


新年之初
向各位讀者報告一則喜訊!
剛剛過去的12月
戴爾易安信PowerEdge XE8545
在“2021中國互聯(lián)網(wǎng)經(jīng)濟(jì)論壇”上
喜提“2021年度卓越人工智能產(chǎn)品”獎
祝賀XE8545!
恭喜戴爾易安信AI服務(wù)器再創(chuàng)佳績!


2021中國互聯(lián)網(wǎng)經(jīng)濟(jì)論壇由互聯(lián)網(wǎng)周刊、中國社會科學(xué)院信息化研究中心、eNet研究院、德本咨詢聯(lián)合主辦,自2002年起已成功舉辦十九屆,是業(yè)內(nèi)極具分量的互聯(lián)網(wǎng)行業(yè)盛會。論壇核心板塊的“金i獎”極具權(quán)威性和專業(yè)度,覆蓋了AI、大數(shù)據(jù)、5G等各行業(yè)領(lǐng)域,歷來被業(yè)內(nèi)視為代表互聯(lián)網(wǎng)精神和產(chǎn)業(yè)發(fā)展創(chuàng)新的風(fēng)向標(biāo)。
辭舊迎新之際,宜總結(jié)過去展望未來,當(dāng)下AI大潮席卷全球,作為底層邏輯的AI服務(wù)器又將走向何方?或許我們能從基準(zhǔn)( Benchmark )測試?yán)镒x出一些趨勢。

基準(zhǔn)( Benchmark ) 測試是目前最主要的信息系統(tǒng)性能測試技術(shù),它按照統(tǒng)一的測試規(guī)范(test specification)對被測對象進(jìn)行測試,測試結(jié)果具有可比性和可再現(xiàn)性。在計算機(jī)領(lǐng)域,Benchmark測試應(yīng)用最廣泛和最成功的是性能測試,主要關(guān)注響應(yīng)時間、傳輸速率和吞吐量等。
對生產(chǎn)廠商而言,Benchmark測試可以為產(chǎn)品進(jìn)行市場宣傳,發(fā)現(xiàn)系統(tǒng)瓶頸;對用戶的作用則在于指導(dǎo)產(chǎn)品選擇。一個優(yōu)秀的Benchmark測試可以為某一領(lǐng)域的技術(shù)發(fā)展起到積極導(dǎo)向作用,引導(dǎo)廠商采用新技術(shù)以改進(jìn)產(chǎn)品。

筆者記得20年前最火的Benchmark測試無疑是TPC-C ,當(dāng)年還是小型機(jī)(簡稱小機(jī))時代,PS小機(jī)是中國特色的叫法,國外稱其為UNIX服務(wù)器。隨著x86和云原生應(yīng)用的興起,TPC瞬間就不香了。
自2006年AlphaGo打敗李世石后,業(yè)界急需公認(rèn)的AI時代基準(zhǔn)測試程序,萬眾期待之下,MLPerf AI性能基準(zhǔn)測試于2018年由MLCommons發(fā)布。

MLCommons成員包括谷歌、微軟、英特爾、NVIDIA、Facebook、阿里巴巴等多家在人工智能領(lǐng)域頗有建樹的領(lǐng)導(dǎo)企業(yè)。自推出后,MLPerf AI性能基準(zhǔn)測試以其全面性、科學(xué)性、廣泛參與度,業(yè)已成為全球最受關(guān)注的AI性能基準(zhǔn)測試,并為很多用戶AI計算方案設(shè)計及選型提供重要參考依據(jù)。
(一)
AI/DL落地傳統(tǒng)企業(yè),
4GPU服務(wù)器是最佳平衡
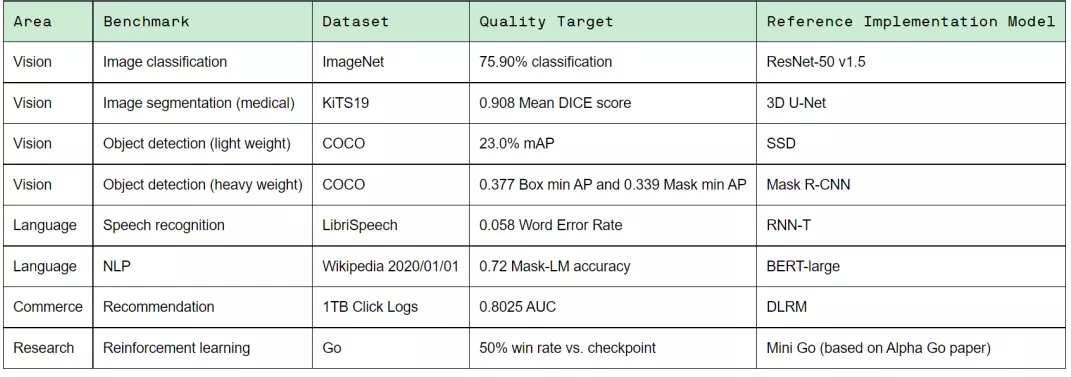
在去年12月初發(fā)布的MLPerf Training v1.1基準(zhǔn)測試中,戴爾易安信共提交了51項測試結(jié)果,包括全部八個項目的性能數(shù)據(jù),取得多項世界紀(jì)錄。
戴爾易安信參評了兩款4GPU機(jī)型服務(wù)器——PowerEdge XE8545和R750xa,分別取得如下幾項的世界第一:
(1)XE8545獲得四卡GPU加速服務(wù)器的四項最佳:
●目標(biāo)檢測Mask R-CNN(83.77分鐘)
●語音識別RNN-T(79.56分鐘)
●自然語言處理BERT(38.85分鐘)
●強(qiáng)化學(xué)習(xí)Mini Go(451.29分鐘)
(2)R750xa獲得四卡GPU加速服務(wù)器的語音識別RNN-T最佳(84.02分鐘);
戴爾易安信的測試數(shù)據(jù)、配置及Log,均可以在GitHub上找到:
https://sourl.cn/3FXXed
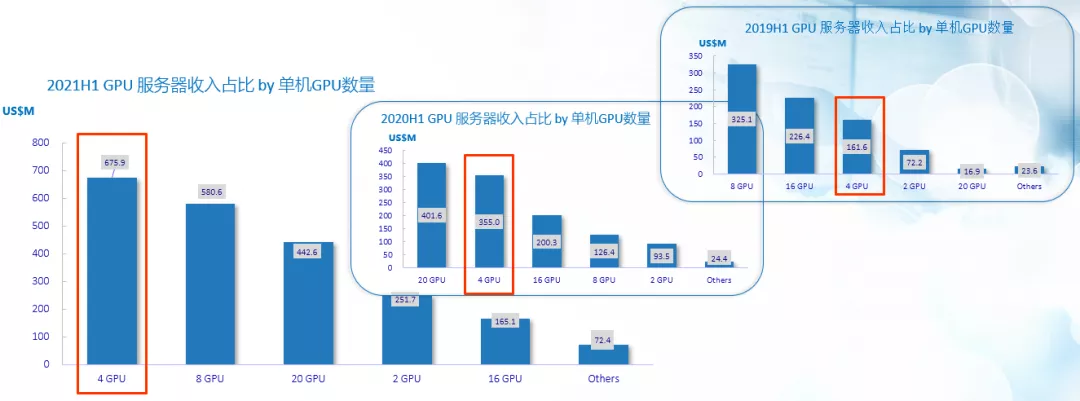
和友商專注于8顆GPU的單機(jī)測試不同,戴爾易安信更關(guān)注4顆GPU的單機(jī)和集群測試。
根據(jù)IDC連續(xù)三年的統(tǒng)計,4個雙寬GPU的機(jī)型在2021年成為市場主流。主要在于隨著單GPU性能的提升(如A100 vs V100),現(xiàn)如今4*GPU機(jī)器的性能已經(jīng)超越上代8*GPU的機(jī)型。
另一個主要原因是AI/DL(Deep Learning)的早期采用者,互聯(lián)網(wǎng)行業(yè)的GPU服務(wù)器占比正逐年下降,而金融/制造/政府/電信等行業(yè)占比則逐漸上升,AI/DL正逐漸落地傳統(tǒng)行業(yè)。
相比互聯(lián)網(wǎng),傳統(tǒng)行業(yè)很少需要高密度GPU服務(wù)器,因而4GPU服務(wù)器是當(dāng)前條件下的最佳平衡。
(二)
多機(jī)多卡GPU分布式訓(xùn)練
成為必然選擇
MLPerf Training v1.1基準(zhǔn)測試中,除了GPU服務(wù)器單機(jī)測試外,戴爾易安信是唯一的服務(wù)器廠家提供基于GPU多機(jī)分布式訓(xùn)練測試結(jié)果的廠商。
萬億級參數(shù)規(guī)模的AI模型訓(xùn)練、超大規(guī)模NLP/推薦系統(tǒng)特征向量、更大規(guī)模數(shù)據(jù)集更短訓(xùn)練時間——AI時代洶涌而來的超級算力需求,僅靠單臺GPU服務(wù)器已經(jīng)無法滿足,多機(jī)多卡GPU分布式訓(xùn)練成為必然選擇。
我們可以類比一下從當(dāng)年128路SMP小機(jī)到現(xiàn)在主流兩路x86集群的進(jìn)化歷程,戴爾易安信認(rèn)為GPU服務(wù)器的進(jìn)化也是類似:單機(jī)16/20個GPU的服務(wù)器已經(jīng)讓位于4/8個GPU服務(wù)器的集群。
2021年,戴爾易安信在國內(nèi)發(fā)布了《戴爾科技AI GPU分布式訓(xùn)練技術(shù)白皮書》,將戴爾易安信在構(gòu)建AI GPU加速集群、進(jìn)行AI GPU分布式訓(xùn)練全局優(yōu)化的參考架構(gòu)和最佳實踐分享給更多的用戶和朋友。

特別值得一提的是參與MLPerf Training v1.1基準(zhǔn)測試的PowerEdge XE8545,它在4U機(jī)架式空間內(nèi)可以支持風(fēng)冷散熱的4張NVIDIA A100 80GB/500W GPU加速卡,通過最新的NVLink技術(shù)實現(xiàn)全互聯(lián)(full mesh)。
XE8545服務(wù)器設(shè)計簡單直接,CPU(AMD第三代EPYC米蘭)與GPU、GPU與GPU、CPU與網(wǎng)卡及NVME SSD存儲,采用PCI-E 4.0或者NVLink實現(xiàn)直連,可最大程度降低通信及IO延遲,同時大大簡化程序員工作。

戴爾易安信 PowerEdge XE8545
由于卓越的性能和市場表現(xiàn),PowerEdge XE8545喜提“金i獎”榮譽(yù),它歷經(jīng)層層篩選脫穎而出,表明其不凡實力已獲得行業(yè)高度認(rèn)可。
再過幾年,戴爾服務(wù)器也將迎來30周年,作為“在中國,為中國”的“外資本土”企業(yè),戴爾易安信一定不負(fù)用戶和媒體的支持和厚愛,持續(xù)研發(fā)各行業(yè)都適用的IT基礎(chǔ)設(shè)施,推動AI項目在中國傳統(tǒng)行業(yè)真正落地。






注的AI性能基準(zhǔn)測試")

 京公網(wǎng)安備 11010502049343號
京公網(wǎng)安備 11010502049343號