


摘要:通過對數據處理階段性發展的解析,分析大數據、人工智能技術的發展趨勢。結合實際生產需求,驗證了基于容器云架構的新一代大數據與人工智能平臺在數據分析、處理、挖掘等方面的強大優勢。
關鍵詞:大數據 人工智能 云計算 Docker 基礎能力 多租戶
Abstract:Through analyzing the staged development of data processing, this paper analyzes the development trend of big data and AI technology. According to the requirement of customers, the new generation of big data and AI platform based on Docker Cloud verify the powerful advantages in data analysis, processing, mining and so on.
Key Words:Big data; AI; cloud computing; Docker;basic abilities; Multi-tenant
引言
人工智能、大數據與云計算三者有著密不可分的聯系。人工智能從1956年開始發展,在大數據技術出現之前已經發展了數十年,幾起幾落,但當遇到了大數據與分布式技術的發展,解決了計算力和訓練數據量的問題,開始產生巨大的生產價值;同時,大數據技術通過將傳統機器學習算法分布式實現,向人工智能領域延伸;此外,隨著數據不斷匯聚在一個平臺,企業大數據基礎平臺服務各個部門以及分支機構的需求越來越迫切。通過容器技術,在容器云平臺上構建大數據與人工智能基礎公共能力,結合多租戶技術賦能業務部門的方式將人工智能、大數據與云計算進行融合。
數據處理的發展階段
隨著信息技術的蓬勃發展,特別是近十年,移動互聯技術的普及,運營商、泛金融、政府、大型央企、大型國企、能源等領域數據量更是呈現幾何級數的增長趨勢。數據量的膨脹除了帶來了數據處理性能的壓力外,數據種類的多樣性也為數據處理手段提出了新的要求,大量新系統的建設同時產生了眾多數據孤島,給企業的數據運營維護與價值發掘帶來了重大的挑戰。隨著大數據技術的不斷發展,企業的數據處理技術轉型也經歷了幾個階段,如圖1所示。
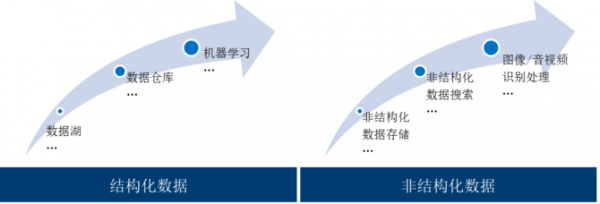
▲圖1 企業數據處理轉型的階段變化
在第一階段,大數據技術發展的早期,為了打破數據孤島,將各類數據向大數據平臺匯集,形成數據湖的概念,作為多源、異構的數據的數據歸集,在此基礎上進行數據標準化,建立企業數據的匯聚中心。在這個階段,對非結構化數據處理以存儲檢索為主,對結構化數據處理提供各類API和少量SQL支持,使海量的以SQL實現為主的業務難以遷移到大數據平臺,新業務開發使用門檻高,大數據技術的推廣受到阻礙。
在第二階段,企業客戶的需求集中表現為,如何更好地處理結構化數據以及將老的IT架構遷移到分布式架構中。各大數據平臺廠商開始在SQL on Hadoop領域進行研發和競爭,不斷提高SQL標準的兼容程度。在這個過程中,Spark誕生并逐漸取代了過于笨重且TB量級計算性能存在缺陷的MapReduce架構,Hadoop技術開始向結構化數據處理分析更深度的應用領域進發。隨著SQL on Hadoop技術的不斷發展與星環科技解決了Hadoop分布式事務的難題,越來越多的客戶在Hadoop上構建新一代數據倉庫,將Hadoop技術應用于越來越多的業務生產場景,技術門檻的降低,使越來越多的客戶可以利用強大的分布式計算能力輕松分析處理海量數據。在這個階段后期,隨著企業客戶對實時數據分析研判需求的不斷提高,流處理技術得以蓬勃發展。
在第三階段,一部分企業已經完成了由基于關系型數據庫為核心的數據處理體系向基于大數據技術為核心的數據處理體系的轉變。在本階段早期,很多企業客戶不滿足于通過SQL基于統計對數據的分析和挖掘,促使傳統的機器學習算法開始實現分布化,但主要還是針對結構化數據的學習挖掘。隨著深度學習技術和分布式技術的碰撞,演化出了新一代的計算框架,如TensorFlow等,計算能力的提升,并結合大量訓練數據,使機器學習人工智能技術在結構化與非結構化數據領域產生巨大威力,開始應用于人臉識別、車輛識別、智能客服、無人駕駛等領域;同時,對傳統機器學習算法產生了巨大沖擊,一定程度上減少了對特征工程與業務領域知識的依賴,降低了機器學習的進入門檻,使人工智能技術得以普及。另一方面,可視化的拖拽頁面、豐富的行業模板、高效率的交互式體驗,極大地降低了數據分析人員的使用門檻,讓人工智能技術進一步走入企業的生產應用。
大數據、人工智能與云技術的融合
隨著企業內部對于數據資源的應用不再僅僅局限于IT部門,越來越多的內部項目組與分支機構加入大數據平臺的使用中,加之數據處理技術的不斷發展,如何解決基礎平臺的資源隔離問題、管理分配問題、編排調度問題;如何將企業業務應用需要的基礎服務能力做更好地抽象,降低應用所需的基礎服務的環境搭建、開發、測試部署周期,提升IT支撐效能;如何更好地管理眾多的基于大數據與人工智能開發的應用等等成為企業急需解決的問題。
在大數據技術發展的早期,僅僅是在計算框架MapReduce中提供簡單的作業調度算法,隨著資源管理的需求,在Hadoop 2.0時代,Yarn作為單獨組件負責分布式計算框架的資源管理。但是,一方面,Yarn僅僅能夠管理調度計算框架的資源;另一方面,資源的管理粒度較為粗放,不能做到有效的資源隔離,越來越不能滿足企業客戶的需求。
云計算技術作為資源隔離封裝虛擬化,以及管理調度的技術,本應應用于解決上述問題。但是,在Docker容器技術被廣泛接受之前,云計算虛擬化技術主要基于虛擬機封裝資源,并在其之上加載操作系統,資源利用率低,早期有廠商嘗試將大數據平臺構建在基于虛擬機技術的云化方案上,由于資源利用和穩定性問題,在私有云上的嘗試鮮有成功案例。在公有云方面,借助公有云較為強大的基礎平臺硬件與運維支持能力,有一些非核心業務的應用嘗試。
隨著Docker、Kubernetes等容器技術的發展,與微服務等技術概念的形成,大數據與人工智能基礎平臺開始基于容器云構建底層資源管理與調度平臺。容器云就像一個分布式的操作系統,將集群中的各類硬件資源進行封裝、管理以及調度,將封裝的資源作為容器承載大數據的相關組件進程,再將這些容器進行編排,組成一個個的大數據和人工智能的基礎服務,如分布式文件系統HDFS、NoSQL數據庫Hbase、分布式分析型數據庫Inceptor、分布式流處理平臺Slipstream、分布式機器學習組件Sophon等。由這些基礎服務編排構建公共能力服務層,提供如數據倉庫、數據集市、圖數據庫、全文搜索數據庫、流處理服務、NoSQL數據庫、機器學習平臺服務、定制圖像識別服務等,為企業打造全新的數據處理核心系統。基于這一核心系統服務于各類企業的不同部門。通過資源隔離技術,通過對每個租戶的資源分配和權限管理,滿足業務分析人員的個性化分析需求,專注于業務邏輯的開發和數據的分析挖掘。
技術融合的應用
中國郵政大數據平臺建設以Transwarp Data Hub(以下簡稱TDH)與Transwarp Operating System(以下簡稱TOS)作為基礎架構系統,搭建的新一代邏輯數據倉庫和數據集市,完全取代了Teradata和Oracle.
總體架構與實現
中國郵政大數據平臺服務于量收、郵務、名址等系統,同時運用容器云TOS實現創新多租戶的數據分析挖掘環境。建立從業務層到管理層到決策層的智能分析體系,模擬量化風險和收益,實現對郵政各種業務數據進行分類、管理、統計和分析等功能,給各級管理人員提供各類準確的統計分析預測數據,使其能夠及時掌握全面的經營狀況,為宏觀決策提供支持;為省分公司基層業務人員提供詳盡的數據,供其對各自的工作目標、當前和歷史狀況進行準確的把握,對業務活動進行有效支撐,滿足郵政經營分析管理及決策支持。
中國郵政大數據平臺以五大基礎服務集群域為基礎,分別是數據湖集群域、企業數據倉庫集群域、省分服務集群域、機器學習實驗室集群域、開發/測試/培訓集群域。
(1)數據湖集群域:基于TDH平臺搭建的數據湖,主要承擔多源異構的數據歸集,數據湖內包括:原始數據池、清洗加工數據池、整合加工數據池等。
(2)企業數倉集群域:基于TDH搭架的數據倉庫集群,基于大數據創新搭架邏輯數據倉庫,用于遷移改造原有基于Teradata搭架的數據倉庫,數據集市和基于Oracle搭建的報刊集市的郵政量收管理系統。
(3)省分服務集群域:基于TOS搭建容器化多租戶數據分析平臺云。為省、市分公司開發人員和業務人員提供省分多租戶的平臺環境,集團分發數據與自有數據存儲計算,自有應用的開發與管理,獨立租戶使用運行。
(4)機器學習實驗室集群域:基于TOS搭建的容器化多租戶大數據機器學習平臺,為集團數據中心分析師提供多租戶的開發實驗環境平臺,進行數據探查、業務建模、算法研究、應用開發、成果推廣等。
(5)開發/測試/培訓集群域:為應用開發人員、系統測試人員、培訓師、學員提供多租戶的大數據與機器學習平臺,為開發商及內部單位提供開發測試培訓服務。
以此為基礎,達到了數據管理、服務管理、運維管控、安全管控四個維度的統一。在風險管控、決策支持、服務支撐、流程優化、品牌創新、交叉營銷六大應用領域展開應用。實現了租戶管理、數據治理、數據加工、數據挖掘、數據探索、數據展現六大平臺功能。
數據湖和數據倉庫基于TDH構建,將包括業務系統數據、實時流數據、合作單位數據、互聯網數據等不同數據源,通過ESB接入、ETL工具、Kafka、Sqoop、文本上傳、人工接入等方式,統一匯聚進入數據湖。加工后獲得的數據資產發布到數據資產目錄,通過數據資產目錄的構建TDH與TOS用戶間數據交互體系。便于用戶快速檢索數據,通過數據資產目錄實現對數據的集成、融合、安全、共享。數據資產目錄包括:元數據、主數據、數據安全、數據標準、數據質量、數據輪廓、數據生命周期等。此外,企業用戶通過大數據門戶按需申請租戶存儲計算資源、數據資源、審批流程通過后,集群資源管理員按需快速部署集群,自動化將數據從數據湖加載入數據分析集群或省分集群對應的租戶空間,供數據開發人員使用。數據開發人員會將數據應用成果固化到數據湖內,對外提供數據服務。
數據倉庫與數據集市的完整遷移
中國郵政大數據平臺是全球首個采用Hadoop(TDH)技術完全取代Teradata和Oracle的混合架構搭建新一代邏輯數據倉庫和數據集市的系統。
原量收系統使用Teradata的數據倉庫和Oracle的數據庫,數據使用空間目前已接近30TB,現有使用用戶約5萬人,提供近約900張報表的靈活查詢,單日報表查詢頻次最高能達到40萬次,月初高峰查詢需支持約2000計算查詢并發。
通過項目前期大量調研準備工作,制定了切實可行的項目實施方案。量收管理系統的總體架構、ESB、BI工具、ETL工具、調度工具、門戶等都保持不變,僅將原量收系統的數據倉庫和數據集市,使用大數據平臺進行完全替換,降低了整個遷移風險。
整個遷移過程中,包括環境部署、模型遷移改造、接口遷移改造、數據遷移、ETL遷移改造、報表遷移改造、數據核對、性能優化、業務應用遷移、風險控制,系統測試等。例如模型遷移改造,不改變原有業務邏輯,只需對接口層模型,基礎層模型、匯總層模型進行輕度改造。對于模型改造來說,系統基礎層模型結構相對復雜,關聯度相對較高,原系統使用Teradata數據庫。TDH全面兼容Teradata的數據類型與SQL方言,降低了遷移成本。同時遷移完成后,性能大幅提升,見圖2.
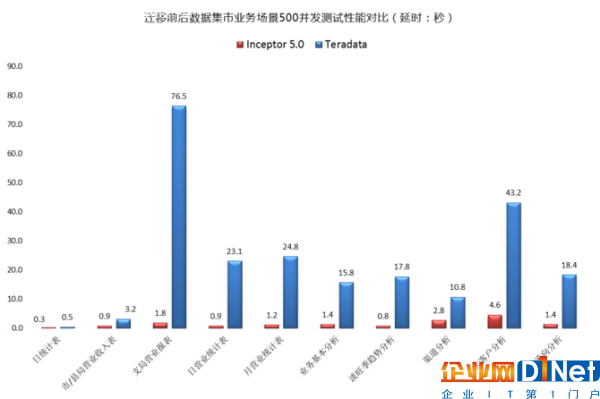
▲圖2 遷移前后數據集市業務場景500并發測試性能對比
基于容器云的大數據與機器學習平臺的全面應用
基于TOS實現的多租戶新模式,將大數據與機器學習平臺組件完全容器化實現,并在TOS提供能力服務。集團統一部署企業內部云平臺,對郵政各個租戶(集團、省分、市局等)動態分配存儲、計算、網絡等資源,并實現完整的資源隔離,使得各個租戶數據分析人員和業務人員獲得相對獨立的資源環境,賦能業務創新,同時可動態調配資源,實現資源的共享優勢。
集團、省分、市局各級人員通過多租戶平臺,實現資源發布、申請,使用及應用開發、成果推廣。通過項目立項申請審批后,省分項目組人員在租戶空間內,接入訪問數據資源,使用平臺服務資源,大數據分析工具及機器學習挖掘工具展開數據分析挖掘工作,具體開展數據處理、模型開發、算法應用、應用發布等,在審批驗收之后,將成果推廣到數據湖上部署對全集團提供數據應用服務。
通過TOS+TDH搭架厚平臺、薄應用的微服務架構,實現租戶之間的異構性、獨立測試與部署、資源按需伸縮、高性能計算能力、租戶間錯誤問題隔離、團隊全功能化。實現數據資產化管理。面對集團數據多樣、海量、跨板塊、跨專業的需求,集團對數據進行了全面梳理,創新集成各版塊、專業數據,創建數據資產目錄便于快速檢索獲取資產,管控治理資產,讓數據即資產從理論階段上升到實現階段。
結語
隨著企業數據處理與服務需求的不斷發展,由大數據的匯聚,分布式技術釋放計算能力開始,技術不斷延伸發展,大數據、人工智能與云計算的邊界越來越模糊,三者技術的發展不斷互相影響與融合,這是發展與需求產生的自然趨勢。在“后大數據時代”,基礎大數據與人工智能云平臺的形成與落地會越來越多,真正實現科技賦能業務,為企業提升效率與發展提供更強的心臟。同時,未來可以看到,企業可能會將其基于基礎能力平臺的應用體系也上架到平臺的應用市場中,充分利用云平臺的優勢能力,資源共享,統一管理。








 京公網安備 11010502049343號
京公網安備 11010502049343號