









經過這么多年的發展,已經從大數據1.0的BI/Datawarehouse時代,經過大數據2.0的Web/APP過渡,進入到了IOT的大數據3.0時代,而隨之而來的是數據架構的變化。
▌Lambda架構
在過去Lambda數據架構成為每一個公司大數據平臺必備的架構,它解決了一個公司大數據批量離線處理和實時數據處理的需求。一個典型的Lambda架構如下:
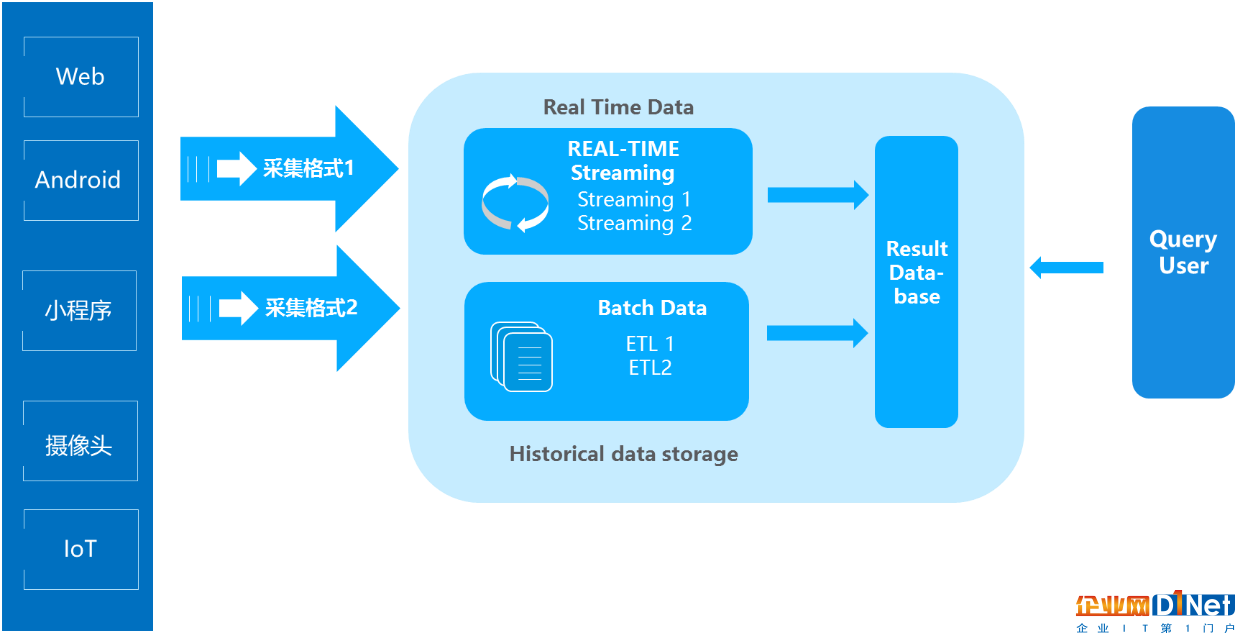
數據從底層的數據源開始,經過各種各樣的格式進入大數據平臺,在大數據平臺中經過Kafka、Flume等數據組件進行收集,然后分成兩條線進行計算。一條線是進入流式計算平臺(例如 Storm、Flink或者Spark Streaming),去計算實時的一些指標;另一條線進入批量數據處理離線計算平臺(例如Mapreduce、Hive,Spark SQL),去計算T+1的相關業務指標,這些指標需要隔日才能看見。
Lambda架構經歷多年的發展,其優點是穩定,對于實時計算部分的計算成本可控,批量處理可以用晚上的時間來整體批量計算,這樣把實時計算和離線計算高峰分開,這種架構支撐了數據行業的早期發展,但是它也有一些致命缺點,并在大數據3.0時代越來越不適應數據分析業務的需求。缺點如下:
實時與批量計算結果不一致引起的數據口徑問題:因為批量和實時計算走的是兩個計算框架和計算程序,算出的結果往往不同,經常看到一個數字當天看是一個數據,第二天看昨天的數據反而發生了變化。
批量計算在計算窗口內無法完成:在IOT時代,數據量級越來越大,經常發現夜間只有4、5個小時的時間窗口,已經無法完成白天20多個小時累計的數據,保證早上上班前準時出數據已成為每個大數據團隊頭疼的問題。
數據源變化都要重新開發,開發周期長:每次數據源的格式變化,業務的邏輯變化都需要針對ETL和Streaming做開發修改,整體開發周期很長,業務反應不夠迅速。
服務器存儲大:數據倉庫的典型設計,會產生大量的中間結果表,造成數據急速膨脹,加大服務器存儲壓力。
▌Kappa架構
針對Lambda架構的需要維護兩套程序等以上缺點,LinkedIn的Jay Kreps結合實際經驗和個人體會提出了Kappa架構。Kappa架構的核心思想是通過改進流計算系統來解決數據全量處理的問題,使得實時計算和批處理過程使用同一套代碼。此外Kappa架構認為只有在有必要的時候才會對歷史數據進行重復計算,而如果需要重復計算時,Kappa架構下可以啟動很多個實例進行重復計算。
一個典型的Kappa架構如下圖所示:
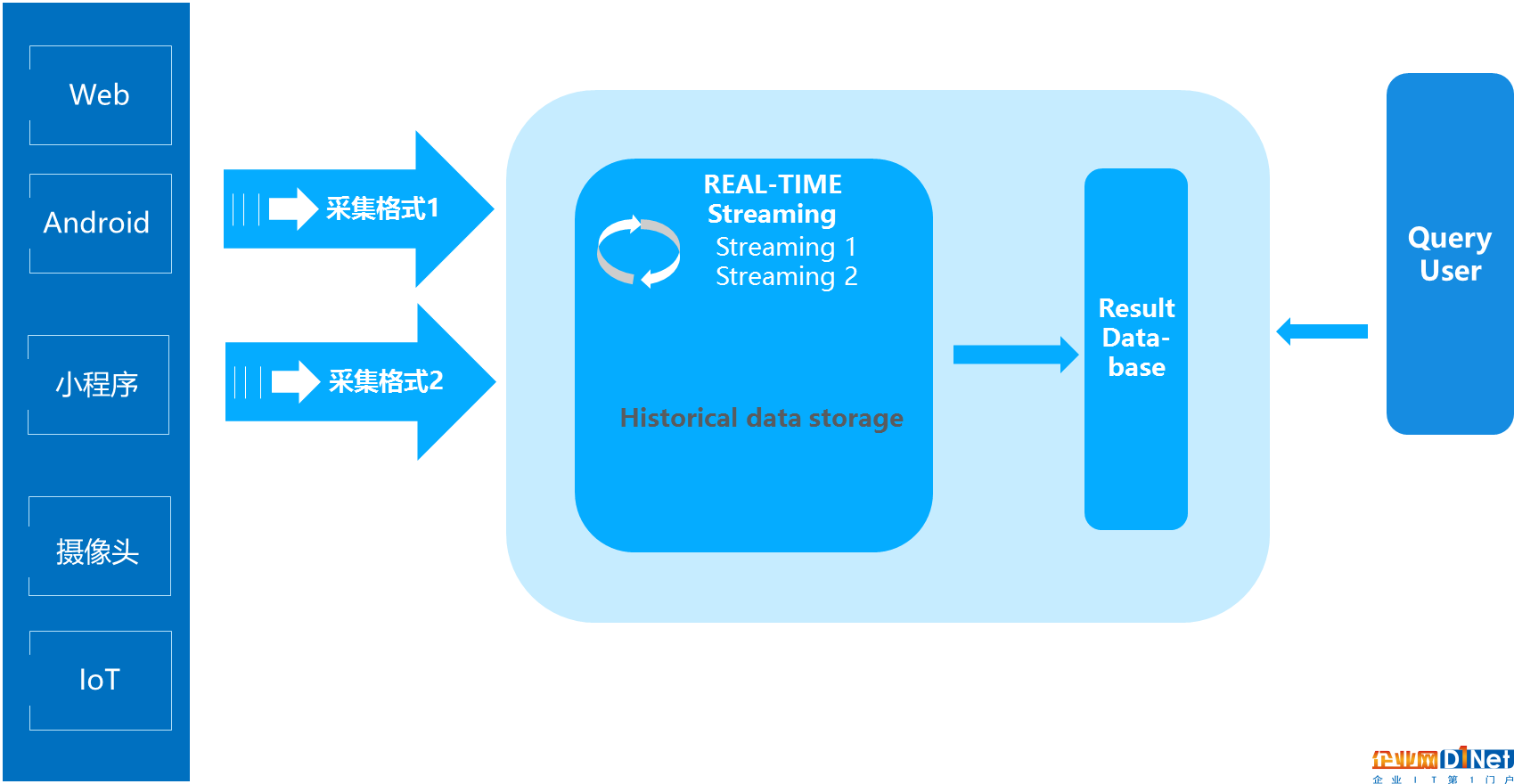
Kappa架構的核心思想,包括以下三點:
1.用Kafka或者類似MQ隊列系統收集各種各樣的數據,你需要幾天的數據量就保存幾天。
2.當需要全量重新計算時,重新起一個流計算實例,從頭開始讀取數據進行處理,并輸出到一個新的結果存儲中。
3.當新的實例做完后,停止老的流計算實例,并把老的一些結果刪除。
Kappa架構的優點在于將實時和離線代碼統一起來,方便維護而且統一了數據口徑的問題。而Kappa的缺點也很明顯:
流式處理對于歷史數據的高吞吐量力不從心:所有的數據都通過流式計算,即便通過加大并發實例數亦很難適應IOT時代對數據查詢響應的即時性要求。
開發周期長:此外Kappa架構下由于采集的數據格式的不統一,每次都需要開發不同的Streaming程序,導致開發周期長。
服務器成本浪費:Kappa架構的核心原理依賴于外部高性能存儲redis,hbase服務。但是這2種系統組件,又并非設計來滿足全量數據存儲設計,對服務器成本嚴重浪費。
▌IOTA架構
而在IOT大潮下,智能手機、PC、智能硬件設備的計算能力越來越強,而業務需求要求數據實時響應需求能力也越來越強,過去傳統的中心化、非實時化數據處理的思路已經不適應現在的大數據分析需求,我提出新一代的大數據IOTA架構來解決上述問題,整體思路是設定標準數據模型,通過邊緣計算技術把所有的計算過程分散在數據產生、計算和查詢過程當中,以統一的數據模型貫穿始終,從而提高整體的預算效率,同時滿足即時計算的需要,可以使用各種Ad-hoc Query來查詢底層數據:
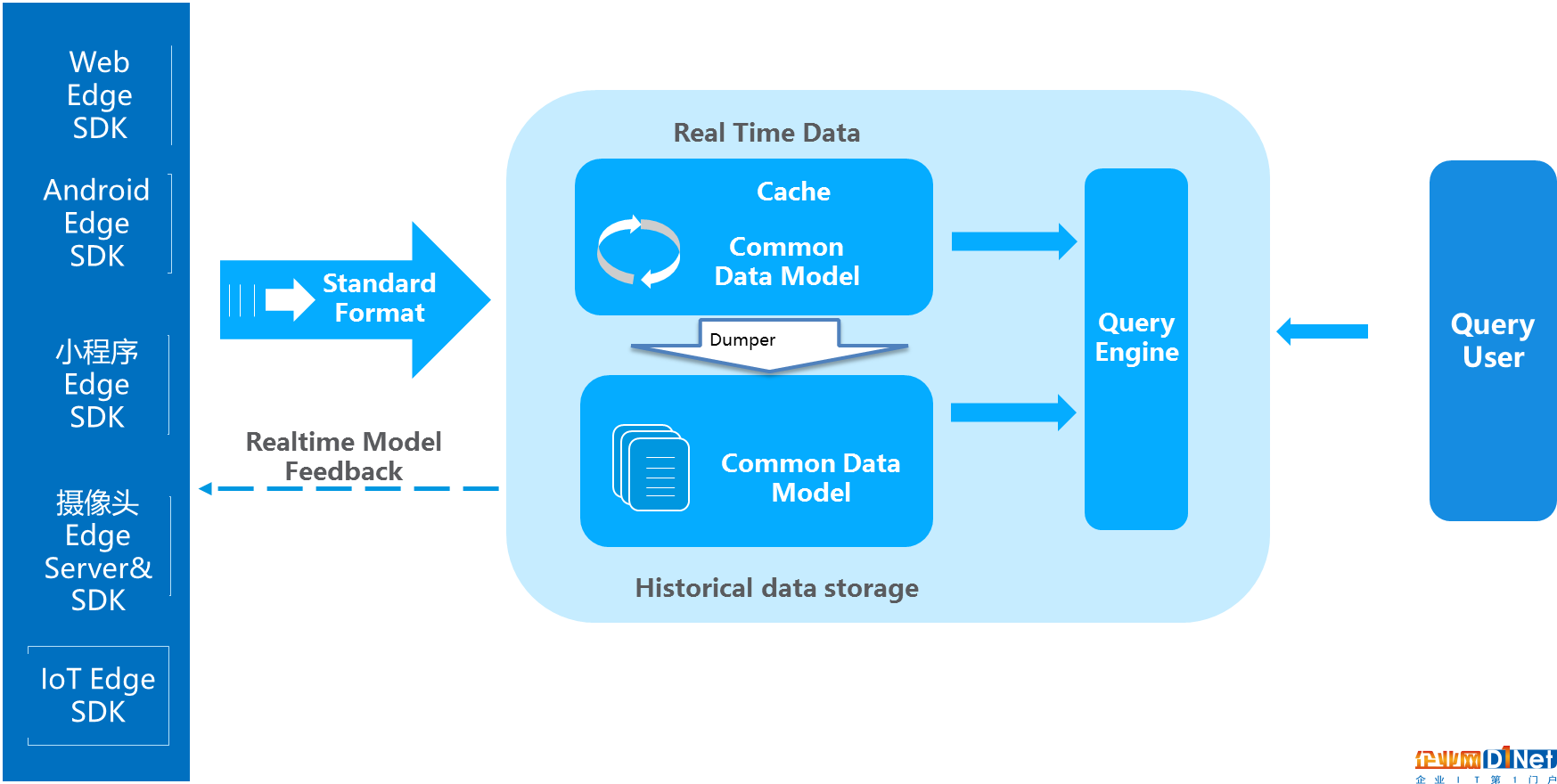
IOTA整體技術結構分為幾部分:
Common Data Model:貫穿整體業務始終的數據模型,這個模型是整個業務的核心,要保持SDK、cache、歷史數據、查詢引擎保持一致。對于用戶數據分析來講可以定義為“主-謂-賓”或者“對象-事件”這樣的抽象模型來滿足各種各樣的查詢。以大家熟悉的APP用戶模型為例,用“主-謂-賓”模型描述就是“X用戶 – 事件1 – A頁面(2018/4/11 20:00) ”。當然,根據業務需求的不同,也可以使用“產品-事件”、“地點-時間”模型等等。模型本身也可以根據協議(例如 protobuf)來實現SDK端定義,中央存儲的方式。此處核心是,從SDK到存儲到處理是統一的一個Common Data Model。
Edge SDKs Edge Servers:這是數據的采集端,不僅僅是過去的簡單的SDK,在復雜的計算情況下,會賦予SDK更復雜的計算,在設備端就轉化為形成統一的數據模型來進行傳送。例如對于智能Wi-Fi采集的數據,從AC端就變為“X用戶的MAC 地址-出現- A樓層(2018/4/11 18:00)”這種主-謂-賓結構,對于攝像頭會通過Edge AI Server,轉化成為“X的Face特征- 進入- A火車站(2018/4/11 20:00)”。也可以是上面提到的簡單的APP或者頁面級別的“X用戶 – 事件1 – A頁面(2018/4/11 20:00) ”,對于APP和H5頁面來講,沒有計算工作量,只要求埋點格式即可。
Real Time Data:實時數據緩存區,這部分是為了達到實時計算的目的,海量數據接收不可能海量實時入歷史數據庫,那樣會出現建立索引延遲、歷史數據碎片文件等問題。因此,有一個實時數據緩存區來存儲最近幾分鐘或者幾秒鐘的數據。這塊可以使用Kudu或者Hbase等組件來實現。這部分數據會通過Dumper來合并到歷史數據當中。此處的數據模型和SDK端數據模型是保持一致的,都是Common Data Model,例如“主-謂-賓”模型。
Historical Data:歷史數據沉浸區,這部分是保存了大量的歷史數據,為了實現Ad-hoc查詢,將自動建立相關索引提高整體歷史數據查詢效率,從而實現秒級復雜查詢百億條數據的反饋。例如可以使用HDFS存儲歷史數據,此處的數據模型依然SDK端數據模型是保持一致的Common Data Model。
Dumper:Dumper的主要工作就是把最近幾秒或者幾分鐘的實時數據,根據匯聚規則、建立索引,存儲到歷史存儲結構當中,可以使用map reduce、C、Scala來撰寫,把相關的數據從Realtime Data區寫入Historical Data區。
Query Engine:查詢引擎,提供統一的對外查詢接口和協議(例如SQL JDBC),把Realtime Data和Historical Data合并到一起查詢,從而實現對于數據實時的Ad-hoc查詢。例如常見的計算引擎可以使用presto、impala、clickhouse等。
Realtime model feedback:通過Edge computing技術,在邊緣端有更多的交互可以做,可以通過在Realtime Data去設定規則來對Edge SDK端進行控制,例如,數據上傳的頻次降低、語音控制的迅速反饋,某些條件和規則的觸發等等。簡單的事件處理,將通過本地的IOT端完成,例如,嫌疑犯的識別現在已經有很多攝像頭本身帶有此功能。
IOTA大數據架構,主要有如下幾個特點:
去ETL化:ETL和相關開發一直是大數據處理的痛點,IOTA架構通過Common Data Model的設計,專注在某一個具體領域的數據計算,從而可以從SDK端開始計算,中央端只做采集、建立索引和查詢,提高整體數據分析的效率。
Ad-hoc即時查詢:鑒于整體的計算流程機制,在手機端、智能IOT事件發生之時,就可以直接傳送到云端進入real time data區,可以被前端的Query Engine來查詢。此時用戶可以使用各種各樣的查詢,直接查到前幾秒發生的事件,而不用在等待ETL或者Streaming的數據研發和處理。
邊緣計算(Edge-Computing):將過去統一到中央進行整體計算,分散到數據產生、存儲和查詢端,數據產生既符合Common Data Model。同時,也給與Realtime model feedback,讓客戶端傳送數據的同時馬上進行反饋,而不需要所有事件都要到中央端處理之后再進行下發。
如上圖,IOTA架構有各種各樣的實現方法,為了驗證IOTA架構,易觀也自主設計并實現了“秒算”引擎,目前支持易觀內部月活5.5億設備端進行計算的同時,也基于“秒算”引擎研發出了可以獨立部署在企業客戶內,進行數字用戶分析和營銷的“易觀方舟”,可以訪問ark.analysys.cn進行體驗。
在大數據3.0時代,Lambda大數據架構已經無法滿足企業用戶日常大數據分析和精益運營的需要,去ETL化的IOTA大數據架構才是未來。
















 京公網安備 11010502049343號
京公網安備 11010502049343號