


編譯|薛命燈
編輯|Natalie
從 2006 年開源 Hadoop 開始,Yahoo(也就是現在的 Oath)為廣大開發者社區的大數據基礎設施做出了不可磨滅的貢獻。現在,我們又邁出了堅實的一步,Yahoo 的大數據處理和服務引擎 Vespa 正式在 GitHub 上開源了( https://github.com/vespa-engine)。
越來越多的應用程序需要處理大量的數據,盡管開發者可以使用 Hadoop 來存儲和批處理數據,也可以使用 Storm 來處理流式數據,但這些技術無法直接服務于最終用戶。提供大規模服務是一項巨大的挑戰,當用戶需要等待基于大量數據集的計算結果時,比如特征搜索、推薦系統、定制化,這種挑戰就會變得尤為明顯。
有了 Vespa,開發者可以輕松地構建基于大數據集實時計算結果的應用,而到目前為止,只有少數幾個大公司具備這樣的能力。
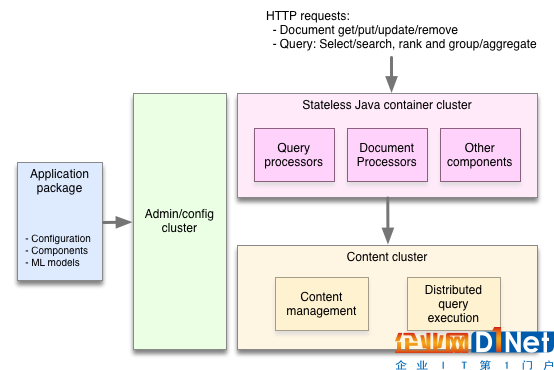
提供服務不是簡單地根據 ID 查詢項目或應用模型計算出幾個數字,很多提供服務的應用需要基于大數據集運行計算,比如搜索和推薦。為了給用戶返回精確的搜索結果或推薦清單,應用程序需要找出所有符合查詢條件的項目,根據相關度或推薦模型決定每一個項目的匹配程度,移除重復項目,增加瀏覽輔助項,最后把結果返回給用戶。因為這些計算依賴用戶的具體請求,所以無法預先計算。應用程序必須實時地處理用戶請求,而且要快,因為用戶在等待結果。在大數據集上快速執行上述操作需要很多基礎設施的支持——分布式算法、數據分布和管理、高效的數據結構和內存管理等等。而這些正是 Vespa 要為開發者提供的——一個一站式的引擎,簡潔易用。
我們已經在 Oath 的多個產品上使用了 Vespa,包括 Yahoo.com、Yahoo News、Yahoo Sports、Yahoo Finance、Yahoo Gemini、Flickr 等。我們使用 Vespa 來處理每日數十億個用戶請求,為用戶返回基于數十億文檔得出的搜索結果和推薦內容,并提供定制化內容和廣告。事實上,Vespa 每秒可以處理 90,000 次內容和廣告請求,延遲通常只有幾十毫秒。在 Flickr 上,Vespa 每秒可以處理數百個基于數百億張圖片的關鍵字和圖像搜索。另外,Vespa 在 Yahoo Gemini 上每天處理 30 億個請求,高峰時段每秒鐘 140,000 個請求,直接給公司帶來可觀的收益。
我們基于 Vespa 構建的應用具備如下特性:
使用 SQL 風格的查詢和文本搜索來過濾內容
基于匹配項生成數據驅動的頁面
根據人工或機器學習相關度模型對匹配進行排名
毫秒級的處理響應時間
實時寫入數據,每個節點每秒鐘寫入數千次
在運行服務的同時進行伸縮和重配置
為了保證速度和伸縮性,Vespa 在多臺機器上分布數據和計算任務,避免了單點 master 的瓶頸。傳統的應用將數據拉取到一個無狀態的層上進行處理,而 Vespa 是將計算任務推送給數據集。為此,Vespa 需要做很多非常棘手的工作,比如當機器發生故障或增加新機器時在后臺重新分布數據、實現分布式的低延遲和處理算法、處理分布式數據一致性等。
我們在構建 alltheweb.com(后被 Yahoo 收購)時就開始開發我們的搜索和服務。在過去幾年中,我們不斷使用新技術重寫我們的引擎。Vespa 是我們發布過的項目當中涉及范圍最廣、代碼量最大的一個項目。Vespa 已經在 Yahoo 的大部分關鍵系統上得到了實地驗證,所以我們很高興能夠把 Vespa 推向世界。
Vespa 賦予了開發者將任意大小數據集和模型填充進服務系統的能力,而且可以實時地得到計算結果,帶來更好的用戶體驗,而且成本更低,比預計算方式具有更低的復雜度。而且,開發者可以與復雜的計算展開實時的交互,不需要啟動離線作業或反復回過頭來檢查結果。
Vespa 可以運行在自有數據中心或云端。我們提供了 Vespa 的 Docker 鏡像和 rpm 安裝包,也提供了運行指南,可以讓 Vespa 運行在本地機器或 AWS 集群上。
這個(http://docs.vespa.ai/ )是我們的文檔,里面包含了一個入門指南。
管理分布式系統不是件簡單的事情。我們投入了大量精力開發 Vespa,其他開發者就可以專注在創建功能上,他們可以實現基于大數據集的實時計算,而不是把時間花在集群和數據的管理上。根據我們的文檔所給出的指南,你可以在不到十分鐘的時間內讓一個應用跑起來。
本文翻譯已獲授權,原文地址:
http://blog.vespa.ai/post/165763618906/open-sourcing-vespa-yahoos-big-data-processing








 京公網安備 11010502049343號
京公網安備 11010502049343號