


雷鋒網(wǎng)(公眾號:雷鋒網(wǎng)) AI 科技評論按:過去十年里,研究人員在計算視覺領域取得了巨大的成功,而這其中,深度學習模型在機器感知任務中的應用功不可沒。此外,2012 年以來,由于深度學習模型的復雜程度不斷提高,計算能力大漲和可用標記數(shù)據(jù)的增多,此類系統(tǒng)的再現(xiàn)能力也有了較大進步。
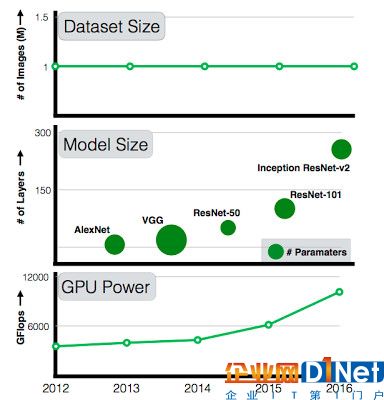
不過在這三個輔助條件中,可用數(shù)據(jù)集的發(fā)展速度并沒有跟上模型復雜度(已經(jīng)從7 層的 AlexNet 進化到了 101 層的 ResNet)和計算能力的提高速度。2011 年時,用于訓練 101 層 ResNet 模型的依然是只有 100 萬張圖片的 ImageNet。因此,研究人員一直有個想法,如果能將訓練數(shù)據(jù)擴容 10 倍,準確率能翻番嗎?那么擴容 100 倍或 300 倍又能得到什么樣的成果呢?我們能突破現(xiàn)有的準確率平臺期嗎?數(shù)據(jù)的增多是否能帶來更多突破?
在《重新審視深度學習時代數(shù)據(jù)的非理性效果》(Revisiting Unreasonable Effectiveness of Data in Deep Learning Era)這篇論文中,研究人員先是吹散了圍繞在海量數(shù)據(jù)和深度學習關系周圍的迷霧。他們的目標是探尋如下問題:
1. 如果給現(xiàn)有算法源源不斷的加標簽圖片,它們的視覺再現(xiàn)能力會繼續(xù)提高嗎?
2. 在類似分類、目標檢測和圖像分割等視覺任務中,數(shù)據(jù)和性能間關系的本質(zhì)是什么?
3. 在計算視覺應用中,能應對所有問題的頂尖模型是否用到了大規(guī)模學習技術呢?
不過,在考慮以上這些問題前,我們先要考慮去哪找這個比 ImageNet 大 300 倍的數(shù)據(jù)集。谷歌一直在努力搭建這樣一個數(shù)據(jù)集,以便提升計算視覺算法。具體來說,谷歌的數(shù)據(jù)集 JFT-300M 已經(jīng)有 3 億張圖片,它們被分為 18291 個大類。負責為這些圖片加標簽的是一個專用算法,它用到了原始網(wǎng)絡信號、網(wǎng)頁關系和用戶反饋等一系列信息。
完成加標簽的工作后,這 3 億張圖片就有了超過 10 億個標簽。而在這些標簽中,大約有 3.75 億個被負責標簽精度的算法選了出來。不過即使這樣,整個數(shù)據(jù)集中的標簽依然存在不少噪聲(noise)。初步估算的數(shù)據(jù)顯示,被選中圖片的標簽中有 20% 都屬于噪聲范圍,由于缺乏詳盡的注釋,因此研究人員無法精確判斷到底那些標簽應該被取消。
進行了一番實驗后,研究人員驗證了一些假設,同時實驗還帶來一些意想不到的驚喜:
1. 更好的表征學習輔助效果。實驗顯示,大規(guī)模數(shù)據(jù)集的使用能提升表征學習的效果,反過來還提高了視覺任務的表現(xiàn)。因此,在開始訓練前搭建起一個大規(guī)模的數(shù)據(jù)集還是相當有用的。同時,實驗也表明,無監(jiān)督和半監(jiān)督表征學習前途無量。此外,只要數(shù)據(jù)規(guī)模起來了,噪聲問題就變得不再重要了。
2. 性能會隨著訓練數(shù)據(jù)數(shù)量級實現(xiàn)線性增長。也許整個實驗最驚人的發(fā)現(xiàn)就是視覺任務中的性能和用于表征學習的訓練數(shù)據(jù)規(guī)模間的關系了。它們之間居然有著異常線性的關系,即使訓練圖片多達 3 億張,實驗中也沒有出現(xiàn)平臺期效應。
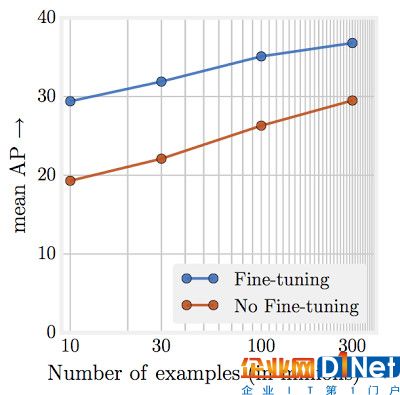
3. 容量非常重要。在實驗中,研究人員還發(fā)現(xiàn),想要充分利用這個巨大的數(shù)據(jù)集,模型的深度和容量必須足夠大。舉例來說,ResNet-50 在 COCO 目標檢測基準上就只有 1.87%,而 ResNet-152 就有 3%。
4. 新成果。在本篇論文中,研究人員還在 JFT-300M 數(shù)據(jù)集訓練的模型中發(fā)現(xiàn)了不少新成果。舉例來說,單個模型已經(jīng)可以達到 37.4 AP,而此前的 COCO 目標檢測基準只有 34.3 AP。
需要注意的是,在實驗中用到的訓練制度、學習安排和參數(shù)設置都是基于此前對 ConvNets 訓練的理解,當時的數(shù)據(jù)集還是只有 100 萬張圖片的 ImageNet。在工作中,研究人員并沒有用到超參數(shù)的最優(yōu)組合,因此最終得到的結果可能并不完美,所以數(shù)據(jù)的真實影響力在這里可能還被低估了。
這項研究并沒有將精力集中在特定任務數(shù)據(jù)上。研究人員相信,未來獲取大規(guī)模的特定任務數(shù)據(jù)將成為新的研究重心。
此外,谷歌那個擁有 3 億張圖片的數(shù)據(jù)集并不是終極目標,隨著技術的發(fā)展,建設 10 億+圖片數(shù)據(jù)集的任務應該提上日程了。雷鋒網(wǎng) AI 科技評論表示對此拭目以待。






據(jù)為王”是真的嗎?谷歌輕撫著100倍的數(shù)據(jù)量點了點頭")

 京公網(wǎng)安備 11010502049343號
京公網(wǎng)安備 11010502049343號