


近日MapR宣布推出了一款名為Quick Start Solution(QSS)的新解決方案,專注于深度學(xué)習(xí)應(yīng)用。MapR強(qiáng)調(diào),QSS是一款分布式深度學(xué)習(xí)產(chǎn)品和服務(wù),能夠大規(guī)模訓(xùn)練復(fù)雜的深度學(xué)習(xí)算法。

想法是這樣的:深度學(xué)習(xí)需要有大量數(shù)據(jù),這是很復(fù)雜的。如果MapR的融合數(shù)據(jù)平臺(tái)是你的主干架構(gòu),那么QSS可以讓你得到將數(shù)據(jù)用于深度學(xué)習(xí)應(yīng)用所需的東西。這是有道理的,這符合MapR的戰(zhàn)略。
MapR是第一家在市場(chǎng)中推出所謂的“AI on Hadoop”產(chǎn)品的Hadoop廠商。但是AI on Hadoop從更大范圍來(lái)說(shuō)是有意義的嗎?其他廠商在這方面都做了什么?
專注深度學(xué)習(xí)的MapR
還記得Hadoop第一次問(wèn)世的時(shí)候嗎?那時(shí)候Hadoop還是一個(gè)具有諸多優(yōu)點(diǎn)的平臺(tái),但是需要用戶具有額外的專業(yè)技能才可以使用Hadoop。現(xiàn)在這種情況改變了。Hadoop已經(jīng)成為一個(gè)蓬勃發(fā)展的生態(tài)系統(tǒng),它取得成功的很大一部分是因?yàn)槲覀兯^的SQL on Hadoop。
Hadoop一直能夠以低廉的成本保存和處理大量數(shù)據(jù),但此前并非如此,直到它支持通過(guò)SQL訪問(wèn)數(shù)據(jù),這讓Hadoop足以成為企業(yè)數(shù)據(jù)主干的有力競(jìng)爭(zhēng)者。SQL仍然是訪問(wèn)數(shù)據(jù)的事實(shí)標(biāo)準(zhǔn),所以支持SQL意味著Hadoop可以被大多數(shù)人所使用。
AI和SQL是不同的。它并不具備向后兼容性,以及商業(yè)功能。AI是一種具有前瞻性的領(lǐng)域。但即使今天,AI對(duì)于使用AI的人來(lái)說(shuō)是一個(gè)差異點(diǎn),但看起來(lái)AI似乎很快就會(huì)成為一種商品。那些沒(méi)有使用AI的人將無(wú)法參與競(jìng)爭(zhēng)。
AI和SQL也是類似的:如果你是一家Hadoop廠商,那么這不是你真正的工作。這是其他人要做的——你只需要確保Hadoop可以運(yùn)行在你的平臺(tái)上,也就是數(shù)據(jù)所在的地方。這就是MapR希望通過(guò)SQL實(shí)現(xiàn)的。
MapR利用開(kāi)源容器技術(shù)(例如Docker),以及編排技術(shù)(例如Kubernetes)以分布式的方式部署深度學(xué)習(xí)工具(例如TensorFlow)。這些技術(shù)都與MapR無(wú)關(guān),但是QSS帶給它的價(jià)值是確保所有功能都可以無(wú)縫連接。
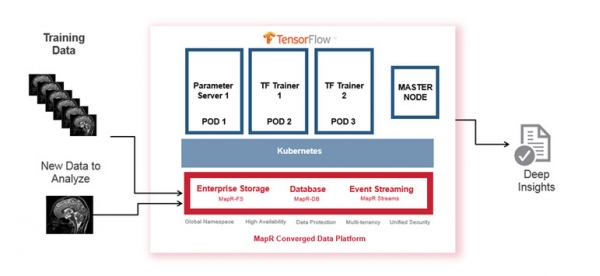
MapR QSS所具有的分布式深度學(xué)習(xí)擁有三層:底層是數(shù)據(jù)層,中間是編排層,頂層是應(yīng)用層
MapR首席應(yīng)用架構(gòu)師Ted Dunning解釋說(shuō):“采用AI/深度學(xué)習(xí)最好的方式就是部署一個(gè)可擴(kuò)展的融合數(shù)據(jù)平臺(tái),這個(gè)平臺(tái)支持最新的深度學(xué)習(xí)技術(shù),且擁有一個(gè)幾乎可以無(wú)限擴(kuò)展的底層企業(yè)數(shù)據(jù)框架。”
他還指出,“幾乎所有機(jī)器學(xué)習(xí)軟件都是獨(dú)立于Hadoop和Spark部署的。這要求有一個(gè)類似MapR這樣的平臺(tái),能夠支持Hadoop/Spark工作負(fù)載,以及傳統(tǒng)文件系統(tǒng)API。”
既然這種方法奏效,那么你為什么不使用MapR-DB、MapR Streams以及MapR-FS,還有MapR Persistent Application Client Container (PACC)來(lái)部署你的模式?哦,我們也為你準(zhǔn)備了服務(wù)來(lái)幫助你。這就是MapR希望通過(guò)QSS傳遞的信息。
MapR首席產(chǎn)品官Anil Gadre表示:“深度學(xué)習(xí)可以為企業(yè)組織提供深遠(yuǎn)的轉(zhuǎn)型機(jī)會(huì)。我們的專業(yè)知識(shí)加上獨(dú)特的設(shè)計(jì)構(gòu)成了QSS的基礎(chǔ)。QSS將可以讓企業(yè)快速利用現(xiàn)代化基于GPU的架構(gòu),為他們擴(kuò)展深度學(xué)習(xí)鋪平道路。”
AI on Hadoop
那么,這與AI on Hadoop是一回事嗎?與SQL不同,AI是沒(méi)有標(biāo)準(zhǔn)的。甚至現(xiàn)在還沒(méi)有一個(gè)被廣泛接受和理解的定義。深度學(xué)習(xí)只是機(jī)器學(xué)習(xí)的一部分,深度學(xué)習(xí)又只是AI的一部分。甚至在深度學(xué)習(xí)中,雖然會(huì)有一些共享的理念,但是沒(méi)有一個(gè)常用的API。所以SQQ是DL on Hadoop,并不是真正的AI on Hadoop。
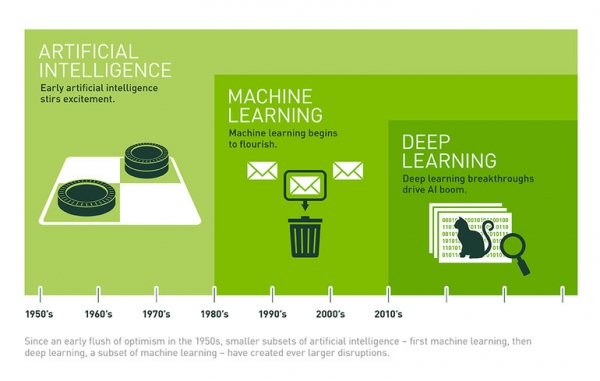
AI不止是機(jī)器學(xué)習(xí),機(jī)器學(xué)習(xí)不止是深度學(xué)習(xí)
使用像Hadoop這樣的數(shù)據(jù)和計(jì)算平臺(tái)作為AI的基礎(chǔ)這是很自然的想法。但是能夠在Hadoop上運(yùn)行機(jī)器學(xué)習(xí)或者深度學(xué)習(xí)并不會(huì)讓Hadoop廠商變成一家AI廠商。這是我們?cè)谶^(guò)去幾個(gè)月與許多Hadoop廠商高管溝通得出的結(jié)論。
對(duì)于Cloudera公司首席執(zhí)行官Tom Reilly來(lái)說(shuō),“機(jī)器學(xué)習(xí)是非常真實(shí)非常活躍的,在實(shí)踐中有很好的表現(xiàn)。我們的客戶正在努力了解AI,了解這對(duì)未來(lái)意味著什么。我們正在幫助他們使用機(jī)器學(xué)習(xí),我們的平臺(tái)已經(jīng)支持機(jī)器學(xué)習(xí),并將繼續(xù)提供支持。我們的平臺(tái)是人們對(duì)AI是使用的數(shù)據(jù)的承載平臺(tái)。”
Cloudera一直被批評(píng)在最近的IPO文件中試圖把自己定位為一家AI公司。據(jù)我們所知,Cloudear并沒(méi)有在AI方面的廣泛內(nèi)部經(jīng)驗(yàn)。它有一個(gè)數(shù)據(jù)科學(xué)團(tuán)隊(duì),有很多員工,還有最近收購(gòu)的sense.io。
Sense.io一直被集成到Cloudear的堆棧中,收購(gòu)后被重新包裝成Cloudera Data Science Workbench (CDSW)。在最近與Cloudear數(shù)據(jù)科學(xué)總監(jiān)Sean Own的交談中,Owen將sense.io比作IBM的DataWorks。
“通過(guò)提供對(duì)數(shù)據(jù)的就緒訪問(wèn),CDWS縮短了通過(guò)我們自動(dòng)化的機(jī)器學(xué)習(xí)平臺(tái)交付AI應(yīng)用價(jià)值的時(shí)間,”DataRobot公司首席執(zhí)行官Jeremy Achin指出。這一點(diǎn)很好,但是這并不是真正的AI,對(duì)吧?
對(duì)于Hortonworks公司首席技術(shù)官Scott Gnau表示,AI包含兩個(gè)關(guān)鍵組成部分:大量數(shù)據(jù)外加數(shù)據(jù)包和算法處理數(shù)據(jù)。Hortonworks支持兩者,AI勝利了,Hortonworks也就勝利了。不過(guò),Gnau強(qiáng)調(diào)說(shuō),他認(rèn)為Hortonworks的優(yōu)勢(shì)在于企業(yè)監(jiān)管和安全性。
Gnau認(rèn)為,我們還沒(méi)有看到我們所期待的AI中的新興技術(shù)。所以Hortonworks的方法是投資基礎(chǔ)設(shè)施,成為值得信賴的數(shù)據(jù)廠商,同時(shí)密切關(guān)注新興的殺手級(jí)技術(shù)和應(yīng)用。
每家廠商的方法都必須考慮現(xiàn)在的大背景以及他們的變革方向。AI是一個(gè)新的戰(zhàn)場(chǎng),廠商各自的方法與他們的理念和目標(biāo)相符合,我們將繼續(xù)關(guān)注和分析AI方面的進(jìn)展。








 京公網(wǎng)安備 11010502049343號(hào)
京公網(wǎng)安備 11010502049343號(hào)