









美國時間1月10日,Apache軟件基金會對外宣布,萬眾期待的 Apache Beam 在經歷了近一年的孵化之后終于畢業。這一頂級 Apache開源項目終于成熟。
這是大數據處理領域的又一大里程碑事件——僅僅在上個月,騰訊宣布將在2017年一季度開源其大數據計算平臺 Angel 。現在看來,生不逢時的Angel可能迎來了它最大的對手。至此,谷歌終于也完成了對其云端大數據平臺Cloud Dataflow開源的承諾。
Apache Beam有兩大特點:
1、統一了數據批處理(batch)和流處理(stream)編程范式,
2、能在任何執行引擎上運行。
它不僅為模型設計、更為執行一系列數據導向的工作流提供了統一的模型。這些工作流包括數據處理、吸收和整合。
它針對什么問題提供了解決方案:
大數據處理領域的一大問題是:開發者經常要用到很多不同的技術、框架、API、開發語言和SDK。雷鋒網獲知,取決于需要完成的是什么任務,以及在什么情況下進行,開發者很可能會用MapReduce進行批處理,用Apache Spark SQL進行交互請求(interactive queries),用Apache Flink實時流處理,還有可能用到基于云端的機器學習框架。
近兩年開啟的開源大潮,為大數據開發者提供了十分富余的工具。但這同時也增加了開發者選擇合適的工具的難度,尤其對于新入行的開發者來說。這很可能拖慢、甚至阻礙開源工具的發展:把各種開源框架、工具、庫、平臺人工整合到一起所需工作之復雜,是大數據開發者常有的抱怨之一,也是他們支持專有大數據平臺的首要原因。
谷歌開源Cloud Dataflow背后的算盤是:
Apache Beam的用戶基礎越大,就會有更多人用谷歌云平臺運它。相應地,他們會轉化為谷歌云服務的客戶。騰訊開放Angel的動機與之類似。

背景
2016年2月份,谷歌及其合作伙伴向Apache捐贈了一大批代碼,創立了孵化中的Beam項目(最初叫Apache Dataflow)。這些代碼中的大部分來自于谷歌Cloud Dataflow SDK——開發者用來寫流處理和批處理管道(pipelines)的庫,可在任何支持的執行引擎上運行。當時,支持的主要引擎是谷歌Cloud Dataflow,附帶對Apache Spark和開發中的Apache Flink支持。如今,它正式開放之時,已經有五個官方支持的引擎。除去已經提到的三個,還包括Beam模型和Apache Apex。
雷鋒網獲知,Apache Beam的官方解釋是:“Beam為創建復雜數據平行處理管道,提供了一個可移動(兼容性好)的API層。這層API的核心概念基于Beam模型(以前被稱為Dataflow模型),并在每個Beam引擎上不同程度得執行。”
谷歌工程師、Apache Beam項目的核心人物Tyler Akidau表示:
“當我們(谷歌和幾家公司)決定把 Cloud Dataflow SDK和相關引擎加入 Apache Beam孵化器項目時,我們腦海里有一個目標:為世界提供一個易于使用、但是很強大的數據并行處理模型,支持流處理和批處理,兼容多個運行平臺。”

前景
對于Apache Beam的前景,Tyler Akidau說道:
“一般來講,在孵化器畢業只是一個開源項目生命周期中的一個里程碑——未來還有很多在等著我們。但成為頂級項目是一個信號:Apache Beam的背后已經有為迎接它的黃金時間準備就緒的開發者社群。
這意味著,我們已經準備好向前推進流處理和批處理的技術邊界,并把可移動性(兼容多平臺)帶到可編程數據處理。這很像SQL在陳述性數據(declarative data)分析領域起到的作用。相比不開源、把相關技術禁錮在谷歌高墻之內,我們希望借此創造出前者所無法實現的東西。”
另外,Tyler Akidau信心十足地強調:“流處理和批處理的未來在于Apache Beam,而執行引擎的選擇權在于用戶。”
最后,我們來看看谷歌在去年早些時候發布的“Apache Beam技能矩陣”,用它可以看出每一個兼容引擎執行Beam模型的效果。換句話說,它展示了Apache Beam管道在不同平臺執行的兼容能力。
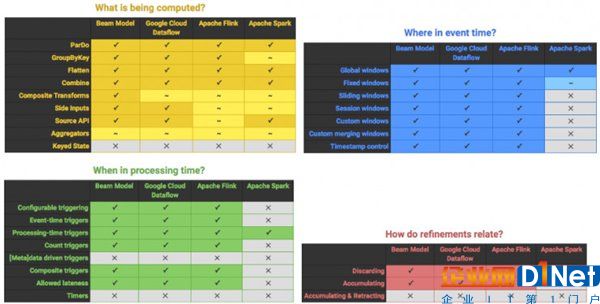
(黃色表:都有什么被計算?藍表:事件時間的那一刻?綠表:處理時間的哪一刻?紅表:各項改進之間有什么關系?)
















 京公網安備 11010502049343號
京公網安備 11010502049343號