



“數據集成”的概念或許可以追述到上世紀90年代。受限于處理器、存儲、帶寬等技術條件限制,在過去很長一段時間里,IBM、Oracle、Informatica等廠商在數據集成方面,通常的作法是將大數據轉化為“小數據”,可以簡單理解為數據提煉與管理。這種做法需要專門的團隊開發和維護數據集成平臺,耗時費力,易用性不高。
而如今隨著基礎設施與技術的飛速發展,大數據從概念逐漸落地,企業也紛紛意識到大數據在商業上的價值,這也使數據驅動產品設計,客戶運營和商業決策變得可能。不過在進行最終的數據分析之前,必須先進行數據聚合、集成與清洗,而且這往往要占整個數據分析流程中80%的工作量。
尷尬的是,很多企業雖然有數據決策的意識,卻沒有能力完成這第一步。因為以往處理分布在各個系統內的異構數據,需要聘用專業的數據工程師通過編寫代碼才能完成;另外若采購廠商的數據集成方案,價格高昂不說,在數據集成的實時性、可擴展性和處理實時變化數據等方面都有一定程度的不足。
為了解決這些問題,陳誠在2016年3月創立Data Pipeline,致力于幫助企業提供實時自動化的數據聚合集成平臺。陳誠向獵云網(微信:ilieyun)獨家透露,Data Pipeline已于2016年6月完成了數百萬元天使輪融資,投資方為峰瑞資本。
創始人陳誠畢業于密歇根大學計算機專業,曾是前Yelp的大數據工程師。在Yelp期間從零參與設計并實現Yelp新一代實時數據平臺;銷售合伙人 毛海英曾在用友任職大客戶總監,并曾是SAP華中地區銷售負責人。團隊其他成員多來自于亞馬遜、Yahoo等公司。
據了解,Data Pipeline是一家一站式企業實時自動化數據聚合的服務提供商,致力于為企業提供快捷、安全的數據資產管理工具、平臺和服務,解放企業創新力,幫助企業將資源集中在自身業務和對業務的分析上,讓數據更好更快的支持企業戰略決策。
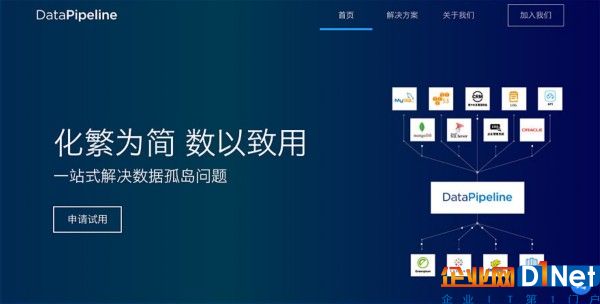
Data Pipeline網站首頁演示的產品架構示意圖
以電商企業發展為例:最初該電商只需使用其交易后臺進行數據統計。隨著交易量、品類、業務、收入的逐步增多,開始引入ERP、CRM、財務等等系統。不同系統產生的大量數據,無法統一進行管理。此時,Data Pipeline的數據聚合作用就體現出來了。
“一站式解決企業數據孤島問題,將使數據聚合效率提高5倍,整體成本降低90%,正是Data Pipeline的優勢。”陳誠說。
據他介紹,Data Pipeline能夠處理企業的存量與增量數據,并采用可視化視圖,操作簡潔。工程師在配置好數據源(可連接包括Oracle、MySQL、SQL Server等任意數據庫)后,系統即可按照設定的規則進行數據清洗,之后便會自動同步到相應的數據目的地(包括Hive、Greenplum、Redshift等數據倉庫),并讓使用者實時監控數據同步情況,實現可視化數據管理。
另外,Data Pipeline還提供API與SDK供企業對接自身業務系統,使生成的數據可直接同步到Data Pipeline并完成數據整合工作。
值得一提的是,考慮到部分企業對數據安全的需求,除了公有云SaaS版以外,Data Pipeline還提供私有化部署。另外其公有云版支持國內主流公有云廠商的部署。
乍一看,該項目與此前獵云網報道的Datablau比較相似,都是進行企業數據處理。不過Data Pipeline更重視數據聚合層面。
獵云網了解到,該產品在收費方面與常見的SaaS類項目略有不同,并非按照賬號年限付費,而是按照其占用的服務器進行年費收取。獵云網認為,由于Data Pipeline需要進行大量數據處理工作,所以從資源占用上收費無疑要比銷售賬號使用權限更加合理。
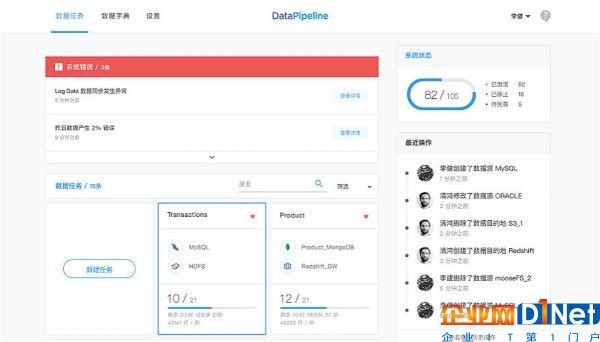
Data Pipeline演示后臺截圖
目前該產品尚在內測階段,已有多家客戶正在試用,客戶群集中在電商、社交以及線下零售企業方面,并且已有客戶達成了付費意向。
2017年,陳誠計劃在打磨產品的同時,著重發力軟件銷售以及市場推廣,打造細分領域標桿案例。
對于該產品,峰瑞資本早期項目負責人朱祎舟表示,數據聚合是企業大數據分析的基礎模塊,隨著企業分析需求的深入,數據環境的復雜,傳統的數據集成方案價格高昂,可擴展性和處理實時性差,沒有辦法滿足現代企業需求。
而Data Pipeline提供的更靈活、更實時的數據聚合服務,可以幫企業數倍地提高效率、按需付費。峰瑞資本持續看好數據服務領域潛力巨大的市場和機會,也看好Data Pipeline及其團隊能夠為企業主提供價值對等交換和解決方案。








 京公網安備 11010502049343號
京公網安備 11010502049343號