









今天分享一下數據分析的一些基本思想,我給它起了個名字叫做用數據說話。內容都是個人的一些心得,比較膚淺!如有不足之處,希望大家諒解!廢話不說了,現在咱正式開始。
用數據說話,就是用真實的數據說真實的話!真實也可以理解為求真務實。那么,數據分析就是不斷地求真,進而持續地務實的過程!用一句話表達就是用數據說話,用真實的數據說話,說真話、說實話、說管用的話。
1.用數據說話
數據本不會說話,但是面對不同的人時,就會發出不同的聲音。現在我們以《荒島售鞋》這個老故事為引例,從數據分析的角度來解讀,看看能不能開出新花?為防止大家案例疲勞,我盡量用新的表達方式把故事羅嗦一下!
話說郭靖和楊康,被成吉思汗派去美麗的桃花島進行射雕牌運動鞋的市場拓展。郭靖和楊康一上桃花島就驚訝地發現這里的居民全部赤腳,沒有一個穿鞋的,不論男女還是老少,莫不如此。楊康一看,倒吸了一口涼氣,說:唉!完了,沒啥市場!郭靖卻不這么認為,馬上掏出了新買的IPHONE4G給鐵木真打了個長途加漫游的匯報電話。面對桃花島這個空白的市場,郭靖電話里這么說:“桃花島人口眾多,但信息閉塞。現在全島居民,全部赤腳。在運動鞋市場上沒有任何競爭對手,茫茫藍海,市場將為我獨霸!可喜,可喜啊!”這個時候,咱現場做個調查,假如你是成吉思汗,你會怎么抉擇?(投資Y1人,不投資的N1人。)
這個時候楊康聽不下去了,馬上搶過電話,說到“大汗,別聽郭靖瞎嚷嚷!市場雖然沒有競爭,但并不就一定是藍海。在全球化競爭的大背景下,這么輕而易舉的就讓我們找到了藍海,您覺得可能嗎?難道阿迪、耐克、彪馬、銳步這些國際巨頭都是棒槌,會發現不了?我看肯定是島上幾百年不穿鞋的生活習慣,短期內無法改變,所以各路群雄,都只能望而止步!可惜,可惜啊!”聽了楊康的論述,鐵木真又該如何選擇呢?請大家舉手表態。(愿意投資Y2人,不愿意投資的N2人。)姜是老的辣!成吉思汗比較理性,他只說了一句:“繼續調研,要用數據說話!”就把電話掛了!
一個星期之后,楊康率先給BOSS匯報了。不過他沒有選擇打電話,而是改發E—MAIL。原因有三:一是全球通資費太高了,錢要省著點花;二是楊康有點小人,他擔心郭靖聽了他的表述后,剽竊他的思想;三是他寫了一份詳細的調研報告,電話里三言兩語說不清。楊康的調查報告里詳細地記錄了他與島內精心選取的200位居民的談話內容,以及他抽取居民樣本時科學合理的甄別條件,最后的結論就是:島內居民全部(100%)以捕魚為生,腳一年四季泡在水里,根本就不需要鞋!聽到這個消息,成吉思汗怎么辦呢?請大家繼續舉手表態!(愿意投資Y3人,不愿意投資的N3人。)
成吉思汗有自己的想法。這個時候,他沒有做決策,而是繼續等。等什么呢?等郭靖的結論!又過了兩天郭靖終于打來了電話。電話里說了3句話:“這個市場可以做!原因是島上的居民每周都要上山砍柴,并且十有八九會被劃破腳!更可喜的是,這兩天他用美男計泡到了島主的女兒黃蓉,而且黃蓉答應給射雕牌運動鞋作形象代言!”故事發生到這個階段,我請大家做最后一次表態。(愿意投資Y4人,不愿意投資的N4人。)
好!數據在變,我們的決策也在變。不過,成吉思汗比我們理性的多。回答還是一句話,不過比第一次多了幾個字:“繼續深入調研,用詳實數據論證。”為什么呢?難道這些數據還不夠詳實嗎?是的!因為在成吉思汗腦袋里還存在有很多疑問。
比如:
1)難道競爭對手真的沒來過?還是對方論證后真的不可行?
2)山上不會開個伐木廠吧?如果有了伐木廠,居民就不會上山砍柴了,到時候送柴上門,鞋還有個屁用啊!
3)為什么一周才上一次山?該不會主要使用的是太陽能吧?
4)運動鞋的運輸成本、營銷成本、銷售成本是多少?投資收益率有多高?
5)……
聽完這個案例,我想問大家一個問題!從數據分析的角度看,你受到了什么啟示?請注意這里說的數據分析的角度,如果你得到的啟示是:鐵木真領導的郭靖與楊康不是1個老男人+2個帥小伙的Gourp,而是教練型的Team。那么,抱歉!這不是我們今天討論的范圍。好,在座的各位誰來表達一下自己的看法呢?提示性的啟示有:
面對同一個數據,不同的人會說不同的話。
真實的數據并不一定能推導出正確的結論。
正確的決策需要有充分的數據去論證。
……
說完了啟示,咱把這頁PPT總結一下。這個案例涉及數據的搜集、分析、匯報以及用于決策的整個過程。在這個過程里,無論那個細節出了問題,最終做出的決策都將是致命的!所以說質量是數據的生命,在數據用于決策的整個過程,都必須保證真實有效!
2.用真實的數據說話
所謂用真實的數據說話,就是指在說話之前,先審核數據的真實性!現實生活中,拿著錯誤的數據還能大言不慚的可以說比比皆是。其中有兩位杰出的代表:一個是傳說中偉大的中國統計局,另一個就是動不動就要封殺這個封殺那個的CCTV。我不是瞎說,因為有數據支撐!
2010年1月20日,國家統計局公布了2009年全國房地產市場數據,全年房價平均每平方米上漲813元。夠雷人吧!雷聲還沒過,霹靂緊跟著又來了!2月25日國家統計局發布了《2009年國民經濟和社會發展統計公報》,數據顯示,70個大中城市房屋銷售價格上漲1.5%。真可是天雷滾滾!難怪網友把統計局票選成大天朝的娛樂至尊!
此話一出,央視不答應了!真所謂中國統計,娛樂至尊;央視不出,誰與爭鋒?那我們仔細推敲一下央視的數據。2010年2月15日,CCTV發布了虎年春晚的滿意度報告,結果顯示滿意度為83.6%。幾乎同一天,新浪的公布的調查結果是14.55%;后來沒幾天,騰訊也發布了滿意度數據,結果是10.48%。數據一出,網友們罵聲不斷,此起彼伏,一浪高過一浪。但是人家央視就是央視,大有敵軍圍困萬千重,我自巋然不動的定力。更夸張的是央視不但能裝作視而不見,充耳不聞,而且還繼續恬不知恥地在自己家的那幾個頻道里賣弄數據,自娛自樂。到底央視的數據錯在哪里?我們先審視一下央視的調查方法。
央視的調查結果,來自央視——索福瑞媒介研究有限公司。索福瑞號稱他們電視觀眾滿意度調查的樣本覆蓋了全國30個城市,抽樣框總人數有30,000人,央視春晚滿意度的調查就是從這3萬人中隨機抽取了2122人進行調查。這樣看,嚴格意義上講所謂83.6%的滿意度只能代表3萬人的看法。當然,如果我拿這個說法與央視理論,對方肯定能拿出3萬代表全國的理論證據。具體就是先從2千推斷3萬,再用3萬推及到30個城市,然后從30個城市推及至全國所有城市,最后再推及至全國。這里用到了簡單隨機抽樣、分層抽樣、典型抽樣,總起來還是個多階段抽樣,多么冠冕堂皇的理論依據!但是,縱然每一步都能保證90%的可靠程度,四次推及下來理論的可靠程度也只有65%。可遺憾的是,最后一步用城市推及全國的做法在理論上還有一道坎,因為我們不知道如何用45%的城鎮居民來代表55%的農村人口?
說完了代表性的問題,我們再看看調查方法。索福瑞采用的是電話調查,而且時段選擇在春晚直播的那幾個小時內。據說調查是從晚上8:30開始,一直持續到春晚結束。巨汗!8:30貌似90%的節目還沒有上演,又怎么能調查到觀眾對整個春晚的滿意度呢?
央視的數據是經不住推敲的!那么,新浪和騰訊的一定對嗎?不一定,這兩個數據也只能代表新浪用戶和騰訊用戶的春晚滿意度,最多能夠代表一下4億網友,要想替13億的中國人民表達心聲,也恐怕是鞭長莫及。
欣賞了統計局和CCTV送給我們的兩個開年笑話之后,我們自己也應該反思,咱們日常工作中,在從數據的搜集、提取、整理到分析、發布、使用的這一連串過程中,數據有沒有失真?是不是數據自始自終都很齊全、很準確,而且統計口徑與分析目的保持著高度的一致呢?這個問題留到日常工作中供大家思考。
3.說真話說實話
拿著錯誤的數據,肯定得不出正確的結論。那么面對真實的數據,就一定能得出正確的結論嗎?未必!給大家看個小笑話。
問:你只有10平米的蝸居,鄰居家從90m2換到190m2,你的居住面積有沒有增加?
答:沒有。
解:錯,你們兩家的平均居住面積是100m2,你的居住面積被神不知鬼不覺地增加了!
這個神不知鬼不覺是誰呢?無敵的平均數!仔細想想,這個均值算錯了嗎?沒有!那么,問題出在哪里?單一的統計量存在片面性,所以要想反映數據的真實面貌,就得使用一系列統計量。
我再杜撰一個氣候的例子,說明一下在結構嚴重失衡的情況下,使用平均數的可怕之處。我們的大中國啊,960萬平方公里,同一時間里有的刮風,有的下雨,還有的高溫酷暑。從去年冬天到今年的春天,北方一直暴雪連天,南方則遭遇百年旱情;而最近這段時間,南方多個省市河水決堤,沿河兩岸,村莊淪陷,而北方則是烈日當頭,干旱焦人,酷暑難耐。如果我們計算全年或者是全國降雨量的平均值,算出來的結果肯定是神州大地風調雨順,國泰民安,而實際卻是華夏民族飽經風霜,多災多難!
還好,統計學家不只給了我們平均數,同時還設計了許多其他的統計量,大家看看下面這個表。
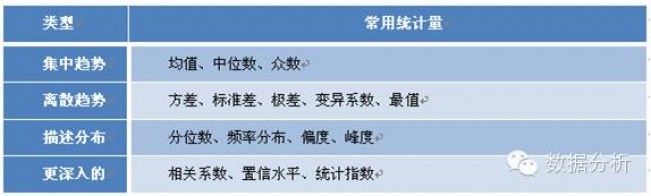
衡量數據的集中趨勢,基本有三個統計量,均值、中位數和眾數。均值是數值平均數,它容易受極端值的影響。也就是說如果數據的跨度或者說是極差不大的話,用均值可以很好的反映真實情況。但是,如果數據的差異比較大,單一使用平均數就會搞出新的笑話了。中位數和眾數屬于位置平均數,中位數是把數據從小到大排序,正好處于中間位置的那個數,眾數是說出現的頻次最多的那個數。
數據除了有集中趨勢,還有離散趨勢。反映離散趨勢的統計量主要有方差、標準差、極差、變異系數等。方差就是觀測值與均值差的平方和除以自由度,自由度一般是n或n-1。總體數據就用n,抽樣數據就用n-1。標準差就是方差的正平方根,它的意義是消除了量綱的影響。極差是最大值與最小值的差,反映的是觀測值的跨度范圍。還有一個比較重要也是比較常用的就是變異系數,它是標準差與均值的比,目的是消除數量級的影響。
此外,還有一些是描述數據分布的統計量,比如分位數,有四分位、八分位、十分位等等,二分位就是中位數,它們反映一系列數據某幾個關鍵位置的數值。頻率分布,就是對數據分組或者是分類后,各組或各類的百分比。偏度是用于衡量分布的不對稱程度或偏斜程度,峰度是用于衡量分布的集中程度或分布曲線的尖峭程度的指標。
如果想再深入一些的話,就會用到相關系數、置信水平、統計指數等等。相關系數是反映變量之間線性相關程度的指標,取值范圍是【-1,1】,大于0為正相關,小于0為負相關,等于0表示不相關。置信水平是指總體參數值落在樣本統計值某一區內的概率。統計指數就是將不能直接比較的一些指標通過同度量因素的作用使得能夠比較,常見的物價指數、上證指數等等。
有了這些基本的統計量,我們在實際工作中只要稍微用心選擇一下,就可以比較準確的描述數據的真實情況。
4.說管用的話
說管用的話是指深入分析數據的實質,挖掘數據的內涵,而不是停留在數據的表層,說些大話、空話或者套話。這就要求在數據分析時,首先明確分析的目的,其次是選擇恰當的方法,最后得出有用的結論。通俗地說,說管用的話,就是不說屁話,少說廢話!
4.1明確分析目的
這里我們舉個例子。我想這個例子的時候正好是7月7號,N年前的那個時候,正好是在座的各位高考的日子,所以就杜撰了一個高考的數據。
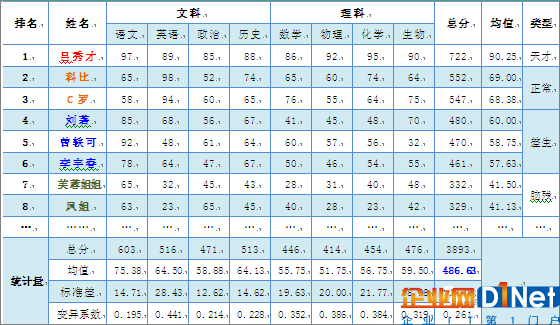
我們這個班級,雖然成績很爛,800分的總分,平均成績只有486分,但是人才輩出,名字一個比一個響,人氣一個比一個旺。大家先認識一下,有飽讀四書五經,滿腹經綸的關東秀才呂輕侯;有籃球場上進攻犀利,防守嚴密的小飛俠科比;還有足球場上無論是邊路傳中還是搶點射門都有非常出色的C羅納爾多;有喜歡煙熏妝、藍絲襪加高跟鞋出鏡的偽娘劉著,有被億萬網友燒香膜拜的春哥黨教主李宇春,還有經常抱著吉他哼著綿羊音的90后MM曾軼可;以及自稱冰清玉潔、妖媚性感、擅長爆發性舞蹈動作的芙蓉姐姐和非清華北大經濟學碩士不嫁、奧巴馬也可的重慶籍奇女子羅玉鳳!
基于學生的考試成績,不同的人會關注不同的方面,高考的判卷老師會關心試卷的雷同程度,命題人會測試考卷的信度和效度,研究文理分科的專家會計算文理成績的相關程度。但是對于普通中學,通常只會關心兩個方面。一是學生成績,計算升學率;二是教學水平,給優秀教師發獎金。如果高中的教學科在這里研究文理相關就屬于廢話,如果還要把問卷的信效檢驗也扯出來就是屁話了。
關于學生:
呂秀才:總分722分,班級第一,平均成績超過90分,如果將其他同學的水平比作三層小樓的話,呂秀才應該是站在賽格頂上!奇才,上清華北大沒有問題。
科比和C羅:總分550左右,平均不到70分!屬于班級2號、3號人物,但成績確實不咋地,不過在該班級中也算鶴立雞群了。
劉著、李宇春、曾軼可:成績較差,上學肯定不是她們的出路!基于平時性情怪異,男的像女,女的像男,還有一個像綿羊,建議別走高考這條尋常路,還是去湖南衛視選秀吧。
鳳姐、芙蓉:這成績,就是個腦殘,估計腦袋不是被門擠過,就是被驢踢過!
關于老師:
衡量教師的優劣需要剔除異常值,呂秀才就是!呂秀才屬于成績異常出眾,個人素質極高,所以他的成績不應該成為衡量老師優劣的樣本。
語文均值高,變異系數小!由此看出語文老師真是好老師!該發獎金!
同理,歷史老師也不錯!也應該適當獎勵。至于物理老師,太差,得趕快換掉,絕對不能讓他繼續誤人子弟了!
存在疑問的就是英語老師。英語成績的均值較高,但變異系數大。這說明數據里可能存在極端值。可能的異常值是科比與C羅。科比美國人,外語自然好!C羅葡萄牙人,但從2003年到2009年一直在英國留學,6年啊,英語好也是應該的!所以,科比與C羅的英語成績不能算是英語老師的栽培,所以科比和C羅是異常值,應該剔除。那么,剔除異常后就會發現英語的均值只有47分!說明英語老師并不能算做好老師,所以只能與獎金無緣了!
4.2選擇恰當的方法
接上面的案例。如果我們是研究高中該不該進行文理分科的有關部門,那么我們該如何分析文理成績之間的相關性?
舉例1:如何計算文理科之間的相關性。
目前基本有三種方法,一是簡單相關分析,二是典型相關分析,三是潛變量相關分析。
簡單相關分析就是通過加總,分別計算出文科成績總和、理科成績總和,然后計算兩者的簡單相關系數。
典型相關分析主要用于衡量兩組變量之間的相關性。它的基本原理是:為了從總體上把握兩組指標之間的相關關系,分別在兩組變量中提取是的相關系數最大的一系列典型變量,然后通過計算各對典型變量之間的相關性,來反映變量間的相關程度。
潛變量相關就是計算潛變量之間的相關系數。所謂潛變量是相對于顯變量或者測量變量而言的。潛變量是實際工作中無法直接測量到的變量,包括比較抽象的概念和由于種種原因不能準確測量的變量。一個潛變量往往可以有多個顯變量,潛變量是可以看做是其對應顯變量的抽象和概括,顯變量則可視為特定潛變量的測量指標。在文理科相關性的分析中,我們可以將文科、理科看成潛變量,將語文、外語、政治、歷史這四個顯變量看成文科的測量指標,將數學、物理、化學、生物這四個顯變量看成是理科的測量指標,那么求文理成績之間的相關問題就轉化成潛變量之間相關的問題。
那么。我們究竟該選用哪種方法呢?或者假如說我們同時使用了上面三種方法,求出相關系數,該選擇哪一個呢?比如我們計算的結果分別是0.35(簡單相關)、0.85(最大典型變量)、-0.65(潛變量相關),這個時候我們到底該相信哪個數據呢?
其實,我更愿意相信簡單相關計算的結果。原因如下:
1)、簡單相關,既簡單又易理解。
2)、典型相關的取值范圍是【0,1】,它計算出的結果沒有正負,只有大小。與我們實際研究目的有悖。我們想知道學生是否在文理課程上均衡發展,所謂均衡就是正相關,所謂不均衡就是負相關。而典型相關做不到。
3)、潛變量相關雖然取值范圍是【-1.1】,但是它多數是采用主成分的方法擬合潛變量,而依據方差提取最大主成分的過程與我們的分析貌似不甚吻合。
4)、最重要的是,其實簡單加總與典型相關、主成分相關擁有同一個思想,就是先把多個變量擬合成一個變量(或幾個),然后分析這個擬合出來的變量之間的相關性。其實,在量綱、數量級相同的情況下,而且權重也容易計算的情況下,最簡單有效的擬合就是加總!所以我認為簡單加總后計算出的相關系數是最有效。而潛變量、典型變量是在量綱或數量級不等的情況下,衡量多個變量之間相關關系的有效方法。
舉例2:計算硬幣正反概率
最后,再給大家做道選擇題。
問題:如果一枚硬幣連拋10次都是正面,問第11次出現正面的概率是多少?
選項:A. 接近0%B.50%C.接近100%D. 以上答案都不對
一個硬幣連拋10次都出現正面的概率是0.510,絕對的小概率事件。在一次實驗中,小概率事件發生,那么我們就應該拒絕原假設。原假設是什么?硬幣出現正反的概率是0.5。所以,我們可以大膽地推斷,硬幣本身就是一個兩面都是正面的硬幣,所以說第11次出現正面的概率是100%,或者接近100%。大家是不是有異議呢?
樹上10只鳥,獵槍一槍打死1只,樹上還剩0只的結論大家都應該同意吧。因為我們考慮的是實際問題,不是10-1=?的數學算式。所以大家在幼兒園的時候就知道槍聲響過,樹上一只鳥都不會剩。試想,你和你的朋友打賭投硬幣猜正反,如果10次之后朋友投出來的都是正面,你會怎么想?兄弟你出千了吧,硬幣肯定有問題吧!相信用不了10次,你就會提出這樣的質疑了。如果說計算概率,0.5沒有錯,獨立事件發生的概率不因之前的情況而改變。但是,如果用假設檢驗的思想,100%的結論就更合理了。之所以說0.5的結果不對,不是說你的計算出錯了,而是在解決實際問題的時候,你太教條了,太書本了,從而選錯方法了。
5.最后總結
我的分享結束了,大家也聽了也笑了,但是笑過之后務必記住我啰嗦了一個小時的這句話:用數據說話就是用真實的數據說話,說真話、說實話、說管用的話!最后說一句廢話:希望剛剛過去的1個小時沒有浪費大家的時間。謝謝!
【編輯推薦】
















 京公網安備 11010502049343號
京公網安備 11010502049343號