



迭代式精益創業原則在今天已被充分理解,最低可行產品(MVP)是機構風險投資的先決條件,但很少有初創企業和投資者將這些原則擴展到他們的數據和AI策略中。他們認為,可以在未來的某個時候,用他們以后會招募的人員和技能來驗證自己對數據和人工智能的假設。
但我們所見過的最好的人工智能初創企業都是盡可能早地發現,它們是否收集了正確的數據,確保它們計劃建立的人工智能模型是否有市場,以及這些數據是否得到了恰當的收集。因此,我們堅信,在您的模型達到早期客戶所需的最小算法性能(MAP)之前,您必須嘗試驗證您的數據和機器學習策略。如果沒有這種驗證(相當于迭代軟件beta測試的數據),您可能會發現,花費大量時間和金錢構建的模型沒有您希望的那么有價值。
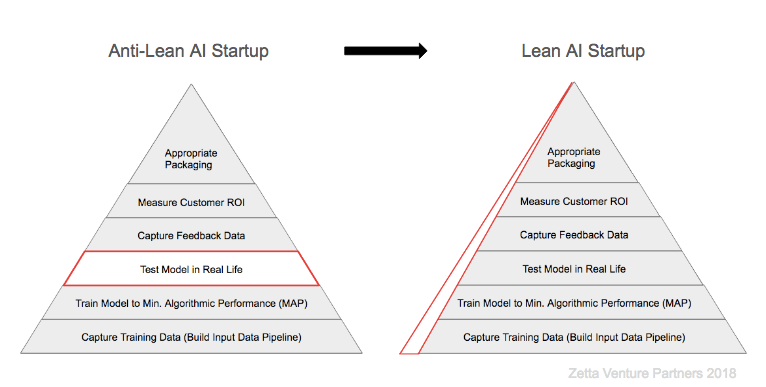
那么如何驗證算法呢?這里有三個關鍵測試你必須了解:
1. 測試數據的預測性
2. 測試模型市場適合度
3. 測試數據和模型的保質期
下面,讓我們來依次分析每個測試吧!
測試預測性
初創公司必須確保為其AI模型提供動力的數據能夠預測,而不僅僅是與AI的目標輸出相關聯。
由于人體非常復雜,人工智能驅動的診斷工具是一種特別容易將相關信號誤認為具有預測性的信號的應用。通過應用AI跟蹤每周掃描的細微變化,我們遇到了許多公司在患者結果方面取得了令人難以置信的收益。潛在的混雜因素可能是正在進行這些每周掃描的患者也更經常地記錄他們的生命體征,這也可能提供關于疾病進展的微妙線索。所有這些附加數據都用在算法中。人工智能是否可以在這些侵入性較小的生命體征上得到有效的訓練,從而降低患者的成本和壓力。
為了從真正的預測輸入中梳理出混雜的相關性,您必須盡早進行實驗,以便在有和沒有輸入的情況下比較AI模型的性能。在極端情況下,圍繞相關關系構建的AI系統可能更昂貴,并且可能比圍繞預測輸入建立的AI系統獲得更低的利潤。此測試還使您能夠確定是否正在收集AI所需的完整數據集。
測試模型市場適合度
您應該與產品市場契合度分別測試模型市場擬合。一些初創公司可能首先使用用于捕獲培訓數據的“預AI”解決方案進入市場。即使您可能已經建立了適合該AI前產品的產品市場,但您不能假設該AI前解決方案的用戶也會對AI模型感興趣。模型市場擬合測試的見解將指導您如何打包AI模型并建立合適的團隊以將該模型推向市場。
測試模型-市場匹配比測試產品-市場匹配更難,因為用戶界面很容易原型化,但人工智能模型很難模擬。要回答模型-市場匹配問題,您可以使用“幕后人”來模擬AI模型,以評估最終用戶對自動化的響應。虛擬調度助理啟動X.AI,使用這種方法來訓練它的調度程序機器人,并通過觀察人類訓練者進行的數萬次交互來找到合適的交互模式和音調。這種方法可能不適用于內容或數據可能包含敏感或受法律保護的信息的應用程序,例如醫生與其患者或律師與其客戶之間的交互。
為了測試客戶是否愿意為AI模型付費,您可以將數據科學家奉獻給現有客戶的顧問,并為他們提供個性化的,數據驅動的規范性見解,以展示AI的投資回報率。我們已經看到許多初創公司在醫療保健,供應鏈和物流領域提供這項服務,以說服客戶投入時間和人力來建立與客戶技術堆棧的集成。
測試數據和模型保質期
初創公司必須盡早了解他們的數據集和模型過時的速度,以便保持適當的數據收集和模型更新速率。由于上下文漂移,數據和模型變得陳舊,當AI模型試圖預測的目標變量隨時間變化時發生。
上下文信息可以幫助解釋上下文漂移的原因和速率,以及幫助校準漂移的數據集。例如,零售購買可能與季節有關。人工智能模型可能會發現冬季羊毛帽的銷量增加,并且在4月份未能成功推薦給客戶。如果在收集數據時沒有記錄,那么關鍵的上下文信息就無法恢復。
為了衡量上下文漂移的速度,您可以嘗試“模擬”模型并觀察其在實際設置中性能下降的速度。您可以使用以下某些策略在不訓練數據的情況下執行此操作:
1. 在適用的情況下,使用已知框架構建基于規則的模型;
2. 重新調整在強相關但獨立的域上訓練的模型,例如使用書籍推薦模型來推薦電影;
3. 使用機械特克斯模擬客戶數據;
4. 與行業現有企業合作獲取歷史數據;
5. 在互聯網上搜索公開數據;
如果模擬模型快速降級,AI模型將容易受到上下文漂移的影響。在這種情況下,歷史數據可能在過去的某個時間點之后沒有用,因為訓練過時數據的AI模型將不準確。
新時代,新劇本
企業客戶和投資者越來越多地將數據和人工智能視為初創公司必要的競爭優勢,但人工智能產品仍然需要重量級的開發流程。與所有業務問題一樣,您仍必須盡可能早地驗證您的數據和人工智能策略,以避免在無法取得成果的項目上浪費寶貴的時間和資源。這里概述的三個測試提供了一種在構建工作模型之前驗證AI模型的方法。 隨著越來越多的初創公司實施它們,這些想法將成為創建精益AI啟動的工具包的一部分,并將改變智能時代風險投資的標準。








 京公網安備 11010502049343號
京公網安備 11010502049343號