









編者按
隨著隱私成為大數據應用領域的焦點,百度安全實驗室的安全專家孫茗珅和韋韜專門撰寫了一個隱私保護技術方面的綜述。本文介紹了學術界和工業界對于用戶隱私保護的努力成果,其中主要講到了k-anonymity(k-匿名化)、l-diversity(l-多樣化)、t-closeness和ε-differential privacy(差分隱私),并對它們的優缺點進行了分析。
大數據時代下的隱私保護
數據和隱私
在大數據的時代,數據成為了科學研究的基石。人們在享受著推薦算法、語音識別、圖像識別、無人車駕駛等智能的技術帶來的便利的同時,數據在背后擔任著驅動算法不斷優化迭代的角色。在科學研究、產品開發、數據公開的過程中,算法需要收集、使用用戶數據,在這過程中數據就不可避免地暴露在外。歷史上就有很多公開的數據暴露了用戶隱私的案例。
美國在線(AOL)是一家美國互聯網服務公司,也是美國最大的互聯網提供商之一。2006年8月,為了學術研究,AOL公開了匿名的搜索記錄,其中包括65萬個用戶的數據,總共20M條查詢記錄。在這些數據中,用戶的姓名被替換成了一個個匿名的ID,但是《紐約時報》通過這些搜索記錄,找到了ID匿名為4417749的用戶在真實世界中對應的人。ID4417749的搜索記錄里有關于“60歲的老年人”的問題、
“Lilburn地方的風景”、還有“Arnold”的搜索字樣。通過上面幾條數據,紐約時報發現Lilburn只有14個人姓Arnold,最后經過直接聯系這14個人確認ID4417749是一位62歲名字叫Thelma Arnold的老奶奶。最后AOL緊急撤下數據,發表聲明致歉,但是已經太晚了。因為隱私泄露事件,AOL遭到了起訴,最終賠償受影響用戶總額高達五百萬美元。
同樣是2006年,美國最大的影視公司之一——Netflix,舉辦了一個預測算法的比賽(Netflix Prize),比賽要求在公開數據上推測用戶的電影評分。Netflix把數據中唯一識別用戶的信息抹去,認為這樣就能保證用戶的隱私。但是在2007年來自The University of Texasat Austin的兩位研究人員表示通過關聯Netflix公開的數據和IMDb(互聯網電影數據庫)網站上公開的記錄就能夠識別出匿名后用戶的身份。三年后,在2010年,Netflix最后因為隱私原因宣布停止這項比賽,并因此受到高額罰款,賠償金額總計九百萬美元。近幾年各大公司均持續關注用戶的隱私安全。例如蘋果在2016年6月份的WWDC大會上就提出了一項名為DifferentialPrivacy的差分隱私技術。蘋果聲稱他能通過數據計算出用戶群體的行為模式,但是卻無法獲得每個用戶個體的數據。那么差分隱私技術又是怎么做的呢?在大數據時代,如何才能保證我們的隱私呢?
隱私保護的方法
從信息時代開始,關于隱私保護的研究就開始了。隨著數據不斷地增長,人們對隱私越來越重視。我們在討論隱私保護的時候包括兩種情況。
第一種是公司為了學術研究和數據交流開放用戶數據,學術機構或者個人可以向數據庫發起查詢請求,公司返回對應的數據時需要保證用戶的隱私。
第二種情況是公司作為服務提供商,為了提高服務質量,主動收集用戶的數據,這些在客戶端上收集的數據也需要保證隱私性。學術界提出了多種保護隱私的方法和測量隱私是否泄露的工具,例如k-anonymity(k-匿名化)、l-diversity(l-多樣化)、t-closeness、ε-differential privacy(差分隱私)、同態加密(homomorphic encryption)、零知識證明(zero-knowledge proof)等等。今天主要介紹k-anonymity(k-匿名化),l-diversity(l-多樣化),t-closeness和ε-differential privacy(差分隱私)。這些方法先從直觀的角度去衡量一個公開數據的隱私性,再到使用密碼學、統計學等工具保證數據的隱私性。
下面我們一一解讀這四種隱私保護的方法:
k-anonymity(k-匿名化)
k-anonymity是在1998年由Latanya Sweeney和Pierangela Samarati提出的一種數據匿名化方法。
先看一下表1,我們把表格中的公開屬性分為以下三類:
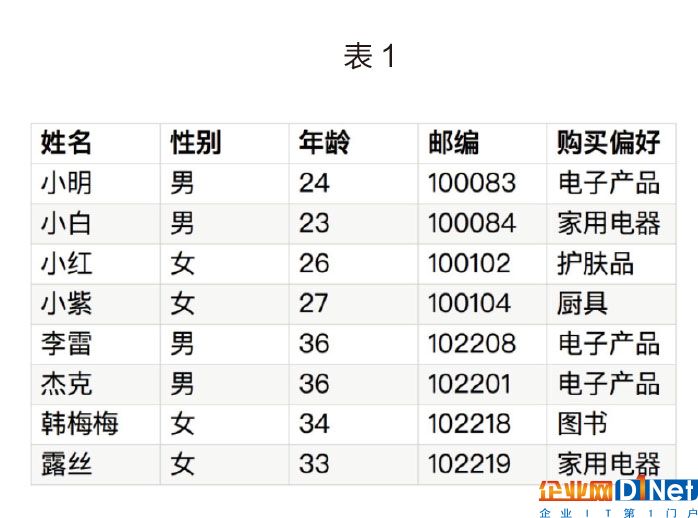
Key attributes:一般是個體的唯一標示,比如說姓名、地址、電話等等,這些內容需要在公開數據的時候刪掉。
Quasi-identifier:類似郵編、年齡、生日、性別等不是唯一的,但是能幫助研究人員關聯相關數據的標示。
Sensitive attributes:敏感數據,比如說購買偏好、薪水等等,這些數據是研究人員最關心的,所以一般都直接公開。
簡單來說,k-anonymity的目的是保證公開的數據中包含的個人信息至少k-1條不能通過其他個人信息確定出來。也就是公開數據中的任意quasi-identifier信息,相同的組合都需要出現至少k次。
舉個例子,假設一個公開的數據進行了2-anonymity保護。如果攻擊者想確認一個人(小明)的敏感信息(購買偏好),通過查詢他的年齡、郵編和性別,攻擊者會發現數據里至少有兩個人是有相同的年齡、郵編和性別。這樣攻擊者就沒辦法區分這兩條數據到底哪個是小明了,從而也就保證了小明的隱私不會被泄露。
表2就是2-anonymization過的信息:
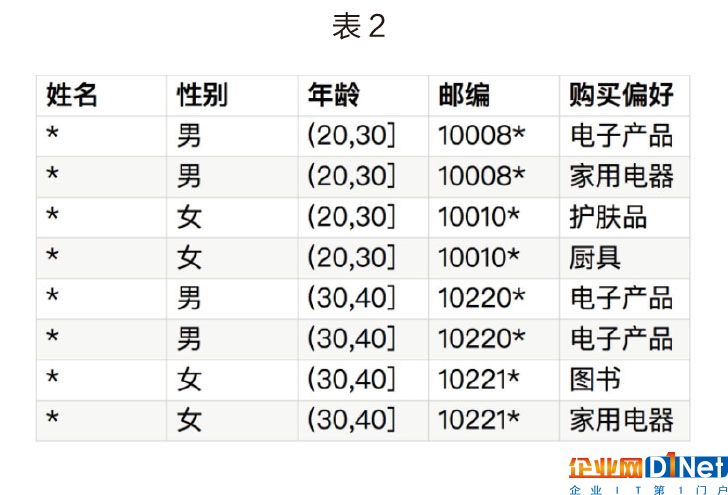
k-anonymity的方法主要有兩種,一種是刪除對應的數據列,用星號(*)代替。另外一種方法是用概括的方法使之無法區分,比如把年齡這個數字概括成一個年齡段。對于郵編這樣的數據,如果刪除所有郵編,研究人員會失去很多有意義的信息,所以可以選擇刪除最后一位數字。
從這個表中,即使我們知道小明是男性、24歲、郵編是100083,卻仍然無法知道小明的購買偏好。而研究人員依然可以根據這些數據統計出一些有意義的結果,這樣既兼顧了個人的隱私,又能為研究提供有效的數據。
k-anonymity能保證以下三點:
1.攻擊者無法知道某個人是否在公開的數據中。
2.給定一個人,攻擊者無法確認他是否有某項敏感屬性。
3.攻擊者無法確認某條數據對應的是哪個人(這條假設攻擊者除了quasi-identifier信息之外對其他數據一無所知,舉個例子,如果所有用戶的偏好都是購買電子產品,那么k-anonymity也無法保證隱私沒有泄露)。
未排序匹配攻擊(unsorted matching attack):當公開的數據記錄和原始記錄的順序一樣的時候,攻擊者可以猜出匿名化的記錄是屬于誰。例如如果攻擊者知道在數據中小明是排在小白前面,那么他就可以確認,小明的購買偏好是電子產品,小白是家用電器。解決方法也很簡單,在公開數據之前先打亂原始數據的順序就可以避免這類的攻擊。
補充數據攻擊(complementary release attack):假如公開的數據有多種類型,如果它們的k-anonymity方法不同,那么攻擊者可以通過關聯多種數據推測用戶信息。
除此之外,如果敏感屬性在同一類quasi-identifiers中缺乏多樣性,或者攻擊者有其它的背景知識,k-anonymity也無法避免隱私泄露。
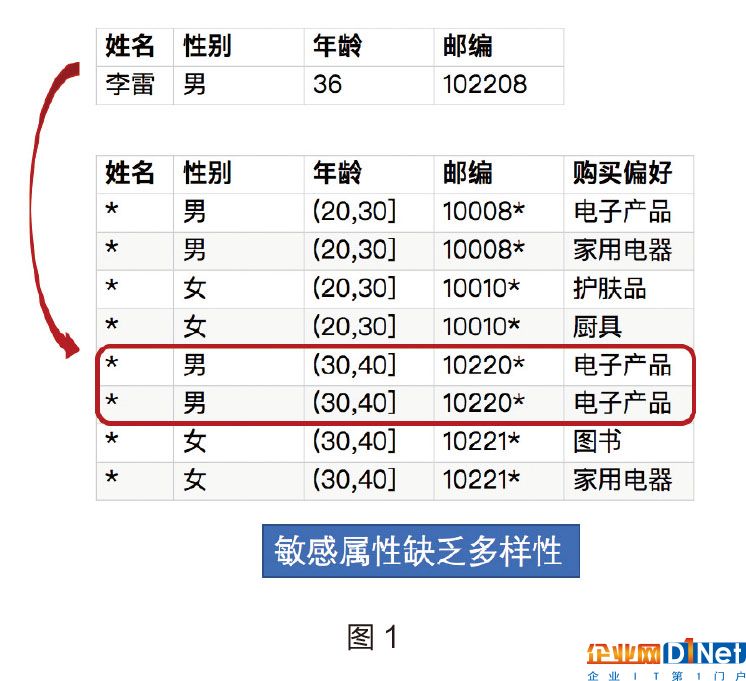
我們知道李雷的信息,圖1中有兩條對應的數據,但是他們的購買偏好都是電子產品。因為這個敏感屬性缺乏多樣性,所以盡管是2-anonimity匿名化的數據,我們依然能夠獲得李雷的敏感信息。
如果我們知道小紫的信息,并且知道她不喜歡購買護膚品,那么從圖2中,我們仍可以確認小紫的購買偏好是廚具。
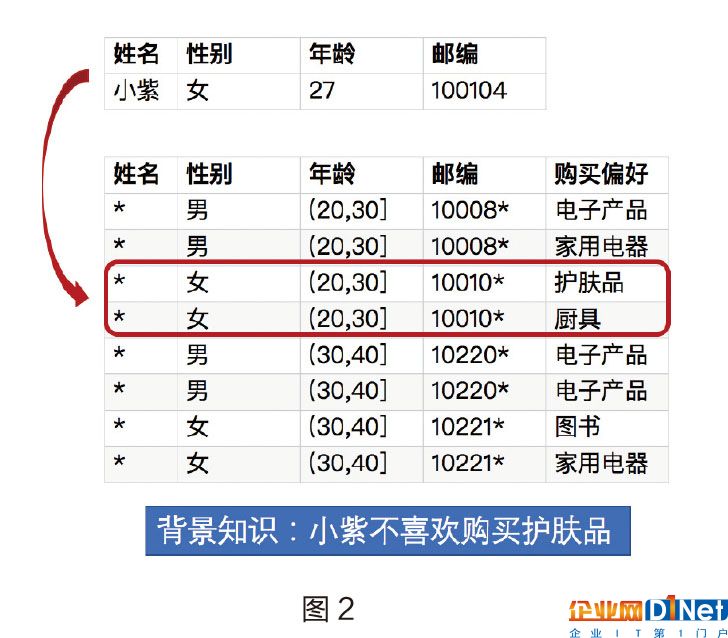
l-diversity(l-多樣化)
通過上面的例子,我們引出了多樣化的概念。簡單來說,在公開的數據中,對于那些quasi-identifier相同的數據中,敏感屬性必須具有多樣性,這樣才能保證用戶的隱私不能通過背景知識等方法推測出來。
l-diversity保證了相同類型數據中至少有l種內容不同的敏感屬性。
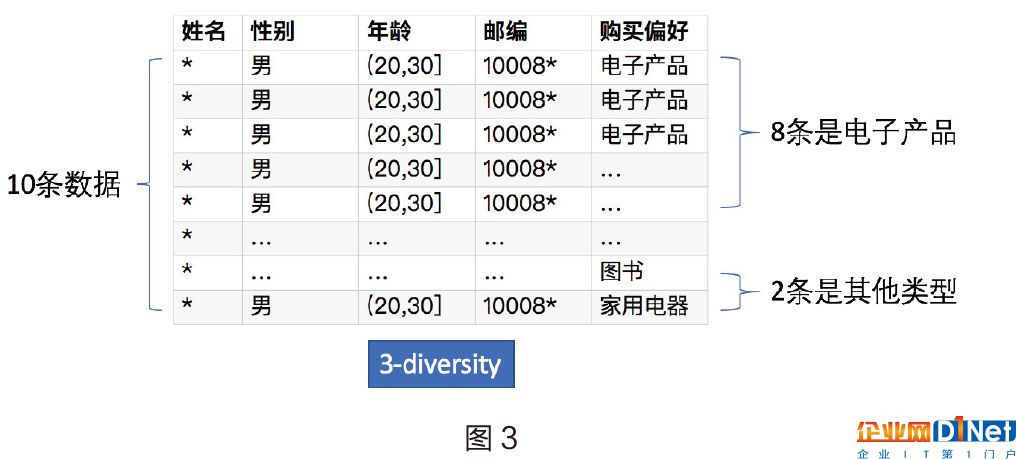
例如在圖3的例子中,有10條相同的類型的數據,其中8條的購買偏好是電子產品,其他兩條分別是圖書和家用電器。那么在這個例子中,公開的數據就滿足3-diversity的屬性。
除了以上介紹的簡單l-diversity的定義,還有其他版本的l-diversity,引入了其他統計方法。比如說:
基于概率的l-diversity(probabilistic l-diversity):在一個類型中出現頻率最高的值的概率不大于1/l。
基于墑的l-diversity(entropy l-diversity):在一個類型中敏感數據分布的墑至少是log(l)。
遞歸(c,l)-diversity(recursive(c,l)-diversity):簡單來說就是保證最經常出現的值的出現頻率不要太高。
l-diversity也有其局限性:
敏感屬性的性質決定即使保證了一定概率的diversity也很容易泄露隱私。例如,醫院公開的艾滋病數據中,敏感屬性是“艾滋病陽性”(出現概率是1%)和“艾滋病陰性”(出現概率是99%),這兩種值的敏感性不同,造成的結果也不同。
有些情況下l-diversity是沒有意義的:比如說艾滋病數據的例子中僅含有兩種不同的值,保證2-diversity也是沒有意義的。
l-diversity很難達成:例如,我們想在10000條數據中保證2-diversity,那么可能最多需要10000×0.01=100個相同的類型。這時可能通過之前介紹的k-anonymity的方法很難達到。
偏斜性攻擊(Skewness Attack):假如我們要保證在同一類型的數據中出現“艾滋病陽性”和出現“艾滋病陰性”的概率是相同的,我們雖然保證了diversity,但是我們泄露隱私的可能性會變大。因為l-diversity并沒有考慮敏感屬性的總體的分布。
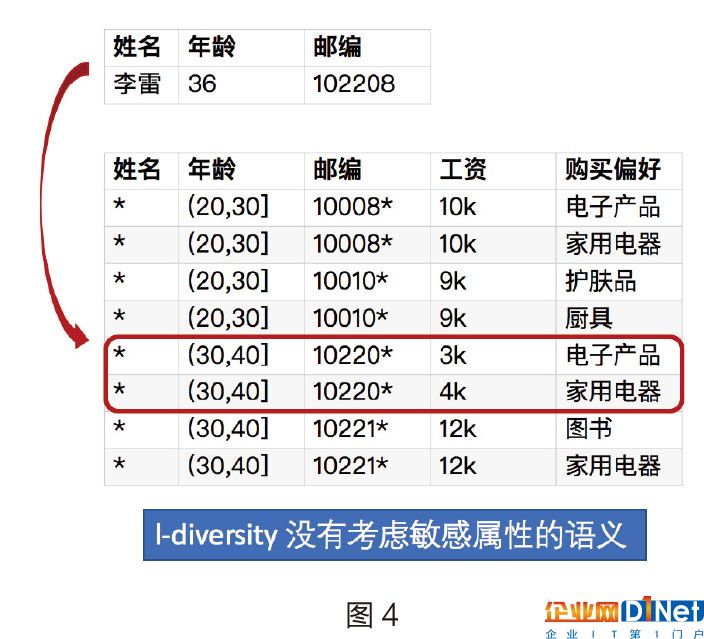
l-diversity沒有考慮敏感屬性的語義,比
如說下面圖4的例子,我們通過李雷的信息從公開數據中關聯到了兩條信息,通過這兩條信息我們能得出兩個結論。第一,李雷的工資相對較低;第二,李雷喜歡買電子電器相關的產品。
t-closeness
上面最后一個問題就引出了t-closeness的概念,t-closeness是為了保證在相同的quasi-identifier類型組中,敏感信息的分布情況與整個數據的敏感信息分布情況接近(close),不超過閾值t。
如果剛才的那個數據保證了t-closeness屬性,那么通過李雷的信息查詢出來的結果中,工資的分布就和整體的分布類似,進而很難推斷出李雷工資的高低。
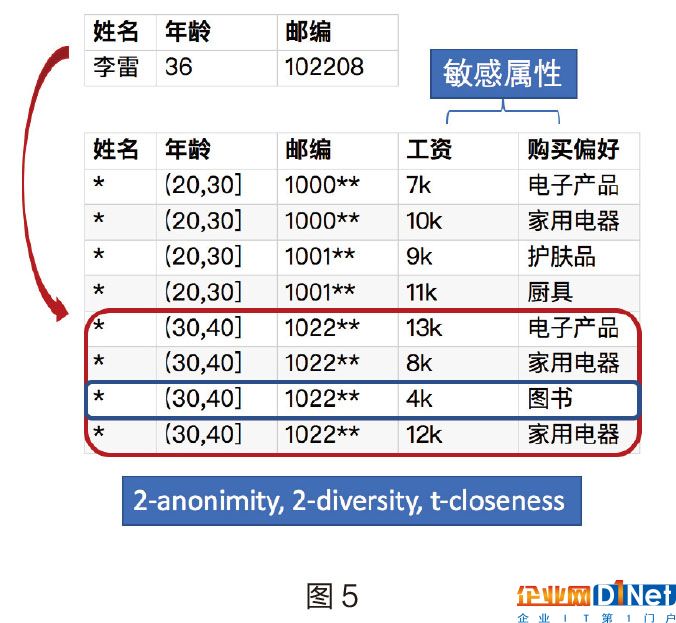
最后,如果保證了k-anonymity,l-diversity和t-closeness,隱私就不會泄露了么?答案并不是這樣,我們看圖5的例子,在這個例子中,我們保證了2-anonymity,2-diversity,t-closeness(分布近似),工資和購買偏好是敏感屬性。攻擊者通過李雷的個人信息找到了四條數據,同時知道李雷有很多書,這樣就能很容易在四條數據中找到李雷的那一條,從而造成隱私泄露。可能有些讀者會有疑問,通過背景知識攻擊k-anonymity的前提是不是假設了解quasi-identifier?并不是這樣,針對敏感屬性的背景攻擊對k-anonymity也適用,所以無論經過哪些屬性保證,隱私泄露還是很難避免。
差分隱私(differentialprivacy)
除了之前我們介紹的針對k-anonymity,l-diversity,t-closeness三種隱私保護方法的攻擊之外,還有一種叫做差分攻擊(differential attack)。舉個例子,購物公司發布了購物偏好的數據,說我們有100個人的購物偏好數據,其中有10個人偏愛購買汽車用品,其他90個偏愛購買電子產品。如果攻擊者知道其中99個人是偏愛汽車用品還是電子產品,就可以知道第100個人的購物偏好。這樣通過比較公開數據和既有的知識推測出個人隱私,就叫做差分攻擊。
在2009年,微軟研究院的CynthiaDwork提出差分隱私的概念,差分隱私就是為了防止差分攻擊,也就是說盡管攻擊者知道發布的100個人的個人以信息和其中99個人的信息,他也沒辦法通過比對這兩個信息獲得第100個人的信息。
簡單來說,差分隱私就是用一種方法使得查詢100個信息和查詢其中99個的信息得到的結果是相對一致的,那么攻擊者就無法通過比較(差分)數據的不同找出第100個人的信息。這種方法就是加入隨機性,如果查詢100個記錄和99個記錄,輸出同樣的值的概率是一樣的,攻擊者就無法進行差分攻擊。進一步說,對于差別只有一條記錄的兩個數據集D和D‘(neighboring datasets),查詢他們獲得結果相同的概率非常接近。注意,這里并不能保證概率相同,如果一樣的話,數據就需要完全的隨機化,那樣公開數據也就沒有意義。所以,我們需要盡可能接近,保證在隱私和可用性之間找到一個平衡。
ε-差分隱私(ε-differential privacy,ε-DP)可以用下面圖6的定義來表示:

其中M是在D上做任意查詢操作,對查詢后的結果加入一定的隨機性,也就是給數據加噪音,兩個datasets加上同一隨機噪音之后查詢結果為C的概率比小于一個特定的數。這樣就能保證用戶隱私泄露的概率有一個數學的上界,相比傳統的k-anonymity,差分隱私使隱私保護的模型更加清晰。
我們用圖7的例子解釋差分隱私的定義:圖7中D1和D2是兩個neighboring datasets,他們只有一條記錄不一致,在攻擊者查詢“20-30歲之間有多少人偏好購買電子產品”的時候,對于這兩個數據庫得到的查詢結果是100的概率分別是99%和98%,他們的比值小于某個數。如果對于任意的查詢,都能滿足這樣的條件,我們就可以說這種隨機方法是滿足ε-差分隱私的。因為D1和D2是可以互換的,所以更加嚴格地講,他們的比值也要大于e-ε。
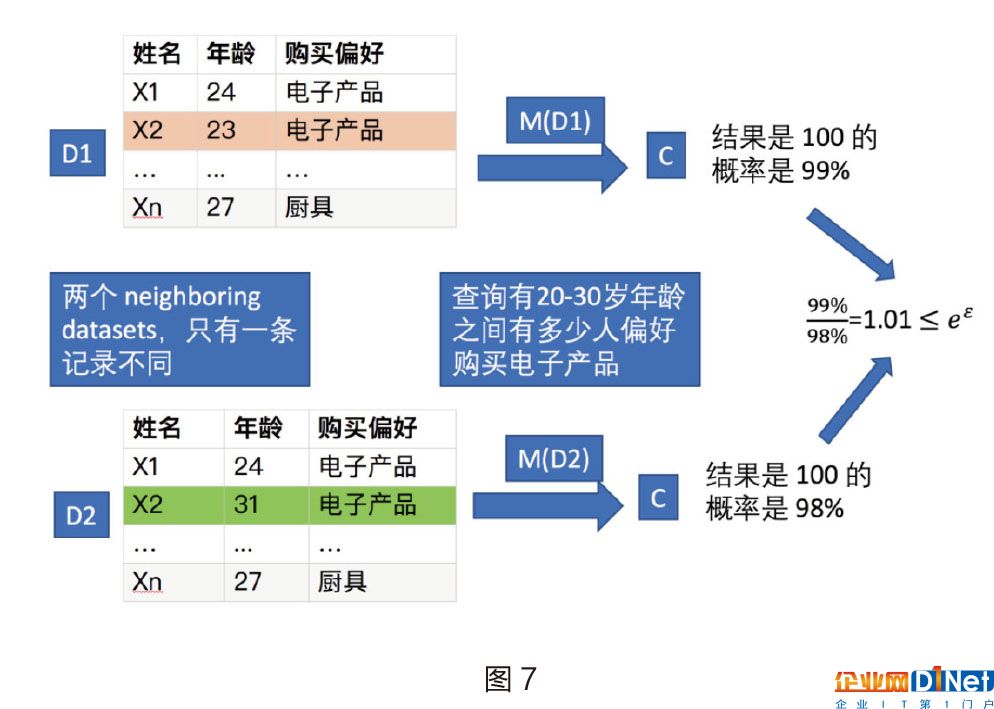
無論查詢是什么,兩個相鄰的數據庫返回的結果總是近似的。
要達到數據的差分隱私有四種方法:
1.輸出結果變換
2.輸入查詢變換
3.中間值變換
4.抽樣和聚合數據
本文接下來主要介紹輸出結果變換的方法,這種方法主要針對查詢結果是數值或者數值向量的情況,通過加入噪聲使輸出結果達到ε-DP。
輸出結果變換:加入噪聲
在差分隱私中,防止隱私泄露的重要因素是在查詢結果中加噪音,對于數值的查詢結果,一種常見的方法就是對結果進行數值變換。要解釋如何加入噪音,我們先看一下圖8的這個例子:假如某公司公開了數據,并且對外提供了查詢數據的接口f(x),針對不同的查詢x,服務器都會輸出一個查詢結果f(x)+噪聲,加入噪聲就是為了保證ε-差分隱私。
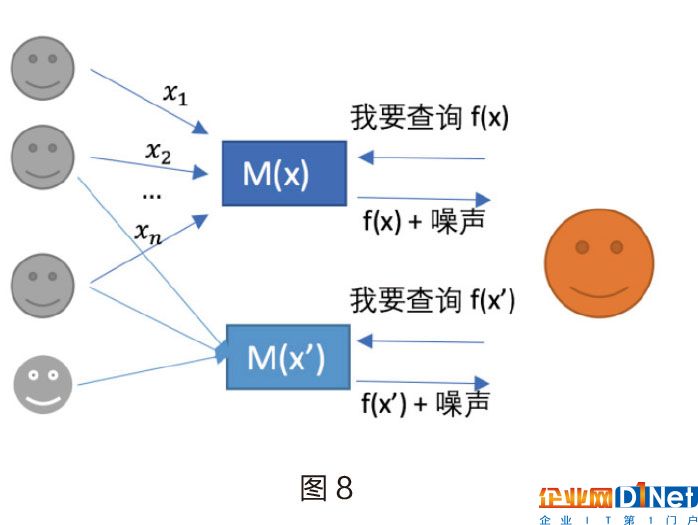
那么如何選擇噪聲呢?
差分隱私方法中,作者巧妙地利用了拉普拉斯分布的特性,找到了合適的噪聲方法。針對數值或向量的查詢輸出,M(x)=f(x)+噪聲。我們能得出以下結論:

我們有了這個結論,想要對某個查詢接口f(x)保證ε-DP的話,只需要在查詢結果上加入Lap(GS/e)的噪聲就可以了。
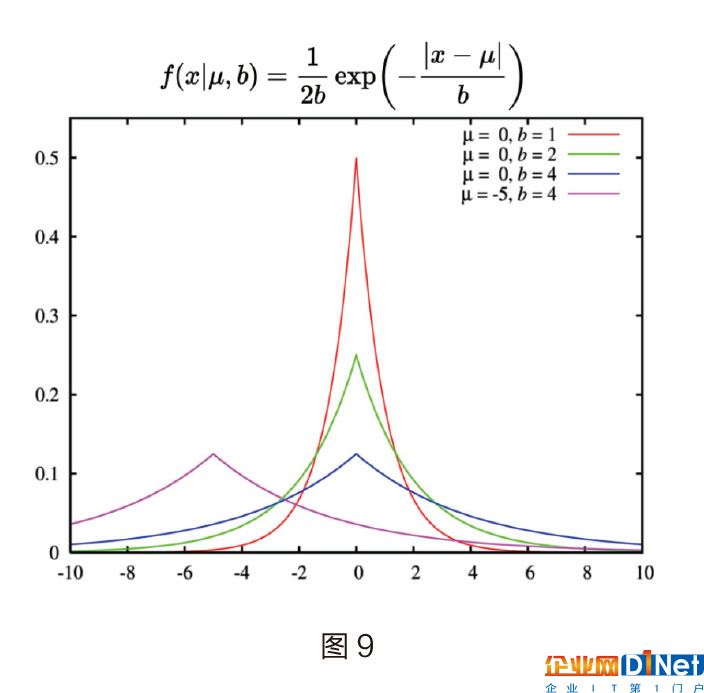
拉普拉斯分布和其概率密度函數如圖9:
(ε,δ)-differential privacy,(ε,δ)-DPε-DP是一種“嚴格”的隱私保護保證,當在數據庫中添加和刪除一條數據時候,保證所有查詢的輸出都類似。但是(ε,δ)-DP在ε-DP的保證中允許了一定概率的錯誤發生,比如說,用戶在(ε,δ)-DP的保護下會有δ概率的隱私泄露。

基于這些的概念,差分隱私在機器學習算法中也能夠使用,常見的算法,比如說PCA、logisticregression、SVM都有對應的差分隱私化算法。
差分隱私在數據的實用性和隱私性之間達到了平衡,使用者可以通過設定自己的“隱私預算”(privacy budget)來調整數據的實用性和隱私性。但是差分隱私也不是萬能的,其中加入噪聲的很多算法需要在大量的數據集上才實用。除此之外,什么才是“隱私預算”的合理設定也是一個問題。這些都是差分隱私面臨的問題和挑戰。并且由于差分隱私對于“背景知識”的要求過于強,所以需要在結果中加入大量隨機化,導致數據的可用性(utility)急劇下降。但是差分隱私作為一個非常優雅的數學工具,是隱私保護的研究在未來的一個發展方向。差分隱私用嚴格的數學證明告訴人們一個匿名化的公開數據究竟能保護用戶多少的隱私。
k-匿名化與ε-差分隱私的關系
我們前面分別單獨介紹了k-匿名化和ε-差分隱私,k-匿名化相對比較容易理解和實踐,差分隱私更像是從理論上證明了隱私保護的邊界。雖然方法的分析角度完全不同,但是它們之間卻有著緊密的聯系。普渡大學的NinghuiLi教授在Provably Private Data Anonymization:Or,k-Anonymity Meets Differential Privacy文章中詳細分析了k-匿名化和ε-差分隱私之間的關系。文章證明了在使用k-匿名化“得當”的情況下,可以滿足一定條件的(ε,δ)-differentialprivacy。同時也提出了一種k-anonymity的變形:β-Sampling+Data-independent_Generalization+k-Suppression(k,β)-SDGS,通過變形后的k-anonymity就可以使之滿足差分隱私。通過使用差分隱私這種工具,我們就能精確地衡量前人提出的k-anonymity,這在理論研究上具有重要意義。
總結
本文介紹了學術界和工業界對于用戶隱私保護的努力成果。首先介紹了k-anonymity,即通過變換隱私數據,保證相同特性的用戶在數據庫出現的次數至少是k次。然后,為了防止攻擊者通過隱私數據的背景知識推測用戶身份,提出使用l-diversity,保證相同特征的用戶中,隱私數據相同的個數大于l。除此之外,我們也討論了t-closeness。最后詳細介紹了差分隱私的概念,以及實際應用中應如何使用差分隱私。
從最開始的k-anonymity,l-diversity,t-closeness到現在的ε-差分隱私,都是為了既保證用戶的個人隱私,也能對實際應用和研究提供有價值的數據。在大數據的時代中,希望各公司在利用數據提供更好的服務的同時,能保護好用戶的個人隱私。這是法律的要求,也是安全行業的追求。我們相信隱私保護技術會越來越受到重視,并從學術理論迅速投入工業界實戰應用(責編:楊潔)
(作者單位為百度安全實驗室)
參考文章
1.https://www.cis.upenn.edu/~aaroth/Papers/privacybook.
2..https://www.cs.cmu.edu/~yuxiangw/docs/Differential%20Privacy.pdf
3.https://blog.cryptographyengineering.com/2016/06/15/what-is-differential-privacy/
4.https://www.chromium.org/developers/design-documents/rappor
5.http://static.googleusercontent.com/media/research.google.com/en/us/pubs/archive/42852.pdf
6.ProvablyPrivateDataAnonymization:Or,k-AnonymityMeetsDifferentialPrivacy
















 京公網安備 11010502049343號
京公網安備 11010502049343號