


那么,算力對企業而言是否可以得到提升?近期在2019第56屆設計自動化大會(,創新奇智的CTO張發恩等人聯合發布了一篇論文《Efficient GPU NVRAM Persistence with Helper Warps》(https://dac.com/content/2019-dac-accepted-papers)。該論文首次提出一種方法,通過在GPU上使用NVRAM存儲的有效并且易于使用的事務處理系統,在特定應用場景下,GPU性能獲得了4~5倍的提升。據了解,設計自動化大會簡稱為DAC,其英文全稱ACM/IEEE Design Automation Conference,目前是電子設計自動化和嵌入式系統領域的頂級會議。

上圖為:創新奇智CTO張發恩
現狀:非易失性存儲場景中,GPU性能無法得到完全發揮
張發恩在接受企業網D1Net記者專訪時指出:目前算力是人工智能領域各企業都在突破的重點,一般采用GPU與CPU方式,但GPU是CPU算力的50倍,因此算力更加強大。GPU一般用于人工智能模型的訓練與人工智能模型的推理兩個應用場景下。
當科學家和工程師將GPU應用于人工智能模型訓練和推理后,雖然發現帶來了巨大的算力提升,但在非易失性存儲場景中,GPU性能并沒有得到完全發揮,因此,如何進一步提升GPU性能成為眾多AI公司的重要關注點。
提升GPU性能 提升算力
算力是人工智能突破的三大要素之一,而提升GPU性能則是提升算力的關鍵。企業需要及時處理日益增長的海量客戶數據。比如零售領域里:智能貨柜和渠道陳列平臺每天都要為客戶處理數百萬張高清圖片;制造行業里:工業視覺平臺需要在車間產線實時處理超清圖片;智慧園區:平臺需要同時處理多路高清攝像頭視頻數據;數據智能項目需要及時處理大規模用戶行為數據等等。
張發恩發現:當企業的AI訓練平臺對大量的數據進行處理時,其異構計算對GPU性能的提升提出了更為緊迫的要求。張發恩所在的創新奇智和其他合作伙伴一起,通過大量實驗推導,提出了一種方法:通過在GPU上使用NVRAM存儲的有效并且易于使用的事務處理系統,可在特定應用場景下,讓GPU性能獲得了4~5倍的提升。
開放共享 責任擔當
當企業網D1Net記者詢問張發恩,為何會選擇將這一研究成果公布?張發恩說:“人工智能產業需要更多人、更多企業參與進來,形成更大更良好的生態圈,既有基礎領域的研究,也有落地的實踐應用,這個產業才能走得更遠更穩。我所在的創新奇智是一家源于創新工場的人工智能創新科技公司,始終堅信技術為立身之本。公司自成立以來非常重視技術研究,為促進人工智能行業更為快速的發展,我們愿將具備廣泛應用價值的技術分享出來,以期讓更多企業從中受益,這是一個創新型企業應有的責任擔當!”
下附論文解讀:

摘要
非易失性隨機存取存儲器(NVRAM)是近年來出現的一種用于彌補主存和外部存儲設備之間性能差距的存儲器。為了利用NVRAM的非揮發性,程序應該允許持久化存儲,這意味著在斷電事件期間必須保持一致性。利用高度的并行性,GPU的設計具有高吞吐量。然而,與DRAM相比,NVRAM具有更低的寫入帶寬,按照原樣使用NVRAM可能會產生次優的總體系統性能。為了解決這個問題,作者提出使用Helper Warp(暫簡單譯為輔助調度單位)將持久性移出事物執行的關鍵路徑,從而減輕延遲的影響。在帶寬限制為1.6GB/s和12GB/s的情況下,該機制分別實現了4.4倍和1.5倍的加速,并且預計即使在NVRAM帶寬高達數百GB/s的某些情況下,也將保持速度優勢。
介紹
非易失性隨機存取存儲器(NVRAM)作為一種很有前途的NVRAM替代品,在過去的幾年里逐漸成熟起來。MVRAM具有大容量和持久性,因此可以啟用和證明諸如事物內存之類的新編程范例。
可字節尋址的持久存儲設備(如NVRAM)有幾種不同的使用方式。在最簡單的形式中,它可以作為DRAM或者緩存的大容量臨時替代。這種類型的系統在CPU和GPU上都討論過,但是沒有利用它們的持久性。另一種更復雜的方法是使用NVRAM作為持久數據存儲,使其成為事務處理系統(TPS)的一個組成部分。TPS的體系結構通常包括兩層:并發協議層,它可能表現為事務內存或者鎖定機制,負責檢測和解決事務之間的完整性;日志層,以日志的形式執行寫操作,以實現持久性,從而在斷電事件期間保持數據完整性。在CPU上,這種TPS系統可以涉及硬件、軟件和編程語言級別的變化;在GPU上是落后于CPU的,因為在GPU上存在基于事務內存的工作但在當前時刻不存在基于NVRAM的TPS系統。
盡管NVRAM的存儲密度較大,但它提供的帶寬比DRAM的緩存要少。因此,需要很好地管理帶寬引起的延遲,以避免性能下降。為了減輕帶寬差距帶來的損失,需要采用軟硬件結合方法。
本文主要有以下三點貢獻:
(1)在這篇工作中作者首次提出了在GPU上使用NVRAM存儲的有效并且易于使用的事務處理系統。
(2)作者提出使用Helper Warp,利用GPU的閑置計算資源來緩解寫入帶寬的限制。
(3)作者建立了一種在不同的程序下能夠自適應地啟用Helper Warp(輔助調度單位)達到最佳性能的機制。
高效的GPU NVRAM持久性支持
事務處理通常由并發控制和持久性日志記錄兩部分組成。論文研究的系統采用軟件事務內存(STM)進行并發控制。作者提出的STM算法采用了快速沖突檢測以及重做日志記錄,并解決與全局所有權記錄的沖突。寫/讀集跟蹤的粒度是一個32位機器字。對較大數據的訪問被視為多個32位機器字。該算法不區分讀與寫,并通過支持線程ID較低的事務來解決沖突。具體的算法步驟如圖2所示。

圖2:論文中使用的STM算法
在上述TM算法中,對NVRAM的寫入發生在成功提交期間。在默認的嚴格的Persis-tency模型下,事務必須等待persist操作完成之后才能聲明提交成功。這將NVRAM寫延遲添加到事務執行的關鍵路徑上,從而增加時間開銷。為了解決這個問題,論文作者提出了一個commit過程,它利用Helper Warp將延遲移出關鍵路徑。
帶有輔助調度單位的高效日志系統
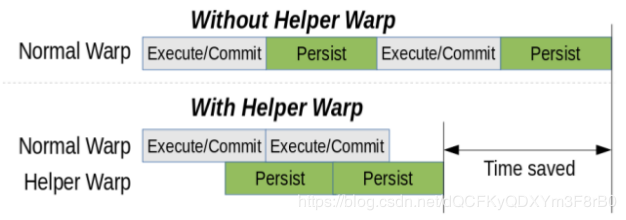
圖3:論文提出框架中的事務時間線
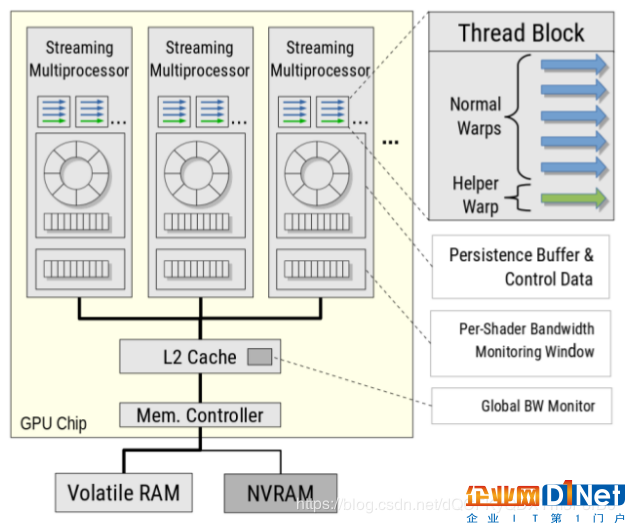
圖4:總體系統框架
作者提出的方法使用輔助調度單位來分離事務的提交和持久步驟。輔助調度單位負責處理事務的持久性部分,使持久操作能夠與事務的其余部分異步完成。圖3顯示了添加了輔助調度單位的總體提交協議。
每個線程塊中都有一個輔助調度單位,它通過每個線程塊共享內存與正常調度單位通信。此外,每個流多處理器(SM)都有一個帶寬監控窗口,用于跟蹤運行時的瞬時帶寬占用情況。圖4演示了作者提出的框架,它包括內存拓撲和添加的部分。易失性RAM和非易失性RAM之間的聯系類似于最近的AMD Vega框架,該框架旨在支持異構內存框結構,如SSD和DRAM。
系統評估
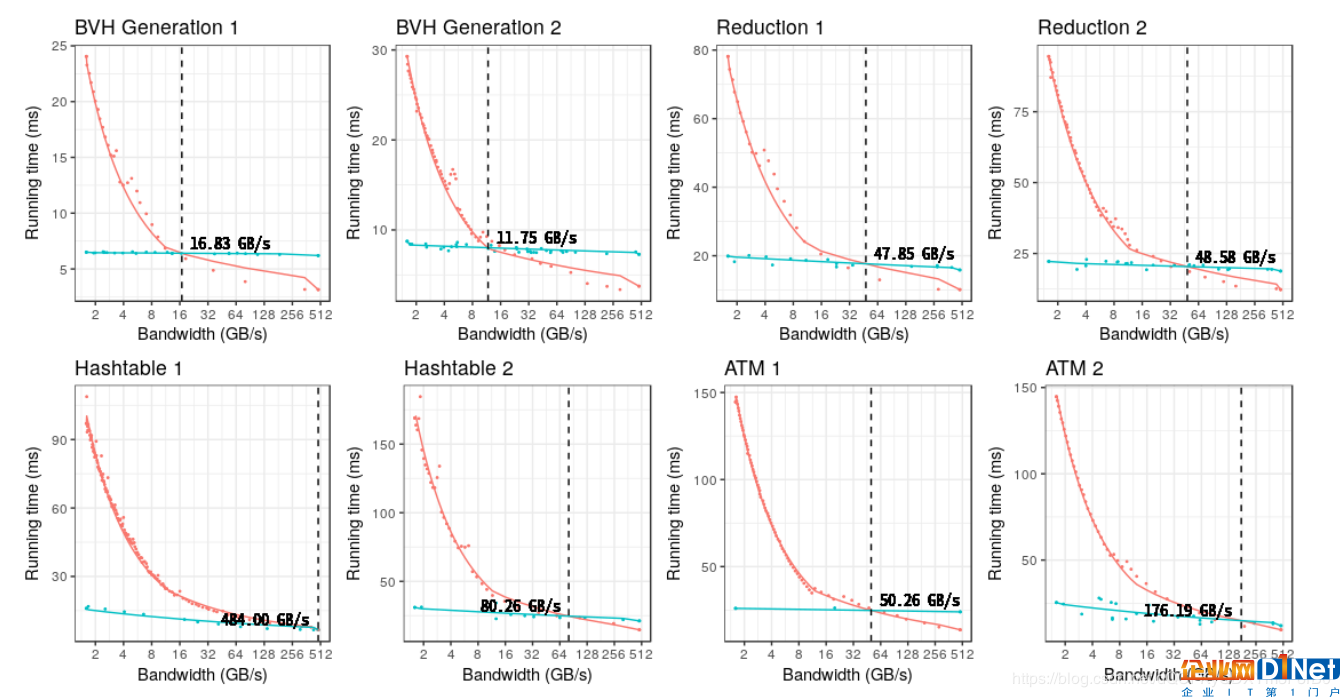
圖6:基準測試的總體運行時間,啟用了輔助調度單位(綠色)和禁用了輔助調度單位(紅色)
圖6展示了使用實驗設置的基準測試的運行時間,包括啟用和禁用輔助調度單位。這些線表示運行時間隨著NVRAM帶寬限制而變化的趨勢。綠色和紅色的線和點分別表示啟用和禁用輔助調度單位的運行時間。隨著帶寬的降低,兩種配置的運行時間都會增加。不過,沒有輔助調度單位的運行時間最終會增長得更快,并超過啟用輔助調度單位的運行時間。這兩條運行時間存在交叉點。H1的交叉點高達484GB/s(這意味著即使在易失性RAM帶寬下,輔助調度單位的性能也會更好),而BVH1的交叉點則低至11.75GB/s。
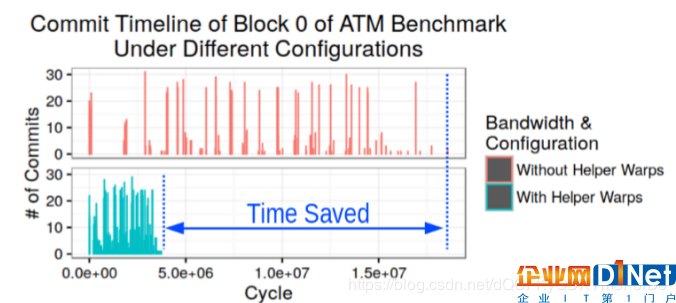
圖7:基準測試A1的塊級事務提交時間線
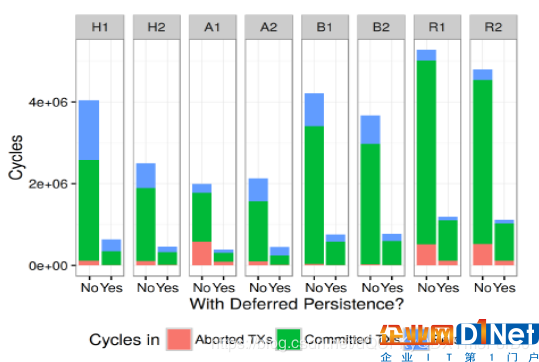
圖8:基于元數據TM的事務平均執行時間的細分
圖7展示了基準測試A1中第0塊中事務的提交時間線。可以看出,當持久性帶寬限制為1.6GB/s時,連續提交會出現很大的差距。由于不同塊之間的行為是相似的,這種差異將直接轉化為更長的總體運行時間。有了輔助調度單位,差距明顯減小,從而大大縮短了基準測試的運行時間。
圖8展示了線程塊0中事務執行時間的細分情況,其中輔助調度單位靜態地打開和關閉。由于帶寬有限造成的每個sistence階段的延遲會導致“caso-cade”效應,使得其他提交事務的時間比帶有輔助帶調度單位的時間長。這是由于調度單位級別的差異和持有所有權記錄使得提交事務需要等待冗長的持久性操作的完成。這也增加了中止率。通過啟用輔助調度單位,持久性可以更快地完成,并且“級聯”效應得到了緩解。
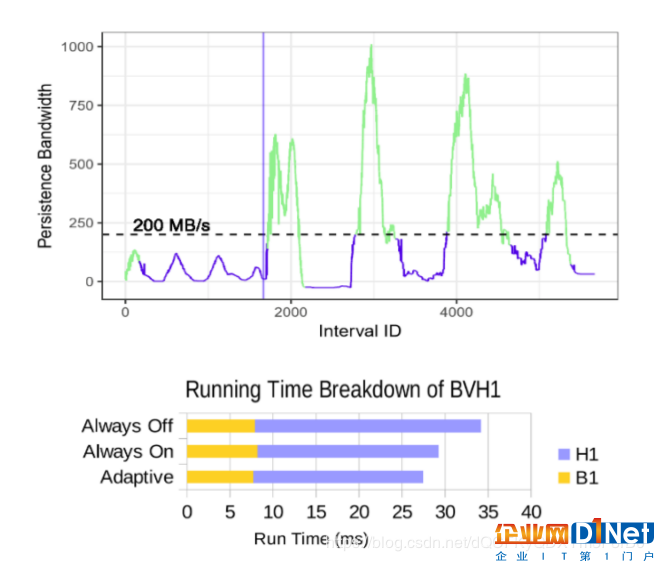
圖9:基準測試B1+H1的持續帶寬趨勢,帶有輔助調度單位的自適應切換(上圖)和3種配置的運行時間細分(下圖)
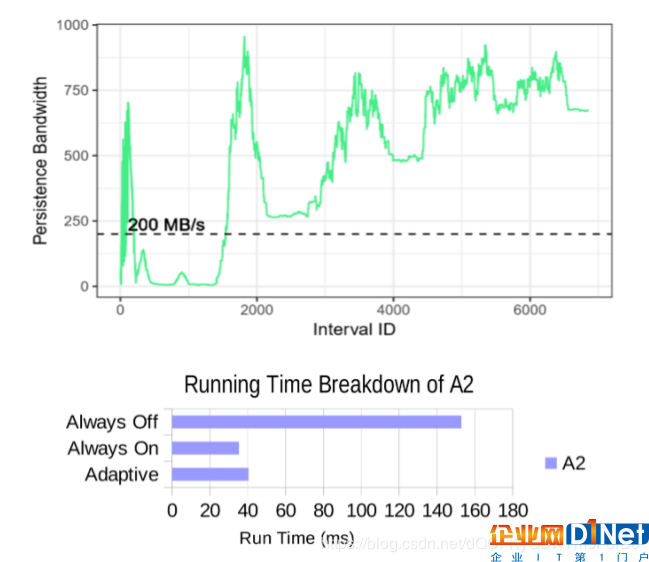
圖9顯示了輔助調度單位在操作中的切換以響應不斷變化的持久性帶寬。總的來說,切換顯著減少了H1內核的時間,與總是關閉輔助調度單位相比運行時間提高了20%,與總是打開輔助調度單位相比運行時間提高了6%。
圖10:基準測試A2的持續帶寬趨勢,關閉輔助調度單位(頂部)和3種配置的運行時間細分(底部)
與BVH基準測試相反,其他一些基準測試將觀察到提交帶寬高于大多數程序執行的閾值,比如A2。其持久性帶寬趨勢可以在圖10(頂部)中觀察到。對于這個基準測試,始終靜態地打開或關閉輔助調度單位會導致輕微的性能損失,如圖10(底部),這是由于切換所涉及的開銷造成的。
結論
在本文中,作者觀察到事務GPU程序的性能下降來源于NVRAM的帶寬限制,這種限制導致了長時間的持久性延遲。當NVRAM用作主存的臨時替代品時,延遲將直接添加到事務的關鍵路徑上,從而使事務的運行時間更長。此外,這種延遲可能會影響位于相同調度單位的其他線程,從而導致整個基準測試的運行時間更長.
作者提出了Helper warp這個概念,它由位于片上共享內存中的提交緩沖區組成,事務提交將被重定向到該緩沖區。這將從關鍵路徑中移除時間開銷,使持續性操作更快。作者還提出了一種方法,使輔助器僅在需要最好性能時才使用。在某些情況下,閾值可能高達每秒數百GB。這包括今天和不久的將來可用的NVRAM帶寬范圍。








 京公網安備 11010502049343號
京公網安備 11010502049343號