


“滿城盡談大數據”,但很多人其實并不理解大數據真正價值是什么,哈佛大學GaryKing教授用3個大數據研究案例告訴你:有數據固然好,但是如果沒有分析,數據的價值就沒法體現。
以下是Gary King教授演講實錄(有刪節):
工作的領域叫做量化社會科學(QuantitativeSocialScience),有時,它有一個別稱,叫大數據。“大數據”這個詞最早是媒體發現的,它試圖向大眾解釋我們是做什么的,目前看來解釋的效果還不錯。
然而,大數據的價值不是在數據本身,雖然我們需要數據,數據很多時候只是伴隨科技進步而產生的免費的副產品。比如說,學校為了讓學生能更高效地注冊而引進了注冊系統,因而有了學生的很多信息,這些都是因為技術改進而產生的數據增量。
大數據的真正價值在于數據分析。數據是為了某種目的存在,目的可以變,我們可以通過數據來了解完全不同的東西……有數據固然好,但是如果沒有分析,數據的價值就沒法體現。
先來看一個大數據在公共政策層面運用的案例。
我們曾經做過一個評估研究,發現2000年以后美國社會保障管理總署(U.S.Social Security Administration,簡稱“SSA”)對于美國社保賬戶及人口壽命的預測有系統性偏差。
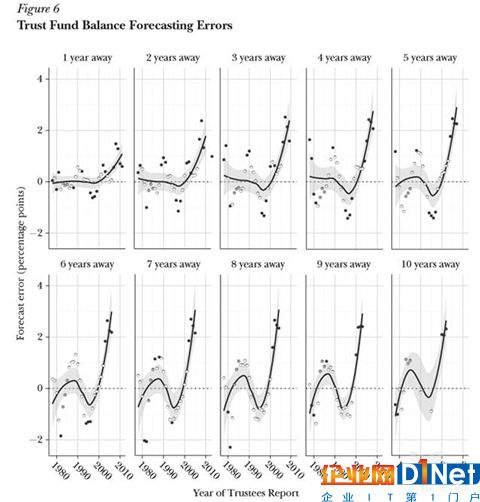
(圖片說明:2000年以后SSA對社保基金賬戶情況的預測出現顯著偏差;來源:GaryKing論文)
大背景是,美國的社會保障平臺是美國最大的單一政府平臺,它的資金是跨代流動的——當前退休者的養老金供給來自于他們的下一代,即現在工作的人交的稅金。
所以SSA需要預測這個信托基金項目里的資金流,以及人的壽命,正確預測這兩點很重要,如果人們比SSA預期的更長壽——雖然這是好事——就很可能導致信托基金里就沒有足夠的錢給他們養老了。
我們研究發現,SSA的預測在2000年以后出現了系統性偏差——發生偏差的原因之一,是SSA使用的模型本質上定性分析的模型,且多年來幾乎沒有調整。由于一些藥物的使用和癌癥早期發現,美國人開始比模型預測地更長壽了。
我們通過分析得出的結論是,美國社保信托基金至少存在8千億美元的缺口。
雖然結論有點不幸,但是政府需要提前知道。這樣政府就可以有空間在稅率,退休年齡等方面進行調整。這是公共政策層面的話題。
關于定性分析和定量分析,其實不是涇渭分明的。做分析全靠定性分析(由人主導)是不夠的,因為你有很多數據不知道該怎么處理。全靠定量分析(由機器主導)也不行,這就像一張巨大的excel表,但是表中沒有行、列的標簽。所以,大數據分析需要的是由人主導,由計算機輔助的技術(weneedcomputer-assisted,human-ledtechnology)。
我們還做過一個計算機輔助閱讀的實驗。我們開發了一套計算機輔助、自動化閱讀的技術,這項技術能幫助人們從非結構化的文字中提取、組織并且處理大量信息。
我們曾用該技術處理了64000篇國會議員官方發布的新聞稿,想通過這項基礎幫我們作分類,看國會議員在新聞稿中都說了些什么。
結果我們發現,居然有高達27%的議員發布的新聞稿內容只是單純地想抨擊對方(PartisanTaunting),而不是想要平衡預算或停止戰爭,或解決問題。
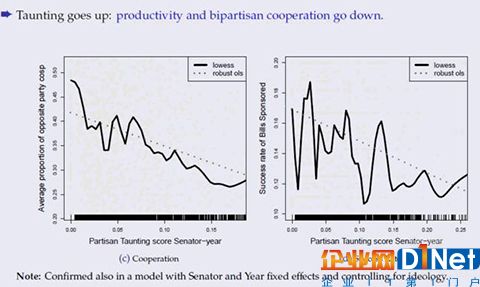
(圖片說明:GaryKing表示,抨擊對方政黨從個人角度來看是理性的,但是從整個集群的角度來看,是非理性的,如果抨擊對方的言語增多,政黨之間的合作關系和能效會減弱;來源:GaryKing研究成果單頁)
大數據時代,我們可以通過去量化過去不能量化的信息,使用精妙的統計學方法分析這些信息成為可能。
現在,我們都可以對一些強定性屬性(inherentlyqualitative)的東西作定量分析了,如音頻和視頻。但是,目前仍有一些定性分析工作者要分析的內容還未被量化。所以,定性分析、定量分析要配合操作才行。
我參與過一個產品項目叫做Perusall。“Peruse”是仔細精讀的意思,Perusall就是peruse+all,可以簡單理解為大家一起讀。
這個產品產生的背景是,大學教授會給同學布置閱讀作業,但是教授很難評估學生是否閱讀了規定的章節。如果有的學生沒讀而有的學生讀了,這對整體課堂的授課效果會有影響。
Perusall的好處之一,是它把閱讀從一個個體活動變成了一個集體活動。閱讀文章的同學可以對自己看不懂的部分做批注,也可以對其他同學的批注作回復解答。這樣更容易調動同學閱讀的主動積極性,讓閱讀變得更有趣。人天生是社會動物,這也是為什么人們相比于在iTunes里聽歌更愿意花錢去看演唱會,雖然前者音樂聲音更清晰。
一旦學生用Perusall在線上閱讀之后,我們就有了很多之前不可能互獲取的數據:知道學生在讀什么,他們對閱讀內容的反饋怎樣,他們在讀每一頁的時候花多少時間;當然,如果你沒有讀書的第46-47頁,我們也會知道這個。
一方面,Perusall會基于每個學生的閱讀情況和評價質量,對學生的這項閱讀作業進行打分,從老師的層面看,這省去了原先閱讀作業不易評估的問題。
另一方面,Perusall會分析這些閱讀數據,知道學生們讀到哪里時覺得困惑。
Perusall可以在老師上課前生成一個“學生困惑報告”(Studentscon fusionreport)。








 京公網安備 11010502049343號
京公網安備 11010502049343號