


深度強化學習(DRL)是人工智能研究領域的一個令人興奮的領域,具有潛在的問題領域的適用性。有些人認為DRL是人工智能的一種途徑,因為它通過探索和接收來自環境的反饋來反映人類的學習。最近DRL代理的成功打敗了人類的視頻游戲玩家,廣為人知的圍棋大師被人工智能AlphaGo擊敗,以及在模擬中學習行走的兩足球員的演示,都讓人們對這個領域產生了普遍的熱情。
與監督機器學習不同,在強化學習中,研究人員通過讓一個代理與環境交互來訓練模型。當代理的行為產生期望的結果時,它得到正反饋。例如,代理人獲得一個點數或贏得一場比賽的獎勵。簡單地說,研究人員加強了代理人的良好行為。
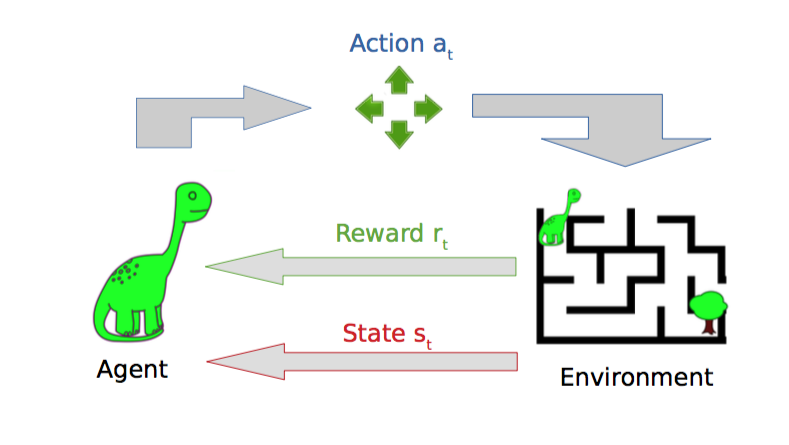
將DRL應用于非平凡問題的關鍵挑戰之一是構建一個獎勵功能,它鼓勵人們期望的行為而不會產生不良的副作用。當你犯錯時,會發生各種各樣的壞事,包括欺騙行為。(想想獎勵一個機器人服務員,在一些視覺上測量房間的清潔程度,只是教機器人打掃家具下面的污垢。)
值得注意的是,深度強化學習——“deep”指的是底層模型是一個深層的神經網絡——仍然是一個相對較新的領域,強化學習從20世紀70年代或更早的時候就開始了,這取決于你如何計算。正如Andrej Karpathy在他2016年的博客文章中所指出的,關鍵的DRL研究,如AlphaGo論文和Atari Deep Q-Learning paper都是基于已經存在了一段時間的算法,但是用深度學習代替了其他方法來近似函數。他們對深度學習的使用,當然是在過去20多年里我們看到的廉價計算能力的爆發。
DRL的承諾,以及谷歌在2014年以5億美元收購DeepMind的承諾,影響了一些希望利用這項技術的初創公司。本周,我采訪了Bonsai的創始人Mark Hammondfor。該公司提供了一個開發平臺,用于將深度強化學習應用于各種工業用例。我還與加州大學伯克利分校的Pieter Abbeelon討論了這個話題。從那以后,他創立了“實體智能”公司,這是一家依然隱秘的初創公司,打算將VR和DRL應用于機器人技術。
由楊致遠(Jerry Yang)、彼得•蒂爾(Peter Thiel)、肖恩•帕克(Sean Parker)以及其他知名投資者支持的Osaro,也希望在工業領域應用DRL。與此同時,人工智能正在尋找最佳的傳統對沖基金,并將其應用于算法交易,而DeepVu正在應對管理復雜企業供應鏈的挑戰。
由于對DRL的興趣增加,我們也看到了新的開源工具包和用于培訓DRL代理的環境。這些框架中的大多數本質上都是專用的仿真工具或接口。這些是目前AI中比較流行的工具:
OpenAI Gym
OpenAI gym是一個流行的開發和比較增強學習模型的工具箱。它的模擬器界面支持多種環境,包括經典的Atari游戲,以及像MuJoCo和darpa資助的Gazebo這樣的機器人和物理模擬器。和其他DRL工具包一樣,它提供了api來反饋意見和回報給代理。
DeepMind Lab
DeepMind Labis是一個基于Quake III第一人稱射擊游戲的3D學習環境,為學習代理提供導航和解謎任務。DeepMind最近添加了dmlab30,一個新級別的集合,并介紹了它的newImpaladistributed agent培訓體系結構。
Psychlab
另一個DeepMind工具包,今年早些時候開放源代碼,心理實驗室擴展DeepMind實驗室,以支持認知心理學實驗,如搜索特定目標的一系列項目或檢測一系列項目中的變化。然后,研究人員可以比較人類和人工智能在這些任務上的表現。
House3D
加州大學伯克利分校和Facebook人工智能研究人員之間的合作,在45000個模擬室內場景中模擬室內場景和家具布局。本文介紹的主要任務是“概念驅動的導航”,比如訓練一個代理導航到一所房子的房間,只提供一個高級的描述符,比如“餐廳”。
Unity Machine Learning Agents
在AI和MLDanny Lange副總裁的領導下,游戲引擎開發者Unity正在努力將尖端的人工智能技術融入其平臺。Unity Machine Learning Agents,于2017年9月發布,是一個開源Unity插件,可以在平臺上運行游戲和模擬,作為訓練智能代理的環境。
Ray
雖然這里列出的其他工具集中于DRL培訓環境,但Ray更關注DRL的基礎結構。Ray是在Berkeley RISELab開發的byIon Stoicaand他的團隊,它是高效運行集群和大型多核機器上的Python代碼的框架,具體目標是為增強學習提供一個低延遲的分布式執行框架。
所有這些工具和平臺的出現將使DRL更易于開發人員和研究人員使用。但是,他們需要所有的幫助,因為深度強化學習在實踐中是很有挑戰性的。谷歌工程師亞歷克斯·伊爾潘最近發表了一篇頗具煽動性的文章,題為“深度強化學習還不起作用”。Irpan引用了DRL所需要的大量數據,事實上,DRL的大多數方法都沒有利用之前關于系統和環境的知識,以及前面提到的困難,在其他問題中也有一個有效的獎勵功能。
我希望在未來的一段時間內,從研究和應用的角度來看,深度強化學習將繼續成為人工智能領域的熱門話題。它在處理復雜、多面和順序的決策問題方面表現出了極大的希望,這使得它不僅對工業系統和游戲有用,而且對市場、廣告、金融、教育、甚至數據科學本身也有很大的用處。








 京公網安備 11010502049343號
京公網安備 11010502049343號