











美國時間 2017 年 10 月 2 日,微軟最新一代數(shù)據(jù)庫 SQL Server 2017 正式發(fā)布。SQL Server 2017 帶來了一系列全新的功能與設(shè)計,體現(xiàn)了微軟在數(shù)據(jù)平臺建設(shè)方面的最新思考和實踐。InfoQ 特邀國雙科技高級技術(shù)總監(jiān)何愷鐸撰文對 SQL Server 2017 進行深入探討和解析,以饗各位讀者。
寫在前面
數(shù)十年來,關(guān)系型數(shù)據(jù)庫一直是結(jié)構(gòu)化數(shù)據(jù)存儲的不二之選。從高校到工業(yè)界,關(guān)系型數(shù)據(jù)庫向來是數(shù)據(jù)研究和應(yīng)用的核心,也促生了大批從事數(shù)據(jù)庫開發(fā)、維護和調(diào)優(yōu)的人才。近年來隨著各種 NoSQL 數(shù)據(jù)庫和 Hadoop 技術(shù)生態(tài)的誕生和流行,RDBMS 似乎受到了巨大的挑戰(zhàn),有著“嚴謹呆板”形象的關(guān)系型數(shù)據(jù)庫一度被市場唱衰。然而事實證明,即便面對著眾多后起之秀的競爭,有著悠久歷史的關(guān)系型數(shù)據(jù)庫不但沒有消亡,反而歷久彌堅,不斷推陳出新,在現(xiàn)代后端數(shù)據(jù)架構(gòu)中仍然占據(jù)核心地位,散發(fā)出十足活力。
微軟 SQL Server 數(shù)據(jù)庫,是商業(yè)關(guān)系型數(shù)據(jù)庫陣營中的杰出代表,在 DB-Engines 數(shù)據(jù)庫流行度排行榜上常年位居前三。得益于便捷的圖形化管理界面和易于上手的特點,許多人的關(guān)系型數(shù)據(jù)庫之旅,就是從 SQL Server 開始的。如今正值 SQL Server 2017 發(fā)布之際,我們不妨一起來看看 SQL Server 的前世今生,探究微軟數(shù)據(jù)平臺發(fā)展之路。
微軟 SQL Server 自身的歷史具有傳奇色彩,最初是由微軟、Sybase、Ashton-Tate(開發(fā) dBase 的公司)三家合作,將 Sybase SQL Server 數(shù)據(jù)庫移植到 OS/2 操作系統(tǒng)而誕生的。后來隨著 OS/2 的挫敗和 Windows NT 操作系統(tǒng)的走強,微軟停止了與 Sybase 的合作,開始聚焦于為 Windows 平臺獨立地開發(fā)和維護這個數(shù)據(jù)庫產(chǎn)品,此即 Microsoft SQL Server 的由來。為了避免混淆,Sybase 也將自己的數(shù)據(jù)庫從 Sybase SQL Server 重命名為了 Adaptive Server Enterprise(ASE),從此 SQL Server 僅指微軟旗下關(guān)系型數(shù)據(jù)庫了。說起來 Sybase 的數(shù)據(jù)庫產(chǎn)品也一度在金融等行業(yè)享有盛譽、頗受歡迎,但如今早已風(fēng)光不再,于 2010 年被 SAP 收購,令人唏噓。
與 Sybase 分道揚鑣之后的 Microsoft SQL Server,倒是穩(wěn)扎穩(wěn)打,一路前行。SQL Server 7.0 和 SQL Server 2000 這兩個版本基本完成了在原有 Sybase 代碼基礎(chǔ)上的大量重寫和擴展,正式進入企業(yè)級數(shù)據(jù)庫的行列;而 SQL Server 2005 則真正走向了成熟,與 Oracle、IBM DB2 形成了商業(yè)數(shù)據(jù)庫的三足鼎立之勢。之后 SQL Server 歷經(jīng) 2008、2008 R2、2012、2014、2016 各版本的持續(xù)投入和不斷進化,直至 2017 年 10 月 2 日正式發(fā)布了最新版本 SQL Server 2017,也即本文的主角。
近年回顧
在著手分析 SQL Server 2017 新特性之前,我們不妨先來看看 SQL Server 近些年的著力點,一窺其發(fā)展思路。
著力點之一,在于 OLAP。傳統(tǒng)關(guān)系型數(shù)據(jù)庫一般以行為基本的處理和存儲單位,以便于數(shù)據(jù)記錄的增刪改查。但面對日益增長的數(shù)據(jù)分析和聚合類查詢,基于行的存儲和處理就顯得有些笨拙和低效了。為此,在以 Denali 為代號的 SQL Server 2012 中,微軟引入了一個全新的 xVelocity 列式存儲與分析引擎,使得 SQL Server 擁有了一個高質(zhì)量的列式存儲實現(xiàn),以及一個為矢量化和批處理高度優(yōu)化的查詢執(zhí)行引擎。從此面向 OLAP 負載的數(shù)據(jù)表可以選擇建立基于列存儲的非聚集索引(Non Clustered Column Store Index),大幅提升了分析類查詢性能。在后續(xù)的 SQL Server 版本中,列存儲相關(guān)特性不斷得到進一步的增強和完善,不但引入了列存儲聚集索引(Clustered Column Store Index)使數(shù)據(jù)表能夠完全僅以列式存儲,還通過 Delta-Store 機制實現(xiàn)了列存儲表的數(shù)據(jù)更新支持,進一步拓寬了應(yīng)用場景,增強了易用性。
筆者還清晰記得多年前在自己的 Thinkpad T410 上首次嘗試 SQL Server 2012 的列存儲索引時帶來的震撼,針對近億行數(shù)據(jù)的分析查詢在普通筆記本上也做到了數(shù)秒內(nèi)的返回結(jié)果,令人印象深刻。歷經(jīng)多年的打磨之后,可以說微軟的列存儲實現(xiàn)已經(jīng)成為世界范圍內(nèi)最高效最可靠的列存儲設(shè)計之一。 相關(guān)技術(shù)微軟甚至還作了一定程度的對外輸出:通過與 HortonWorks 合作,微軟向開源世界的 Apache Hive 項目貢獻了不少代碼(被稱為 Stinger 項目,[注 1]),幫助 Hive 提速,其思想精髓也正來自于 SQL Server 的 xVelocity 列式存儲和分析引擎。
著力點之二,在于 OLTP。傳統(tǒng)關(guān)系型數(shù)據(jù)庫其實本就擅長 OLTP,那么可改進的點在哪里呢?計算機發(fā)展的歷史進程所帶來的一個問題是,經(jīng)典的數(shù)據(jù)庫存儲機制大都針對磁盤結(jié)構(gòu)進行設(shè)計和優(yōu)化,原本昂貴的內(nèi)存資源更多充當(dāng)?shù)氖蔷彺娴慕巧6S著硬件技術(shù)不斷發(fā)展,服務(wù)器內(nèi)存不斷增大后,許多場景下數(shù)據(jù)的存儲和索引其實都可以完全納入內(nèi)存中了——這就為基于內(nèi)存的數(shù)據(jù)庫引擎提供了條件。當(dāng)一個數(shù)據(jù)庫引擎及其存儲完全為內(nèi)存優(yōu)化和設(shè)計后,其性能的增幅將是非常驚人的。微軟數(shù)年前在這一領(lǐng)域進行了大舉投入,代號為 Hekaton 的內(nèi)存數(shù)據(jù)庫技術(shù)最早在 2012 年底對外進行了公布[注 2],后隨 SQL Server 2014 正式發(fā)布。配合其無鎖的并發(fā)模型及用 SQL 撰寫的本機編譯存儲過程(Natively Compiled Stored Procedure),相比傳統(tǒng)方案,Hekaton 往往能夠達到多達數(shù)十倍的性能提升,完全地改變了許多系統(tǒng)的設(shè)計思路,實現(xiàn)了之前難以企及的高負荷場景支撐。
可以看到,截止到 SQL Server 2016 版本,這款微軟的拳頭產(chǎn)品已經(jīng)非常強大和完整,能夠在單個產(chǎn)品內(nèi)提供 OLAP 和 OLTP 負載的完美融合。那么僅過了短短一年時間,最新的 SQL Server 2017 還能帶來哪些新的驚喜?我們來一看究竟。
新特性之跨平臺與容器化
SQL Server 2017 第一個不得不提的變化,不是一個具體功能,而是其運行環(huán)境的變革:支持 Linux 服務(wù)器。這是微軟 SQL Server 系列產(chǎn)品首次正式地得以在 Linux 上運行,并且提供完整的官方支持。這無疑大大拓寬了 SQL Server 的應(yīng)用場景和客戶群體。要知道,雖然 Windows Server 的授權(quán)并不算昂貴,但對于許多以 Linux 生態(tài)為主要技術(shù)棧的公司而言,并不會考慮申購和運維基于 Windows 的后端服務(wù)器——因此在技術(shù)選型時,SQL Server 可能第一時間就被排除在外了。當(dāng) SQL Server 2017 正式支持 Linux 后,這一障礙將不復(fù)存在,SQL Server 終于可以在新的戰(zhàn)場和競爭對手開展競爭,這無疑會非常有助于其市場份額的提升。
當(dāng)然,看上去深度耦合于 Windows 的 SQL Server 想要完美地運行于 Linux 上,實現(xiàn)起來絕非一件容易的事情。這是怎樣做到的呢?這里有兩個關(guān)鍵因素:
其一是 SQL Server 原本就有稱為 SQL OS 的底層基礎(chǔ)設(shè)施,該組件可繞過操作系統(tǒng)和 Win32 API 的限制,直接自行管理和組織 CPU、內(nèi)存等計算和存儲資源,以及進行適合自己的線程調(diào)度,以便充分利用底層硬件性能;
其二是來自微軟研究院的 DrawBridge 項目,該項目原用于實現(xiàn)應(yīng)用沙盒機制,它的 Library OS 組件依靠僅約 50 個底層內(nèi)核調(diào)用實現(xiàn)了一千多個常用的 Windows API,同時還具備為其他組件如 MSXML 和 CLR 等提供宿主的能力。
SQL Server 團隊基于這兩個已有基礎(chǔ)進行了偉大的嘗試,將二者進行了必要的重寫和充分的融合,形成了新一代的底層封裝 SQLPAL(SQL Platform Abstraction Layer),同時將上層邏輯代碼都移植到了 SQLPAL 之上——這是 SQL Server 得以在短時間內(nèi)實現(xiàn)跨平臺的關(guān)鍵所在。與此同時,SQLPAL 這種特殊的抽象機制,并沒有付出通常意義上抽象所帶來的性能代價,因為它一定程度地繞過了操作系統(tǒng)的制約,自底向上地搭建了自身所需的運行環(huán)境。
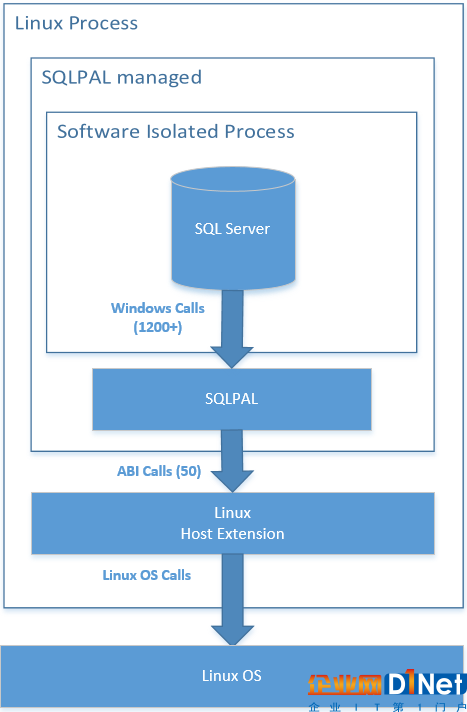
SQL Server on Linux 實現(xiàn)原理[注 3]
前面回顧歷史時我們提到,SQL Server 在 90 年代努力地獨立與成長,戰(zhàn)略性地聚焦在了 Windows 平臺。而 20 多年后,SQL Server 如今跨出擁抱 Linux 的關(guān)鍵一步,同樣是一種戰(zhàn)略的調(diào)整。歷史看似循環(huán)往復(fù),其實都是不同時代不同環(huán)境下的最佳商業(yè)選擇。
為了給 SQL Server on Linux 保駕護航,微軟還和 Red Hat 等老牌 Linux 提供商達成了合作[注 4],一起為客戶提供整合解決方案,以確保操作系統(tǒng)層面的可靠性及與 SQL Server 的兼容性。目前 SQL Server 能夠被安裝到 Red Hat Enterprise Linux、SUSE Linux Enterprise Server 及 Ubuntu 之上。伴隨著 Linux 支持一起到來的,還有對于容器的支持。SQL Server 2017 現(xiàn)能完美地通過 Docker 運行,微軟也已在 Docker Hub 上發(fā)布了基于 SQL Server on Linux 的官方 SQL Server 鏡像[注 5](微軟同時還提供了面向 Windows 容器的版本)。SQL Server 容器化的主要意義在于支持 DevOps。在以往,想要讓 SQL Server 這樣一個重型數(shù)據(jù)庫實例按需地、自動地啟動或關(guān)閉是比較困難的,一般都需要事先安裝準備好相關(guān)的數(shù)據(jù)庫環(huán)境;而如今,借助容器和鏡像,我們可以非常方便地通過 Docker 來輕量化地啟停 SQL Server,通過腳本與 DevOps 流程進行集成也變得很容易。
筆者曾經(jīng)在自己的一個開源類庫[注 6]中做過這樣的嘗試,將原有的依賴于 SQL Server LocalDB 的一系列集成測試遷移到了新的 SQL Server 容器上,順利解除了本地測試運行環(huán)境必須安裝 SQL Server 的依賴,也為在遠端 CI 環(huán)境中運行測試掃清了障礙。當(dāng)然,除了 DevOps 方面的應(yīng)用,也可以嘗試在生產(chǎn)環(huán)境直接使用容器化的 SQL Server,以便使數(shù)據(jù)庫也統(tǒng)一納入生產(chǎn)環(huán)境容器編排的范疇。限于篇幅,此處不再展開。
如上所述,SQL Server 2017 已從原來固守 Windows 的策略,大步地轉(zhuǎn)向了支持 Linux、Docker 容器和 Windows 三大平臺。這一決策無疑將對 SQL Server 乃至數(shù)據(jù)庫市場產(chǎn)生深遠影響。
新特性之圖數(shù)據(jù)處理
向新興的 NoSQL 學(xué)習(xí)也是現(xiàn)代關(guān)系型數(shù)據(jù)庫發(fā)展的一個重要特征。如文檔型數(shù)據(jù)庫善于處理的 JSON 數(shù)據(jù),在 SQL Server 2016 中也成為了一等公民,得到了存儲、索引、查詢等方面的全面支持。而在 SQL Server 2017 中,這位數(shù)據(jù)庫老前輩與時俱進,又開始向 Neo4j 這樣的后起之秀學(xué)習(xí),大膽地引入了圖數(shù)據(jù)的處理與支持[注 7]。
眾所周知,圖數(shù)據(jù)庫的核心實體是節(jié)點和邊,通常都擁有一些屬性,然后節(jié)點通過邊進行相互關(guān)聯(lián)。在傳統(tǒng)關(guān)系型數(shù)據(jù)庫中,對圖進行建模其實并不困難,可以通過為節(jié)點和邊分別建表并通過外鍵關(guān)聯(lián)的方式來完整表達圖的信息。然而,主要的問題在于查詢和查詢的性能:一些典型的圖查詢的表達在傳統(tǒng)關(guān)系型數(shù)據(jù)庫中顯得笨拙而困難,尤其當(dāng)需要在圖的節(jié)點間進行多次跳躍(multi-hop)時,SQL 的撰寫比較容易出錯,查詢性能也不能得到保證。
SQL Server 2017 中的圖數(shù)據(jù)庫特性試圖解決這兩個問題,它仍然以表的形式來對圖信息進行建模和存儲,但加上了額外的擴展,大幅提升了易用性。在創(chuàng)建表時,現(xiàn)可通過 T-SQL 的擴展語法來指定此表是圖數(shù)據(jù)庫中的節(jié)點表 (AS NODE) 或邊表 (AS EDGE),隨后 SQL Server 會隱式地為表加上 $node_id 或是 $edge_id、$from_id、$to_id 等字段,以幫助記錄節(jié)點和節(jié)點間的關(guān)系;在查詢時,SQL Server 2017 一定程度借鑒了 Neo4j 中 Cypher 查詢語言的部分語法,通過引入 MATCH 關(guān)鍵詞來幫助用戶以 ASCII-art 的方式表達有向圖中的節(jié)點巡游,同時完美地融合進現(xiàn)有的 SQL 查詢體系。我們不妨來看一個官方的查詢樣例:
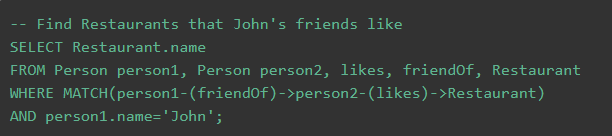
可以看到,上述 T-SQL 片段能夠很方便地表達出“John 的朋友喜愛的餐館”這個包含兩種不同連接類型的“二跳式”查詢,并且用 ACSII 字符表達的箭頭也很好地體現(xiàn)了邊的方向性。若與相同語義的傳統(tǒng) SQL 寫法相比,這樣的表達方式無疑清晰、直觀得多。
圖數(shù)據(jù)庫特性在 SQL Server 2017 中已初露崢嶸。當(dāng)然,由于此特性是首次引入,客觀上來講并沒有到達完全成熟的程度。例如,不支持 transitive closure(節(jié)點間不限跳躍次數(shù)的連通性判斷)和 polymorphism(查詢某節(jié)點所能到達的不同類型的節(jié)點)等圖數(shù)據(jù)庫常用的高級查詢。在性能方面,SQL Server 目前主要利用的也僅是二維表的既有索引和查詢優(yōu)化器所作的表連接優(yōu)化,尚沒有引入為圖優(yōu)化的專用數(shù)據(jù)結(jié)構(gòu)。期待后續(xù)的版本升級和更新會在這些方向上做進一步的增強。
新特性之?dāng)?shù)據(jù)庫內(nèi)機器學(xué)習(xí)
機器學(xué)習(xí)無疑是近年來的熱詞,也是現(xiàn)代數(shù)據(jù)應(yīng)用不可或缺的組成部分。微軟雖然在此領(lǐng)域擁有雄厚的研究實力和成果,但在構(gòu)建相關(guān)開發(fā)生態(tài)上卻顯得動作緩慢。早年的 SQL Server Analysis Service 雖然也內(nèi)置了數(shù)據(jù)挖掘功能,但因過于笨重及程序集成困難等問題,使用場景非常受限。直到近年,微軟才開始逐漸發(fā)力:在 2015 年初,微軟果斷地將 Revolution Analytics 收入囊中[注 8]。此次收購至關(guān)重要,它為微軟帶來了面向 R 語言生態(tài)的全面的開源和商業(yè)解決方案,覆蓋了龐大的 R 語言社區(qū)和數(shù)據(jù)科學(xué)家人群。
那么作為經(jīng)典的關(guān)系數(shù)據(jù)庫,SQL Server 如何應(yīng)對和適應(yīng)這個新趨勢呢?受益于 Revolution Analytics 的收購,SQL Server 2016 版本帶來了突破性的 SQL Server R Services[注 9]:能夠讓 R 語言及其生態(tài)直接作為一個服務(wù)在 SQL Server 環(huán)境內(nèi)部運行。而在 SQL Server 2017 中,更進一步加入了另一個擁有強大 AI 生態(tài)的語言支持:Python。原有的 R Services 也與新引入的 Python 服務(wù)一起重命名為 Machine Learning Services。
Machine Learning Services 的核心產(chǎn)品思路,是在數(shù)據(jù)庫內(nèi)直接運行機器學(xué)習(xí)負載,它允許大家熟悉的 Python/R 腳本與眾多機器學(xué)習(xí)類庫在數(shù)據(jù)庫服務(wù)器上運行,并無縫地與 SQL 銜接。這樣的設(shè)計理念,與傳統(tǒng)的數(shù)據(jù)庫外獨立的機器學(xué)習(xí)相比有何好處呢?在筆者看來,其核心優(yōu)勢正在于“集成”二字,可從幾個方面來理解:
一是便捷的數(shù)據(jù)集成,即無需進行復(fù)雜的數(shù)據(jù)移動和準備就可以使用 SQL 訪問到各類業(yè)務(wù)數(shù)據(jù),并提供給 Python/R 的各類 AI 算法作為輸入;二是高效的模型集成,即訓(xùn)練完成后的模型可以使用 SQL Server 進行管理和存儲,模型使用時也可輕易地通過存儲過程進行調(diào)用并獲取結(jié)果,SQL Server 會自動幫助你完成執(zhí)行引擎和 Python/R 運行環(huán)境間的高效數(shù)據(jù)傳輸和序列化;三是無痛的應(yīng)用集成,即應(yīng)用可以通過傳統(tǒng)的數(shù)據(jù)庫連接和存儲過程返回值的方式來獲得機器學(xué)習(xí)能力,無需復(fù)雜的儀式和專用的架構(gòu),一切就和傳統(tǒng)的數(shù)據(jù)庫訪問一致。
當(dāng)然,客觀地說數(shù)據(jù)庫內(nèi)機器學(xué)習(xí)的設(shè)計也有其技術(shù)局限,主要體現(xiàn)在可伸縮性方面:由于模型訓(xùn)練時需要較大的計算資源消耗,因此單機服務(wù)器可能成為潛在的瓶頸。雖然 SQL Server 中可以使用性能超越開源 R 實現(xiàn)的 ScaleR/ScalePy/MicrosoftML 等支持多線程和 GPU 加速的商業(yè)級類庫,但可能仍不適合數(shù)據(jù)量大到需要動用大規(guī)模集群進行訓(xùn)練的場合。此外,也有人對數(shù)據(jù)庫內(nèi)集成 Python/R 腳本的開發(fā)、測試和運維成本表示疑慮。這些也是微軟后續(xù)會考慮增強的地方,R Tools for Visual Studio 在這方面已經(jīng)作出了一些努力。
對比同類解決方案,SQL Server Machine Learning Services 有其獨特的優(yōu)勢。數(shù)據(jù)庫內(nèi)機器學(xué)習(xí)的理念讓擁抱 AI 變得更簡單而直接,也意味著更低的研發(fā)成本和更早的上線時間。它尤其適合現(xiàn)有基于 SQL Server 的企業(yè)應(yīng)用進行機器學(xué)習(xí)方面的嘗試和升級。讓我們期待更多的實際案例的誕生,也期待它的進一步完善。
新特性之自適應(yīng)查詢處理
如果說數(shù)據(jù)庫內(nèi)機器學(xué)習(xí)給開發(fā)者應(yīng)用帶來了智能,那么 SQL Server 的查詢執(zhí)行引擎本身是否也能變得更聰明更智能呢?答案是肯定的,這也正是 SQL Server 2017 的另一個發(fā)展方向,相關(guān)的一系列特性被稱為自適應(yīng)查詢處理(Adaptive Query Processing)。
SQL 查詢高效執(zhí)行的關(guān)鍵在于制定合理的執(zhí)行計劃。一般來說,執(zhí)行計劃的生成發(fā)生在查詢執(zhí)行之前,是執(zhí)行引擎基于統(tǒng)計信息和索引狀態(tài)等元數(shù)據(jù)信息,結(jié)合執(zhí)行步驟和中間結(jié)果集的量級預(yù)估而綜合得出的。同時執(zhí)行計劃通常會進行緩存,以便相同形式的查詢可以復(fù)用查詢計劃,以提高綜合查詢性能——這一切看上去很美好,不是么?然而在實際環(huán)境中,上述的精妙機制也會遇到種種挑戰(zhàn)和棘手問題。例如,參數(shù)化的查詢常常對參數(shù)輸入較為“敏感”,不同的參數(shù)會導(dǎo)致數(shù)據(jù)結(jié)果量級波動很大,難以事先預(yù)估和選擇最優(yōu)的查詢計劃;又如統(tǒng)計信息未及時更新導(dǎo)致中間結(jié)果集規(guī)模預(yù)估失誤而選擇了錯誤的計劃;再如使用 hint 解決短期問題,導(dǎo)致長期來看效果適得其反等等。
為了緩解上述的種種痛點,勢必要引入執(zhí)行時智能和自我調(diào)優(yōu),對此 SQL Server 2017 的自適應(yīng)查詢處理作了有益的探索和落地。其核心思路在于,一定程度地延后完整的執(zhí)行計劃生成的時間,等待部分實際輸入集合到位后再做下游執(zhí)行方式的策略選擇。例如,新引入的自適應(yīng) join 運算符可以基于上游數(shù)據(jù)輸入的精準量級動態(tài)地選擇聯(lián)接策略是應(yīng)當(dāng)使用 nested loop 還是 hash join;又如多語句表值函數(shù) (MSTVF) 不再使用固定的量級預(yù)估,而是可以先執(zhí)行函數(shù)再制定下游執(zhí)行計劃的方式來確保獲得更優(yōu)的執(zhí)行效率。這些新特性,有 DBA 給出了“能夠避免我上周一半的查詢性能調(diào)優(yōu)工作” [注 10]的高度評價。
除了執(zhí)行時的計劃延遲生成,數(shù)據(jù)庫系統(tǒng)還可以從已經(jīng)執(zhí)行完成的查詢中獲得反饋,以便后續(xù)的同形態(tài)查詢獲得更合適的查詢計劃,這是超越簡單的執(zhí)行計劃緩存的更高級形式。在這個方面,SQL Server 2017 實現(xiàn)了批處理模式下的內(nèi)存分配反饋(memory grant feedback)功能, 可幫助后續(xù)查詢從之前查詢的內(nèi)存分配實踐中吸取“經(jīng)驗教訓(xùn)”,實現(xiàn)內(nèi)存資源的準確估計和分配。
可以看到,SQL Server 2017 已通過自適應(yīng)查詢處理在執(zhí)行智能方面開始發(fā)力,實現(xiàn)了一系列場景下的自動適應(yīng)和優(yōu)化,同時做到了對開發(fā)者透明。目前其局限性主要在于不少上述特性僅適用于批處理模式(見于針對列存儲的查詢),而不適用于傳統(tǒng)的行式處理模式。相信微軟今后會在此領(lǐng)域加入更多對行處理模式的支持,進一步拓展自適應(yīng)查詢處理的適用場景。
SQL Server 與大數(shù)據(jù)
在大數(shù)據(jù)時代,以 Hadoop 為代表的分布式數(shù)據(jù)處理計算框架層出不窮,取得了空前的生態(tài)繁榮;而以 Hive、Impala、Presto 等為代表的 SQL on Hadoop 解決方案更是對傳統(tǒng)數(shù)據(jù)庫發(fā)起了強而有力的沖擊。在這樣的時代背景下,關(guān)系型數(shù)據(jù)庫的確略顯尷尬。那么,SQL Server 是如何應(yīng)對和擁抱“大數(shù)據(jù)”浪潮的呢?
應(yīng)對之一,是強化 SQL Server 自身的數(shù)據(jù)存儲和處理能力,拓展應(yīng)用場景,即”SQL Server 也能處理大數(shù)據(jù)”。得益于服務(wù)器硬件技術(shù)的不斷發(fā)展,單服務(wù)器容量和處理能力不斷提高,配合優(yōu)秀的分區(qū)機制和列存儲壓縮,SQL Server 事實上已經(jīng)能夠處理相當(dāng)大體量的數(shù)據(jù)。去年微軟和英特爾曾合作進行了一個有趣的實驗,使用一臺單機 SQL Server 服務(wù)器承載了多達 100TB 的數(shù)據(jù),并進行了詳細的測試,其綜合性能表現(xiàn)令人驚喜[注 11]。百 TB 的量級,其實已經(jīng)能夠滿足不少存儲和計算“大數(shù)據(jù)”的需要了。在很多場景下,與有著 over-engineering 之嫌的 Hadoop 集群方案相比,SQL Server 更易于管理和維護,架構(gòu)穩(wěn)定簡單,反倒是綜合成本更低的選擇。
當(dāng)然,若是面對 PB 級別以上的數(shù)據(jù),單服務(wù)器仍會捉襟見肘。針對這樣的數(shù)據(jù)量級,微軟有一個被稱為 SQL Server Parallel Data Warehouse(簡稱 PDW)的產(chǎn)品解決方案,可以理解為 SQL Server 的一個分布式變體,是基于 SQL Server 核心構(gòu)建的一個 MPP 分析型數(shù)據(jù)庫。PDW 通常以與硬件廠商合作的方式進行軟硬件一體化售賣,能夠輕松支持 PB 規(guī)模的數(shù)據(jù)存儲與分析。
應(yīng)對之二,自然是與大數(shù)據(jù)開源解決方案的充分共通與融合,尤其是大數(shù)據(jù)的事實標準:Hadoop。這里的主角,是微軟在 SQL Server 2012 PDW 中開始正式引入的 PolyBase 技術(shù)。現(xiàn)在它不再是 PDW 版本所獨有,已成為了標準 SQL Server 和 Hadoop 間的重要橋梁。PolyBase 的核心能力,是允許在 SQL Server 上下文環(huán)境中定義面向 Hadoop 的外部表,并面向外部表執(zhí)行 SQL——這一設(shè)計思路和 Hive 的外部表以及 PostgreSQL 的 FDW 擴展非常類似。基于這樣的核心能力,就能夠很容易地實現(xiàn)將大量數(shù)據(jù)從 Hadoop 導(dǎo)入 SQL Server,也可以反向?qū)?SQL Server 數(shù)據(jù)導(dǎo)出至大數(shù)據(jù)集群。若和 Sqoop 這樣單純的數(shù)據(jù)移動方案相比,PolyBase 一方面擁有更好的性能(基于直接 HDFS 訪問而非 MapReduce),另一方面受益于外部表的抽象,能夠在外部 Hadoop 數(shù)據(jù)不落地的情況下和本地數(shù)據(jù)庫表進行聯(lián)合查詢。
由上可見,面對風(fēng)起云涌的大數(shù)據(jù)浪潮,微軟沒有固步自封。在強化自身能力的同時,SQL Server 也選擇了和大數(shù)據(jù)生態(tài)和諧共存,互相融合。
SQL Server 與云計算
如今的云計算發(fā)展如火如荼,因此擁抱和支持云也是每一個數(shù)據(jù)庫產(chǎn)品都需要做好的功課。在這個方面,SQL Server 稱得上是成績出色的優(yōu)等生,是微軟云計算戰(zhàn)略的重要組成部分。
作為擁抱云的第一步,微軟毫無懸念地將 SQL Server 以 PaaS 服務(wù)的形式提供了出來。這一服務(wù)其實早在 2010 年就已經(jīng)發(fā)布,當(dāng)時命名為 SQL Azure,后改稱 Azure SQL Database。對傳統(tǒng)商業(yè)數(shù)據(jù)庫而言,通常采購和安裝的流程較為冗長,開發(fā)者即便有興趣,也有比較高昂的嘗試成本——Azure SQL Database 的出現(xiàn)徹底改變了這一點,只需在 Azure 門戶中輕輕點擊,一個托管的數(shù)據(jù)庫實例就整裝待發(fā)了。這一商業(yè)模式上的改變,無疑大大降低了微軟數(shù)據(jù)庫的使用門檻,拓展了使用場景。
從技術(shù)上來說,Azure SQL Database 絕非通過虛擬機提供 SQL Server 服務(wù)那么簡單,它是基于 SQL Server 的能力完全為云端環(huán)境設(shè)計的 PaaS 產(chǎn)品——它不但擁有豐富的 SQL Server 特性,與 SQL Server 的功能升級同步,而且具有良好的彈性伸縮特點。Azure SQL Database 使用 Data Transaction Unit (DTU) 的概念來描述 SQL Database 實例的性能級別。用戶可以隨時地按需調(diào)整數(shù)據(jù)庫實例 DTU 的大小,以達到不同時間段下工作負載和性能級別的匹配,有效地節(jié)省成本。此外,Azure SQL Database 還支持彈性池(elastic pool)特性,允許一組數(shù)據(jù)庫實例共享一個資源池,特別適合于多租戶的 SaaS 類應(yīng)用程序。
在微軟 2015 年 Build 大會上發(fā)布的 Azure SQL Data Warehouse,則是 SQL Server 在云端的另一位表親。它本質(zhì)上是前面提到的 SQL Server PDW 的云端版,是可用于大規(guī)模數(shù)據(jù)計算與分析的分布式數(shù)據(jù)倉庫。SQL Data Warehouse 的核心技術(shù),除分布式調(diào)度之外,正是運行在 SSD 存儲之上的列存儲索引。相對主要競品 AWS RedShift 而言,Azure SQL Data Warehouse 受益于 Azure 存儲與計算分離的理念,不但可以動態(tài)調(diào)節(jié)計算能力,甚至可以“關(guān)機”,即暫時關(guān)閉計算能力而僅保留存儲——這在許多數(shù)據(jù)倉庫場景中是可以節(jié)省大量成本的殺手級特性,也成為了許多客戶選擇 Azure 的原因。
當(dāng)然,有時仍然需要 SQL Server 以 VM 的形式在 Azure 上運行,以突破一些 PaaS 形式云數(shù)據(jù)庫的限制,如使用 SQL Agent 或需要在 VM 上安裝其他配套軟件等。針對這種情形 Azure 也提供了便捷的 SQL Server 虛擬機,開箱即用,數(shù)據(jù)庫的許可證費用也會按照使用時間進行計算。
作為擁抱云計算的另一種形式,SQL Server 也非常重視云端互操作能力,將云作為自己的擴展,以及融入云端數(shù)據(jù)平臺體系。首先,從 2016 版本起,SQL Server 就開始支持使用云作為數(shù)據(jù)庫的外延,通過 Stretch Database 功能可以讓本地數(shù)據(jù)庫中的冷數(shù)據(jù)自動無縫地上傳到 Azure 云中,同時前端查詢不需要做任何的調(diào)整。其次,SQL Server 也能夠通過不斷增強的 PolyBase 技術(shù)順暢地融入云端的大數(shù)據(jù)解決方案,如微軟自家的 Azure Data Lake 或是 Hortonworks 提供支持的基于 HDP 的 HDInsight。
前景與展望
如今的 SQL Server 風(fēng)華正茂,早已不是當(dāng)年那個被認為“只適合中小企業(yè)”的年輕后輩。通過拿下納斯達克、NTT DoCoMo 等大型標桿客戶,SQL Server 正在全面出擊、攻城掠地,已不懼怕任何競爭對手。Gartner 近年的魔力象限報告也可以印證這一點:微軟已在操作型數(shù)據(jù)庫、分析型數(shù)據(jù)管理解決方案和商業(yè)智能等多個領(lǐng)域都處于領(lǐng)導(dǎo)者象限。
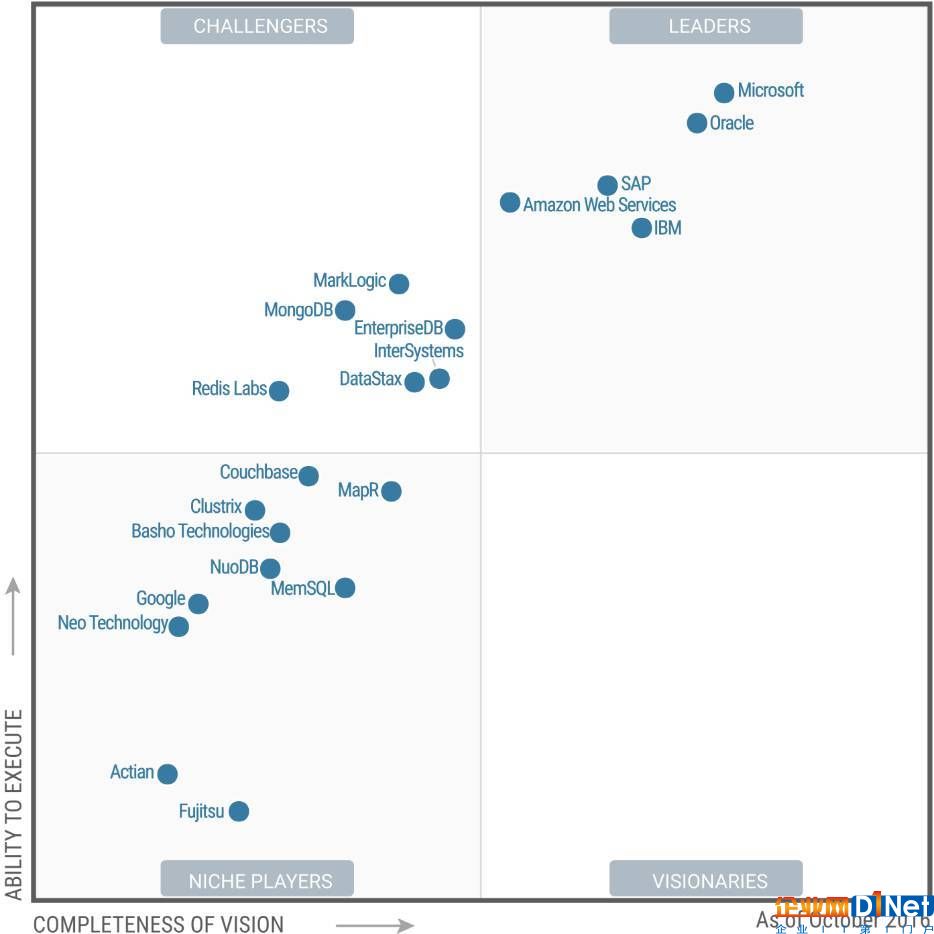
Gartner 操作型數(shù)據(jù)庫 (ODBMS) 魔力象限圖[注 12]
距離 SQL Server 2016 短短一年,SQL Server 2017 就全新發(fā)布了,微軟明顯加快了更新的節(jié)奏。支持 Linux 的 SQL Server 2017 完全有理由百尺竿頭,更進一步。這是技術(shù)平臺的選擇,更是商業(yè)策略的創(chuàng)新。脫離 Windows 捆綁之后的 SQL Server 即將闖蕩一片新的廣闊市場。
從使用場景角度來看,如上述介紹,SQL Server 現(xiàn)既可以從容應(yīng)對高頻 OLTP 負載,也可以作為面向 OLAP 的數(shù)據(jù)倉庫,還可以打造為基于內(nèi)存的實時數(shù)據(jù)處理組件,或是用作應(yīng)用智能的驅(qū)動引擎——SQL Server 已經(jīng)變得非常“全能”。
另外值得一提的是,相比 Oracle、SAP 等競爭對手的細分產(chǎn)品策略和琳瑯滿目的產(chǎn)品列表,微軟選擇了“簡單、集成”的設(shè)計哲學(xué)和商業(yè)模式。一個 SQL Server Enterprise Edition 就囊括了競品中可能需要分別單獨購買的列存儲、內(nèi)存數(shù)據(jù)庫等功能,商務(wù)層面更加便捷的同時,也簡化了系統(tǒng)架構(gòu)。從版本策略的角度,微軟也進行了聰明的調(diào)整,將大多數(shù)的重要功能下放到了 Standard Edition 和 Express Edition 中,轉(zhuǎn)而主要通過數(shù)據(jù)量級來劃分版本,以便高級功能觸達更多的潛在客戶。此外,微軟還特意推出了可免費下載安裝的 Developer Edition,除了不能用于生產(chǎn)環(huán)境之外,在功能與數(shù)據(jù)量級上與最高級的 Enterprise Edition 完全一致,沒有任何限制,大大降低了開發(fā)者們體驗和嘗試各項企業(yè)級功能的門檻。
一個繞不開的話題,也許是同 MySQL、PostgreSQL 等開源關(guān)系型數(shù)據(jù)庫以及各種 SQL on Hadoop 數(shù)據(jù)庫的比較。客觀地說,開源浪潮的確對商業(yè)數(shù)據(jù)庫產(chǎn)生了巨大的沖擊,出于直接成本的原因,以互聯(lián)網(wǎng)行業(yè)為代表的諸多企業(yè)紛紛采用了開源方案。然而,隨著多年來大家對開源體系與運作模式的理解不斷加深,尤其是積累了大量的實踐經(jīng)驗之后,市場逐漸趨于理性,開始更客觀地看待開源模式的利弊和適用場景。天下畢竟沒有免費的午餐,當(dāng)企業(yè)的核心業(yè)務(wù)高負荷地運行在開源軟件之上時,恐怕一樣需要購買并不便宜的商業(yè) support 服務(wù),或是雇傭大量高級人才來了解和掌控底層的源碼級細節(jié)。所以,不少企業(yè)會寧愿直接選擇性能更佳、穩(wěn)定性更高、企業(yè)級特性更豐富的商業(yè)數(shù)據(jù)庫——因為對于這些企業(yè)來說,選擇 SQL Server 具有更低的總體擁有成本。
從開發(fā)環(huán)境與工具生態(tài)上來看,SQL Server 同樣具有深厚的積累。向來口碑頗佳的 SQL Server Management Studio 一直是微軟持續(xù)投入的數(shù)據(jù)庫綜合管理工具,為 SQL Server 帶來了強大而易用的圖形化管理界面,可以免費下載使用;在各版本的 Visual Studio 中,也可以通過 VS 內(nèi)置的 Server Explorer 連接和查詢 SQL Server,與開發(fā)過程緊密聯(lián)動——這些充分體現(xiàn)了微軟大廠所能夠帶來的整合優(yōu)勢。另外值得一提的是,在編程語言支持方面,除了自家的 C#/.NET,SQL Server 團隊近年來明顯加大了對于其他流行語言支持的力度,尤其是 Java 和 PHP,為這些語言和平臺帶來了高質(zhì)量的客戶端類庫支持。
最后,說說 SQL Server 之于中國市場。其實在國內(nèi),得益于在教育領(lǐng)域的耕耘和出色的產(chǎn)品易用性,SQL Server 一直有著比較好的群眾基礎(chǔ)和親和形象。但若要在中國的高端市場打開局面,還需要進一步塑造品牌,打造標桿案例,消除之前給部分人群留下的“適用于中小企業(yè)”的陳舊印象。要做到這一點,除產(chǎn)品本身需不斷提升以滿足大客戶苛刻需要外,還必須重視本地技術(shù)社區(qū)的建設(shè),并幫助從業(yè)人員獲得良好的職業(yè)發(fā)展,形成良性循環(huán)。另外,隨著 Azure 云在中國的落地和發(fā)力,SQL Server 家族也大可借公有云發(fā)展之勢進行推廣,分享增長紅利。
寫在最后
關(guān)系型數(shù)據(jù)庫源遠流長,在許多場景下仍具有不可替代的重要地位。SQL Server 作為關(guān)系型數(shù)據(jù)庫中的翹楚,一路走高,不斷煥發(fā)著生機與活力。SQL Server 2017 的發(fā)布,有助于微軟進一步鞏固其市場地位,并通過支持 Linux 這一殺手锏,向新的市場發(fā)起有力沖擊。
其實 SQL Server 特性之多,一文遠不能窮盡。限于篇幅,我們沒有提及 AlwaysOn、AlwaysEncrypted 等企業(yè)級特性,也沒有詳細介紹 SQL Server Integration Service、Analysis Service、Reporting Service 等商業(yè)智能套件。但通過本文上述的分析,我們已清晰地了解了這個投入巨資的商業(yè)關(guān)系數(shù)據(jù)庫在新時代的大致輪廓與發(fā)展策略。如果用八個字來概括的話,“兼收并蓄,開放外聯(lián)”當(dāng)是最好的詮釋。
那么,最后的問題來了:無論身處傳統(tǒng)行業(yè)還是消費互聯(lián)網(wǎng),無論基于 Linux 還是 Windows 平臺,你的下一個關(guān)鍵應(yīng)用,會選擇 SQL Server 嗎?
作者介紹
何愷鐸,國雙科技 (Nasdaq:GSUM) 高級技術(shù)總監(jiān)。畢業(yè)于清華大學(xué),曾供職于摩根士丹利基礎(chǔ)架構(gòu)部門,2011 年加入國雙科技工作至今。數(shù)年來參與架構(gòu)和設(shè)計了國雙多個面向數(shù)字營銷和社交聆聽的大數(shù)據(jù)解決方案。個人關(guān)注的技術(shù)領(lǐng)域包括.Net 生態(tài)系統(tǒng)、云計算、大數(shù)據(jù)技術(shù)棧等,曾撰寫發(fā)表本文姊妹篇《從 Visual Studio 2017 談起,解析微軟技術(shù)生態(tài)進化之道》。
延伸閱讀
https://blogs.technet.microsoft.com/dataplatforminsider/2014/03/13/microsoft-brings-innovations-from-sql-server-to-hadoop-with-stinger/
https://www.infoq.com/news/2012/11/Hekaton
https://blogs.technet.microsoft.com/dataplatforminsider/2016/12/16/sql-server-on-linux-how-introduction/
https://blogs.technet.microsoft.com/dataplatforminsider/2017/09/25/sql-server-2017-and-red-hat-enterprise-linux-offer/
https://hub.docker.com/r/microsoft/mssql-server-linux/
https://github.com/gridsum/dataflowex
https://blogs.technet.microsoft.com/dataplatforminsider/2017/04/20/graph-data-processing-with-sql-server-2017/
http://www.zdnet.com/article/microsoft-acquires-revolution-analytics/
https://blogs.technet.microsoft.com/dataplatforminsider/2016/03/29/in-database-advanced-analytics-with-r-in-sql-server-2016/
https://www.brentozar.com/archive/2017/04/look-ma-adaptive-joins/#comment-2392048
https://www.intel.com/content/www/us/en/processors/xeon/microsoft-sql-database-analytics-paper.html
https://info.microsoft.com/CO-SQL-CNTNT-FY16-09Sep-14-MQOperational-Register.html?ls=Website
















 京公網(wǎng)安備 11010502049343號
京公網(wǎng)安備 11010502049343號