









2001年,Gartner給出了大數據的概念,即大數據是需要新處理模式才能具有更強的決策力、洞察發現力和流程優化能力來適應海量、高增長率和多樣化的信息資產。這其中點出了大數據關鍵的3V特征,即海量、速度和多樣性,也很明確的為我們指出了大數據在哪些方面存在挑戰。但是,16年過去了,現在大數據發展仍然沒有達到邊界,還是一個充滿想象力的領域。
因為數據的存在,讓很多新的行業煥發出了無限的價值,社交媒體網站可能就是一個典型的例子。對于企業來說,目前的主要問題就是如何使用收集來的數據創造價值。為此,Dzone社區調查了734個和大數據相關的技術人員,下面我們就來看看有哪些有趣的結論。
開源仍然是大趨勢
開源是整個IT技術的大趨勢,在大數據領域也不例外。據Dzone的相關調查,71% 的受訪者都在使用開源工具進行數據科學的相關工作,只有16%的人在使用商業工具。開源工具在個人開發項目和企業應用程序中得到了快速應用。
2016年曝光度最高的開源工具Spark,今年的采用率從去年的31%增長到了45%。而今年曝光率最高的開源工具,TensorFlow絕對算得上一號,自谷歌一年半之前發布以來TensorFlow的采用率已經達到17%。
開源工具的出現讓大數據的應用推進的更快,如果不能快速適應上手新的開源工具,那么關于數據科學的相關工具就無法開展。
Apache Hadoop仍然是領頭羊
前幾天,有的專家在預測數據庫未來發展趨勢時,提出了一個觀點那就是“Hadoop將死”,但是通過具體的數據,我們發現Apache Hadoop現在仍然有實力強勁。65%的數據工程師都正在使用或者曾經使用過Apache Hadoop。47%的技術人員使用Yarn進行集群管理。62%使用Apache ZooKeeper,55%使用Hive來做數據倉儲。
得益于MapReduce處理和存儲數據的能力,自2011年發布以來,Apache Hadoop就一直呈現著高速發展的趨勢,現在廣受歡迎的眾多先進工具都是建立在Hadoop之上。對于開發者和數據科學家來說,Hadoop是一盞明燈,有助于他們在未來職業中的晉升。
當然,為了克服MapReduce的局限性,Apache Spark應運而生,同時還衍生出一些其他的新技術,例如 Spark SQL、GraphX、 MLib和 Spark Stream等等。
數據庫的發展
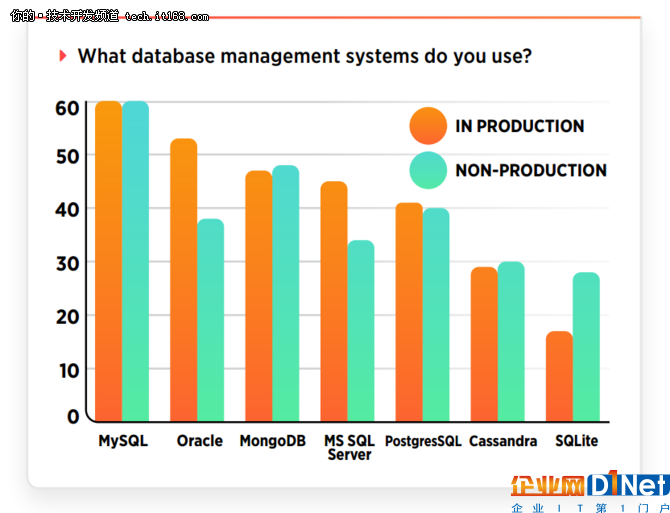
關于數據庫的發展,今年并沒有大格局的變化。據Dzone的調查,MySQL被60%的受訪者應用于生產和非生產的環境中。MongoDB被47%的受訪者應用于生產環境中,48%應用于非生產環境中,PostgreSQL被41%的受訪者應用于生產環境中和40%應用于非生產環境中。
而商業數據庫可能是由于許可證的問題,似乎并不如開源數據庫那么受歡迎。而其他一些數據庫,例如SQLite這樣輕量級的數據庫也會占據一定的份額。但是NoSQL數據庫的發展則越來越穩健,有56%的數據科學從業人員選擇使用NoSQL。
編程語言、工具、庫和框架

數據科學其實很大程度上都依賴開源的編程語言、工具、庫和框架。就編程語言來說,Python和R都是數據科學的熱門語言。相比較于R語言來說,Python可能更受歡迎一些,其在受訪者中獲得了63%的支持,而R語言則獲得了61%的支持。
而對于框架來說,Spark Stream在流數據計算框架中頗受歡迎,在數據采集過程中Kafka得到了54%的支持。剩余其它的一些框架則沒有得到超過25%的支持率,不過,這其中還有一匹黑馬,那就是GraphX,其在迭代圖處理類別中獲得了24%的支持率。
















 京公網安備 11010502049343號
京公網安備 11010502049343號