度非常的快,其中的耗時可以忽略不計(jì)。通過消息中間件可以處理更多的請求。
主流的消息中間件有Kafka、RabbitMQ、RocketMQ,我們來對比一下它們性能,Kafka是開源的分布式發(fā)布-訂閱消息系統(tǒng),歸屬于Apache頂級項(xiàng)目,主要特點(diǎn)是基于Pull模式來處理消息消費(fèi),追求高吞吐量,主要用于日志收集和傳輸。自從0.8版本開始支持復(fù)制,不支持事務(wù),對消息的重復(fù)、丟失、錯誤沒有嚴(yán)格要求,適合產(chǎn)生大量數(shù)據(jù)的互聯(lián)網(wǎng)服務(wù)的數(shù)據(jù)收集業(yè)務(wù);RabbitMQ是Erlang語言開發(fā)的開源消息隊(duì)列系統(tǒng),基于AMQP協(xié)議來實(shí)現(xiàn)。AMQP的主要特征是面向消息、隊(duì)列、路由(包括點(diǎn)對點(diǎn)和發(fā)布/訂閱)、可靠性、安全。AMQP協(xié)議用在企業(yè)系統(tǒng)內(nèi),對數(shù)據(jù)一致性、穩(wěn)定性和可靠性要求很高的場景,對性能和吞吐量的要求還在其次。RocketMQ是阿里開源的消息中間件,由Java語言開發(fā),具有高吞吐量、高可用性、適合大規(guī)模分布式系統(tǒng)應(yīng)用的特點(diǎn)。RocketMQ設(shè)計(jì)思想源于Kafka,但并不是Kafka的一個Copy,它對消息的可靠傳輸及事務(wù)性做了優(yōu)化,目前在阿里集團(tuán)被廣泛應(yīng)用于交易、充值、流計(jì)算、消息推送、日志流式處理、binglog分發(fā)等場景。結(jié)合上述服務(wù)優(yōu)勢對比,在第三章我們會使用最主流的ActiveMQ消息中間件來處理數(shù)據(jù)轉(zhuǎn)發(fā),在第六章我們采用分布式的Kafka實(shí)現(xiàn)數(shù)據(jù)轉(zhuǎn)發(fā)。
03 高可擴(kuò)展海量存儲服務(wù)
高可擴(kuò)展是大數(shù)據(jù)處理的核心需求之一。實(shí)際工作中,當(dāng)用戶量在100萬以內(nèi),而且數(shù)據(jù)量在TB級別以內(nèi),常常可以選擇用Mysql數(shù)據(jù)庫,靈活、成熟和開源的Mysql數(shù)據(jù)庫是初創(chuàng)公司的首選。我們考慮使用縱表實(shí)現(xiàn)系統(tǒng)靈活可擴(kuò)展,讓經(jīng)常使用的數(shù)據(jù)放在一個數(shù)據(jù)表中,讓靈活變化的字段實(shí)現(xiàn)字典表模式,讓內(nèi)容常發(fā)生變化的數(shù)據(jù)對象盡量采用JSON格式。著名的OpenMRS系統(tǒng)在Mysql數(shù)據(jù)庫中實(shí)現(xiàn)了自定義表格,讓醫(yī)生可以實(shí)現(xiàn)靈活自定義表格,收集自己的臨床試驗(yàn)數(shù)據(jù),讓用戶自己每天可以記錄自己的飲食信息。這樣的設(shè)計(jì)就能實(shí)現(xiàn)了應(yīng)用場景的普適性。我們借鑒OpenMRS的核心思想來構(gòu)建一個基于Mysql的小規(guī)模的物聯(lián)網(wǎng)大數(shù)據(jù)模型。應(yīng)用場景就是:一個患者到多個醫(yī)院,進(jìn)行體檢并記錄了各個生理指標(biāo)。我們根據(jù)應(yīng)用場景來建立數(shù)據(jù)模型。患者表構(gòu)建為Patient表,醫(yī)院表構(gòu)建為Location表,體檢構(gòu)建為Encounter表,測量構(gòu)建為Observation表,體檢類型描述構(gòu)建為Concept表,采用五張表的多表關(guān)聯(lián)實(shí)現(xiàn)了普適的可擴(kuò)展數(shù)據(jù)模型,在第三章節(jié)會詳細(xì)闡述。
高可擴(kuò)展的另外一個接口實(shí)現(xiàn)就是Restful架構(gòu)。Restful接口是安全開放平臺的主流接口風(fēng)格。一般的應(yīng)用系統(tǒng)使用Session進(jìn)行登錄用戶信息的存儲和驗(yàn)證,而大數(shù)據(jù)平臺的開放接口服務(wù)的資源請求則使用Token進(jìn)行登錄用戶信息的驗(yàn)證。Session主要用于保持會話信息,會在客戶端保存一份cookie來保持用戶會話有效性,而Token則只用于登錄用戶的身份鑒權(quán)。所以在移動端使用Token會比使用Session更加簡易并且有更高的安全性。Restful架構(gòu)遵循統(tǒng)一接口原則,統(tǒng)一接口包含了一組受限的預(yù)定義的操作,不論什么樣的資源,都是通過使用相同的接口進(jìn)行資源的訪問。接口應(yīng)該使用預(yù)先定義好的主流的標(biāo)準(zhǔn)的Get/Put/Delete/Post操作等。在第三章節(jié)會詳細(xì)闡述。
04 高并發(fā)海量存儲服務(wù)
MongoDB是適用于垂直行業(yè)應(yīng)用的開源數(shù)據(jù)庫,是我們高并發(fā)存儲和查詢的首選的數(shù)據(jù)庫。MongoDB能夠使企業(yè)業(yè)務(wù)更加具有擴(kuò)展性,通過使用MongoDB來創(chuàng)建新的應(yīng)用,能使團(tuán)隊(duì)提升開發(fā)效率。
我們具體分析一下關(guān)系模型和文檔模型的區(qū)別。關(guān)系模型是按照數(shù)據(jù)對象存到各個相應(yīng)的表里,使用時按照需求進(jìn)行調(diào)取。舉例子來說,針對一個體檢數(shù)據(jù)模型設(shè)計(jì),在用戶管理信息中包括用戶名字、地址、聯(lián)系方式等。按照第三范式,我們會把聯(lián)系方式用單獨(dú)的一個表來存儲,并在顯示用戶信息的時候通過關(guān)聯(lián)方式把需要的信息取回來。但是MongoDB的文檔模式,存儲單位是一個文檔,可以支持?jǐn)?shù)組和嵌套文檔,這個文檔就可以涵蓋這個用戶相關(guān)的所有個人信息,包括聯(lián)系方式。關(guān)系型數(shù)據(jù)庫的關(guān)聯(lián)功能恰恰是它的發(fā)展瓶頸,尤其是用戶數(shù)據(jù)達(dá)到PB級之后,性能和效率會急速下降。
我們采用MongoDB設(shè)計(jì)一個高效的文檔數(shù)據(jù)存儲模式。首先考慮內(nèi)嵌, 把同類型的數(shù)據(jù)放在一個內(nèi)嵌文檔中。內(nèi)嵌文檔和對象可以產(chǎn)生一一映射關(guān)系,比如Map可以實(shí)現(xiàn)存儲一個內(nèi)嵌文檔。如果是多表關(guān)聯(lián)時,可以使用在主表里存儲一個id值,指向另一個表中的 id 值,通過把數(shù)據(jù)存放到兩個集合里實(shí)現(xiàn)多表關(guān)聯(lián), 目前在MongoDB的4.0之后開始支持多文檔的事務(wù)處理。
我們采用AngularJS框架設(shè)計(jì)一個高并發(fā)調(diào)用系統(tǒng)。一提到數(shù)據(jù)調(diào)用就想到了JQuery框架,JQuery框架的設(shè)計(jì)思想就是在靜態(tài)頁面基礎(chǔ)上進(jìn)行DOM元素操作。目前最成熟的數(shù)據(jù)調(diào)用的主流框架之一是AngularJS框架,AngularJS特別適合基于CRUD的Web應(yīng)用系統(tǒng)。它簡化了對Web開發(fā)者的經(jīng)驗(yàn)要求,同時讓W(xué)eb本身變得功能更強(qiáng)。AngularJS對DOM元素操作都是在Directive中實(shí)現(xiàn)的,而且一般情況下很少自己直接去寫DOM操作代碼,只要你監(jiān)聽Model,Model發(fā)生變化后View也會發(fā)生變化。AngularJS框架強(qiáng)調(diào)UI應(yīng)該是用Html聲明式的方式構(gòu)建,數(shù)據(jù)和邏輯由框架提供的機(jī)制自動匹配綁定。AngularJS有著諸多優(yōu)勢的設(shè)計(jì)思想,最為核心的是:數(shù)據(jù)理由、依賴注入、自動化雙向數(shù)據(jù)綁定、語義化標(biāo)簽等。依賴注入思想實(shí)現(xiàn)了分層解耦,包括前后端分離和合理的模塊化組織項(xiàng)目結(jié)構(gòu),讓開發(fā)者更關(guān)注于每一個具體的邏輯本身,從而加快了開發(fā)速度,提升了系統(tǒng)的質(zhì)量。雙向綁定是它的精華所在,就是從界面的操作能實(shí)時反映到數(shù)據(jù),數(shù)據(jù)的變更能實(shí)時展現(xiàn)到界面,數(shù)據(jù)模型Model和視圖View都是綁定在了內(nèi)存映射$Scope上。
下面是我設(shè)計(jì)的AngularJS 的項(xiàng)目框架,可以應(yīng)用于所有業(yè)務(wù)系統(tǒng),在第四章的體檢報(bào)告可視化展示中詳細(xì)闡述。建立MVC的三層框架,先建立一個單頁視圖層Main.html, 然后創(chuàng)建一個模型層Service.js, 最后創(chuàng)建一個控制層App.js, App.js中包括多個模塊的JS和Html文件,這樣就構(gòu)建了一個完整的AngularJS MVC框架。
05 高可靠海量存儲服務(wù)
高可靠海量存儲是大數(shù)據(jù)處理的核心需求之一。實(shí)際工作中,常常需要實(shí)現(xiàn)多模態(tài)、不同時間顆粒度的行業(yè)數(shù)據(jù)的統(tǒng)一高效和海量存儲,并提供易于擴(kuò)展的離線計(jì)算和批處理架構(gòu),例如,引入 Hadoop和Spark的大數(shù)據(jù)存儲與計(jì)算方案。高可靠數(shù)據(jù)海量存儲的總體設(shè)計(jì)中要吸納主流的Hadoop架構(gòu),Hadoop集群是一個能夠讓用戶輕松架構(gòu)和使用的分布式計(jì)算平臺,用戶可以在Hadoop上開發(fā)和運(yùn)行處理海量數(shù)據(jù)的應(yīng)用程序。它主要有以下幾個優(yōu)點(diǎn):
- 高可靠性。Hadoop按列存儲和處理數(shù)據(jù)的能力值得信任。Hadoop能夠在節(jié)點(diǎn)之間動態(tài)地移動數(shù)據(jù),并保證各個節(jié)點(diǎn)的動態(tài)平衡,因此處理速度非常快。
- 高擴(kuò)展性。Hadoop是在可用的列簇中分配數(shù)據(jù)并完成計(jì)算任務(wù)的,這些集簇可以方便地?cái)U(kuò)展到數(shù)以千計(jì)的節(jié)點(diǎn)中。
- 高容錯性。Hadoop能夠自動保存數(shù)據(jù)的多個副本,并且能夠自動將失敗的任務(wù)重新分配。
數(shù)據(jù)海量存儲的彈性設(shè)計(jì)中要吸納主流的HBase架構(gòu)。它是一個高可靠性、高性能、面向列、可伸縮的分布式存儲系統(tǒng),適用于結(jié)構(gòu)化的存儲,底層依賴于Hadoop的HDFS,利用HBase技術(shù)可在廉價(jià)PCServer上搭建起大規(guī)模結(jié)構(gòu)化存儲集群。因此HBase被廣泛使用在大數(shù)據(jù)存儲的解決方案中。從應(yīng)用場景分析,因?yàn)镠Base存儲的是松散的數(shù)據(jù),如果應(yīng)用程序中的數(shù)據(jù)表每一行的結(jié)構(gòu)是有差別的,使用HBase最好,因?yàn)镠Base的列可以動態(tài)增加,并且列為空就不存儲數(shù)據(jù),所以如果你需要經(jīng)常追加字段,且大部分字段是NULL值的,那可以考慮HBase。因?yàn)镠Base可以根據(jù)Rowkey提供高效的查詢,所以你的數(shù)據(jù)都有著同一個主鍵Rowkey。具體實(shí)現(xiàn)見第六章節(jié)。
06 實(shí)時計(jì)算服務(wù)
實(shí)時計(jì)算的總體設(shè)計(jì)中要考慮Spark生態(tài)技術(shù)框架。Spark 使用 Scala 語言進(jìn)行實(shí)現(xiàn),它是一種面向?qū)ο蟆⒑瘮?shù)式編程語言,能夠像操作本地集合對象一樣輕松地操作分布式數(shù)據(jù)集(Scala 提供一個稱為 Actor 的并行模型)。Spark具有運(yùn)行速度快、易用性好、通用性。Spark 是在借鑒了 MapReduce 思想之上發(fā)展而來的,繼承了其分布式并行計(jì)算的優(yōu)點(diǎn)并改進(jìn)了 MapReduce 明顯的缺陷,具體優(yōu)勢分析如下:
Spark 把中間數(shù)據(jù)放到內(nèi)存中,迭代運(yùn)算效率高。MapReduce 中計(jì)算結(jié)果需要落地,保存到磁盤上,這樣勢必會影響整體速度,而 Spark 支持 DAG 圖的分布式并行計(jì)算的編程框架,減少了迭代過程中數(shù)據(jù)的落地,提高了處理效率。
Spark 容錯性高。Spark 引進(jìn)了彈性分布式數(shù)據(jù)集 RDD (Resilient Distributed Dataset) 的抽象,它是分布在一組節(jié)點(diǎn)中的只讀對象集合,這些集合是彈性的,如果數(shù)據(jù)集一部分丟失,則可以根據(jù)“血統(tǒng)“對它們進(jìn)行重建。另外在 RDD 計(jì)算時可以通過 CheckPoint 來實(shí)現(xiàn)容錯。
Spark 具備通用性。在Hadoop 提供了 Map 和 Reduce 兩種操作基礎(chǔ)上,Spark 又提供的很多數(shù)據(jù)集操作類型有,大致分為:Transformations 和 Actions 兩大類。Transformations 包括 Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、oin、Cogroup、MapValues、Sort 和 PartionBy 等多種操作類型,同時還提供 Count, Actions 包括 Collect、 Reduce、Lookup 和 Save 等操作。
強(qiáng)大的SparkMLlib機(jī)器學(xué)習(xí)庫,旨在簡化機(jī)器學(xué)習(xí)的工程實(shí)踐工作,并方便擴(kuò)展到更大規(guī)模。MLlib由一些通用的學(xué)習(xí)算法和工具組成,包括分類、回歸、聚類、協(xié)同過濾、降維等,同時還包括底層的優(yōu)化原語和高層的管道API。具體實(shí)現(xiàn)見第六章節(jié)。
07 基于機(jī)器學(xué)習(xí)的智能分析服務(wù)
智能分析服務(wù)的總體設(shè)計(jì)中要考慮Spark MLlib工具。當(dāng)今主流的建模語言包括R語言,Weka,Mahout和Spark等,我們來分析一下它們的基因和應(yīng)用場景。
R是一種數(shù)學(xué)語言,里面封裝了大量的機(jī)器學(xué)習(xí)算法,但是它是單機(jī)的,不能夠很好的處理海量的數(shù)據(jù)。Weka和R語言類似,里面包含大量經(jīng)過良好優(yōu)化的機(jī)器學(xué)習(xí)和數(shù)據(jù)分析算法,可以處理與格式化數(shù)據(jù)轉(zhuǎn)換相關(guān)的各種任務(wù),唯一的不足就是它對高內(nèi)存要求的大數(shù)據(jù)處理遇到瓶頸。
Mahout是hadoop的一個機(jī)器學(xué)習(xí)庫,有海量數(shù)據(jù)的并發(fā)處理能力,主要的編程模型是MapReduce。而基于MapReduce的機(jī)器學(xué)習(xí)在反復(fù)迭代的過程中會產(chǎn)生大量的磁盤IO,即本次計(jì)算的結(jié)果要作為下一次迭代的輸入,這個過程中只能把中間結(jié)果存儲磁盤,然后在下一次計(jì)算的時候從新讀取,這對于迭代頻發(fā)的算法顯然是致命的性能瓶頸。所以計(jì)算效率很低。現(xiàn)在Mahout已經(jīng)停止更新MapReduce算法,向Spark遷移。另外,Mahout和Spark ML并不是競爭關(guān)系,Mahout是MLlib的補(bǔ)充。
MLlib是Spark對常用的機(jī)器學(xué)習(xí)算法的實(shí)現(xiàn)庫,同時包括相關(guān)的測試和數(shù)據(jù)生成器。Spark的設(shè)計(jì)就是為了支持一些迭代的Job, 這正好符合很多機(jī)器學(xué)習(xí)算法的特點(diǎn)。在邏輯回歸的運(yùn)算場景下,Spark比Hadoop快了100倍以上。Spark MLlib立足于內(nèi)存計(jì)算,適應(yīng)于迭代式計(jì)算。而且Spark提供了一個基于海量數(shù)據(jù)的機(jī)器學(xué)習(xí)庫,它提供了常用機(jī)器學(xué)習(xí)算法的分布式實(shí)現(xiàn),工程師只需要有 Spark基礎(chǔ)并且了解機(jī)器學(xué)習(xí)算法的原理,以及方法中相關(guān)參數(shù)的含義,就可以輕松的通過調(diào)用相應(yīng)的 API 來實(shí)現(xiàn)基于海量數(shù)據(jù)的機(jī)器學(xué)習(xí)過程。
數(shù)據(jù)遷移能力的總體設(shè)計(jì)中要考慮Sqoop框架。Sqoop是一個目前Hadoop和關(guān)系型數(shù)據(jù)庫中的數(shù)據(jù)相互轉(zhuǎn)移的主流工具,可以將一個關(guān)系型數(shù)據(jù)庫(MySQL ,Oracle ,Postgres等)中的數(shù)據(jù)導(dǎo)入到Hadoop的HDFS中,也可以將HDFS的數(shù)據(jù)導(dǎo)入到關(guān)系型數(shù)據(jù)庫中。作為ETL工具,使用元數(shù)據(jù)模型來判斷數(shù)據(jù)類型,并在數(shù)據(jù)從數(shù)據(jù)源轉(zhuǎn)移到Hadoop時確保類型安全的數(shù)據(jù)處理。Sqoop框架可以進(jìn)行大數(shù)據(jù)批量傳輸設(shè)計(jì),能夠分割數(shù)據(jù)集并創(chuàng)建Hadoop任務(wù)來處理每個區(qū)塊。















 京公網(wǎng)安備 11010502049343號
京公網(wǎng)安備 11010502049343號