










為了滿足日益增長的業務變化,京東的京麥團隊在京東大數據平臺的基礎上,采用了Hadoop等熱門的開源大數據計算引擎,打造了一款為京東運營和產品提供決策性的數據類產品-北斗平臺。
一、Hadoop的應用業務分析
大數據是不能用傳統的計算技術處理的大型數據集的集合。它不是一個單一的技術或工具,而是涉及的業務和技術的許多領域。
目前主流的三大分布式計算系統分別為:Hadoop、Spark和Strom:
Hadoop當前大數據管理標準之一,運用在當前很多商業應用系統。可以輕松地集成結構化、半結構化甚至非結構化數據集。
Spark采用了內存計算。從多迭代批處理出發,允許將數據載入內存作反復查詢,此外還融合數據倉庫,流處理和圖形計算等多種計算范式。Spark構建在HDFS上,能與Hadoop很好的結合。它的RDD是一個很大的特點。
Storm用于處理高速、大型數據流的分布式實時計算系統。為Hadoop添加了可靠的實時數據處理功能
Hadoop是使用Java編寫,允許分布在集群,使用簡單的編程模型的計算機大型數據集處理的Apache的開源框架。 Hadoop框架應用工程提供跨計算機集群的分布式存儲和計算的環境。 Hadoop是專為從單一服務器到上千臺機器擴展,每個機器都可以提供本地計算和存儲。
Hadoop適用于海量數據、離線數據和負責數據,應用場景如下:
場景1:數據分析,如京東海量日志分析,京東商品推薦,京東用戶行為分析
場景2:離線計算,(異構計算+分布式計算)天文計算
場景3:海量數據存儲,如京東的存儲集群
基于京麥業務三個實用場景
京麥用戶分析
京麥流量分析
京麥訂單分析
都屬于離線數據,決定采用Hadoop作為京麥數據類產品的數據計算引擎,后續會根據業務的發展,會增加Storm等流式計算的計算引擎,下圖是京麥的北斗系統架構圖:
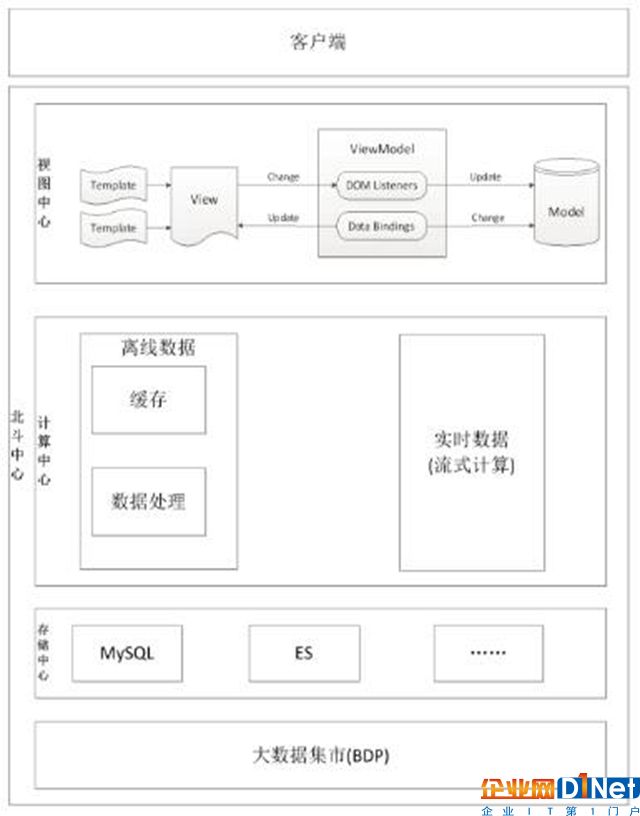
(圖一)京東北斗系統
二、淺談Hadoop的基本原理
Hadoop分布式處理框架核心設計
HDFS :(Hadoop Distributed File System)分布式文件系統
MapReduce: 是一種計算模型及軟件架構
2.1 HDFS
HDFS(Hadoop File System),是Hadoop的分布式文件存儲系統。
將大文件分解為多個Block,每個Block保存多個副本。提供容錯機制,副本丟失或者宕機時自動恢復。默認每個Block保存3個副本,64M為1個Block。將Block按照key-value映射到內存當中。
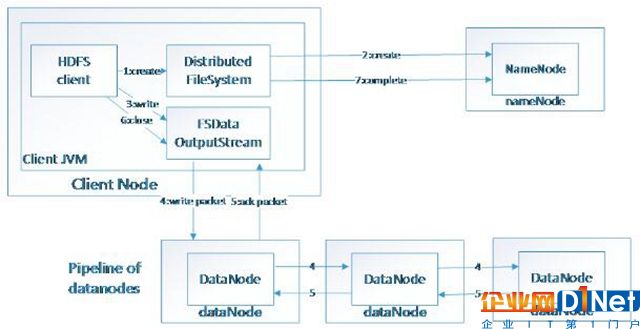
(圖二)數據寫入HDFS
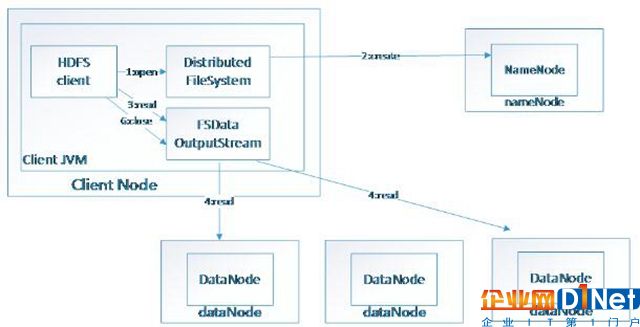
(圖三)HDFS讀取數據
2.2 MapReduce
MapReduce是一個編程模型,封裝了并行計算、容錯、數據分布、負載均衡等細節問題。MapReduce實現最開始是映射map,將操作映射到集合中的每個文檔,然后按照產生的鍵進行分組,并將產生的鍵值組成列表放到對應的鍵中。化簡(reduce)則是把列表中的值化簡成一個單值,這個值被返回,然后再次進行鍵分組,直到每個鍵的列表只有一個值為止。這樣做的好處是可以在任務被分解后,可以通過大量機器進行并行計算,減少整個操作的時間。但如果你要我再通俗點介紹,那么,說白了,Mapreduce的原理就是一個分治算法。
算法:
MapReduce計劃分三個階段執行,即映射階段,shuffle階段,并減少階段。
映射階段:映射或映射器的工作是處理輸入數據。一般輸入數據是在文件或目錄的形式,并且被存儲在Hadoop的文件系統(HDFS)。輸入文件被傳遞到由線映射器功能線路。映射器處理該數據,并創建數據的若干小塊。
減少階段:這個階段是:Shuffle階段和Reduce階段的組合。減速器的工作是處理該來自映射器中的數據。處理之后,它產生一組新的輸出,這將被存儲在HDFS。
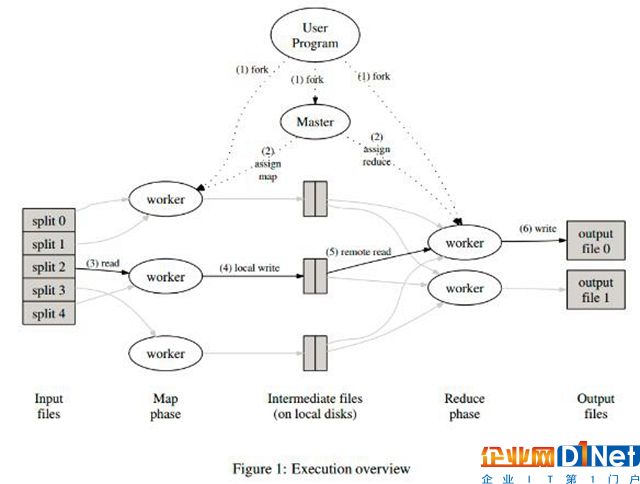
(圖四)MapReduce
2.3 HIVE
hive是基于Hadoop的一個數據倉庫工具,可以將結構化的數據文件映射為一張數據庫表,并提供完整的sql查詢功能,可以將sql語句轉換為MapReduce任務進行運行,這套SQL 簡稱HQL。使不熟悉mapreduce 的用戶很方便的利用SQL 語言查詢,匯總,分析數據。而mapreduce開發人員可以把己寫的mapper 和reducer 作為插件來支持Hive 做更復雜的數據分析。
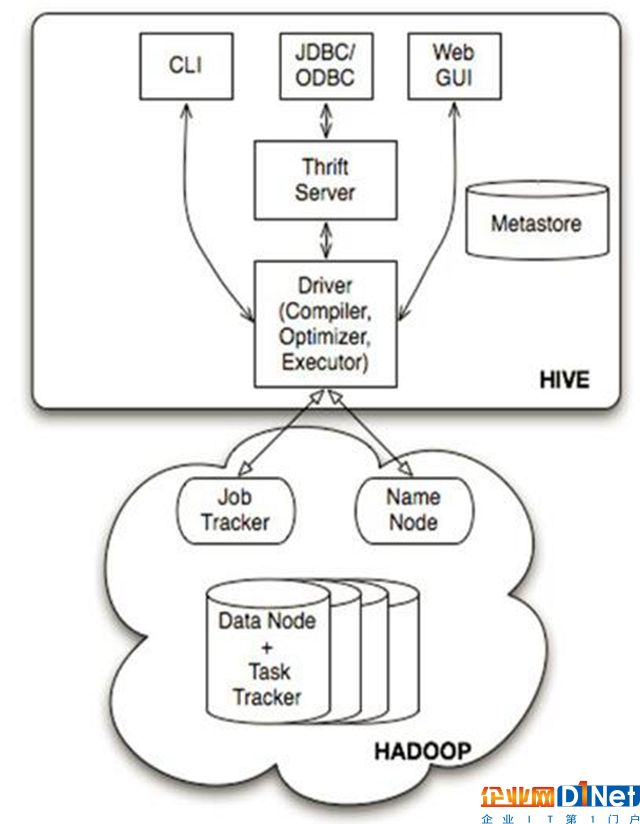
(圖五)HIVE體系架構圖
由上圖可知,hadoop和mapreduce是hive架構的根基。Hive架構包括如下組件:CLI(command line interface)、JDBC/ODBC、Thrift Server、WEB GUI、metastore和Driver(Complier、Optimizer和Executor)。
三、Hadoop走過來的那些坑
進行HIVE操作的時候,HQL寫的不當,容易造成數據傾斜,大致分為這么幾類:空值數據傾斜、不同數據類型關聯產生數據傾斜和Join的數據偏斜。只有理解了Hadoop的原理,熟練使用HQL,就會避免數據傾斜,提高查詢效率。
















 京公網安備 11010502049343號
京公網安備 11010502049343號