



MathWorks公司總部產(chǎn)品市場經(jīng)理趙志宏
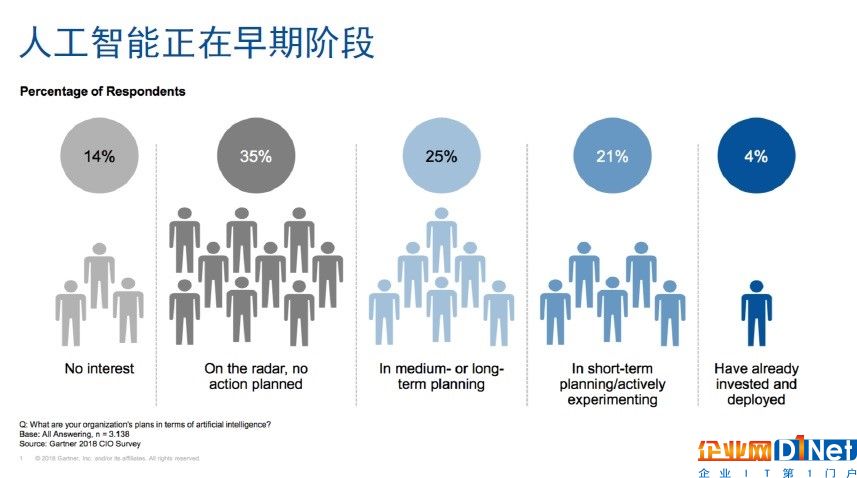
在Gartner最近所做的一次問卷調(diào)查中,不同行業(yè)的3000多家公司大約有50%已經(jīng)把AI列入了他們未來的產(chǎn)品和管理計劃當中,但是只有大約4%的公司能夠真正地運用AI技術。所以,MathWorks公司總部產(chǎn)品市場經(jīng)理趙志宏日前在MathWorks Expo 2018上發(fā)表主題演講時稱,“即使今天才去了解AI,其實也并不晚。”
20180613-mathworks-1
“毫無疑問,我們正處于一個重大技術變革的時代。”但趙志宏說,目前還只是AI的初級階段,機器學習實際上也只是人工智能這個大范疇里的一個重要組成部分而已,很多時候人們把這兩個詞互相等同,甚至互相代替,是完全錯誤的。
那么,如果擁有了數(shù)據(jù)、輸出和機器學習模型,是否就意味著可以開始擁抱人工智能了?趙志宏對此給出了否定的回答。在他看來,數(shù)據(jù)、輸出和模型只是整個AI開發(fā)流程的一個步驟而已,對傳感器、文件系統(tǒng)和數(shù)據(jù)庫的數(shù)據(jù)訪問,以數(shù)據(jù)探索、預處理和特定領域算法為代表的數(shù)據(jù)分析,以及如何在桌面應用、企業(yè)系統(tǒng)、嵌入式設備中進行部署,甚至是開發(fā)流程中的算法開發(fā)、建模與仿真,都是人工智能應用過程中需要認真考慮的問題。

20180613-mathworks-2
萬事俱備,只欠……
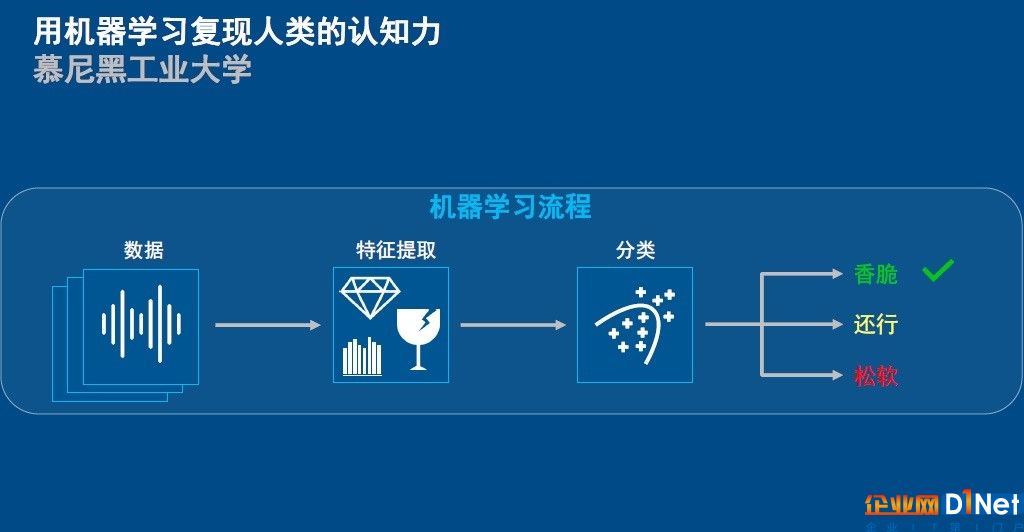
在演講中,趙志宏以膨化食品智能檢測為例,向大家證明即使用戶從未使用過機器學習,也可以利用MATLAB提供的APP進行學習,去嘗試所有機器學習的算法和模型。在這一案例中,研究人員在用戶咬食品的時候提取特征,用咬合聲音和力度去衡量食品的松脆度,再利用MATLAB提供的分類學習器進行訓練。在訓練過程中,用戶可以看到每個分類器的整體結(jié)果,選擇精確度最高的一個,然后進行更多的調(diào)查和研究。
20180613-mathworks-3
相比從數(shù)據(jù)中提取特征值,其實分類器的開發(fā)并不是最困難的。如果對“特征工程”有所了解的話,就會知道特征工程主要目的,其實就是最大程度地從原始數(shù)據(jù)中提取特征向量,然后再利用這些特征向量去訓練機器學習或深度學習模型。尤其是在深度學習流程中,深度神經(jīng)網(wǎng)絡不需要人工手動的找出特征值,而是可以自動的從數(shù)據(jù)中學習到特征值。但顯而易見的是,這一過程需要大量的數(shù)據(jù)做支撐,如果遇到以下幾個問題,開發(fā)者是否就會處于束手無策的境地?第一,數(shù)據(jù)量不夠如何訓練模型?第二,數(shù)據(jù)量太大如何快速進行標注?第三,沒有合適的數(shù)據(jù)怎么辦?
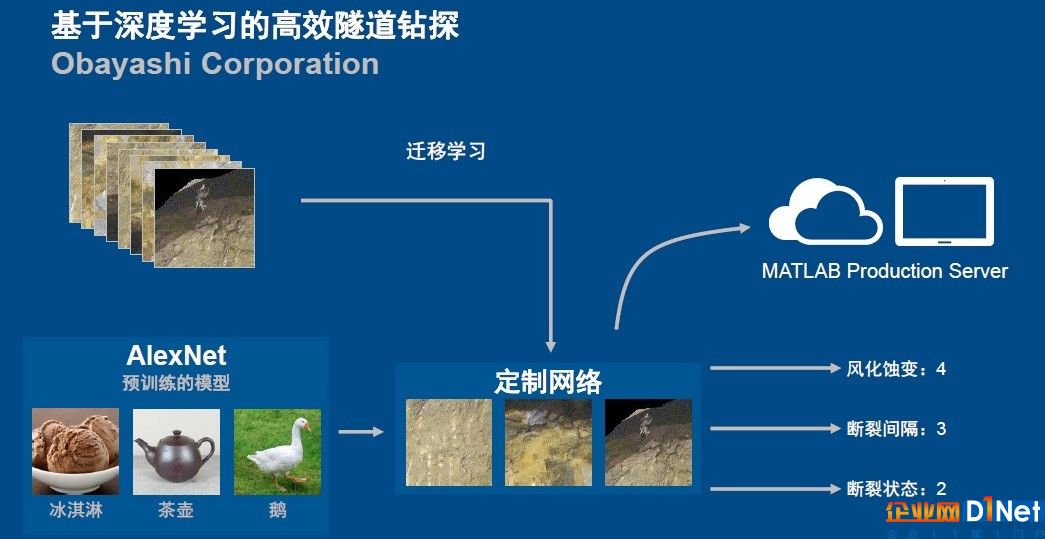
如果數(shù)據(jù)不足,能做人工智能嗎?這是很多初創(chuàng)公司的困惑。“遷移學習可能會是一個不錯的選擇。”在趙志宏所列舉的高效隧道鉆探案例中,日本科學家利用已有的AlexNet網(wǎng)絡,將手邊僅有的1000余張經(jīng)過標記的隧道表面地質(zhì)狀況照片進行定制性訓練,使得新網(wǎng)絡能夠識別地質(zhì)參數(shù),識別精度也達到了90%以上。然后,將開發(fā)好的算法利用MATLAB Production Server部署到云端,這樣,鉆井工程師、探測工程師就可以通過使用IPAD隨時隨地對隧道的表面照片進行探測,從而大大地提高了挖掘效率。
“只需要寫5行的MATLAB代碼,用戶就可以建出一個能夠識別食品或者其他家庭常用物品的網(wǎng)絡。”趙志宏說。
20180613-mathworks-4
隨著傳感器的大量采用,數(shù)據(jù)量激增,給人工智能進行特征標記帶來了一定的困難,趙志宏建議可以采用深度學習進行標記。例如最新發(fā)布的Autopilot toolbox自動駕駛工具箱里,就提供了為自動駕駛而使用的自動標注功能。LiDAR三維點云技術可以對每一點進行標注,把這個點聚類在一起聚成一個目標模型,然后再把目標具體代表的實物辨別出來。有些用戶已經(jīng)采用MATLAB的工具進行了開發(fā),著名的汽車配件公司AUTOLIV就在用這種方式進行自動數(shù)據(jù)標注。
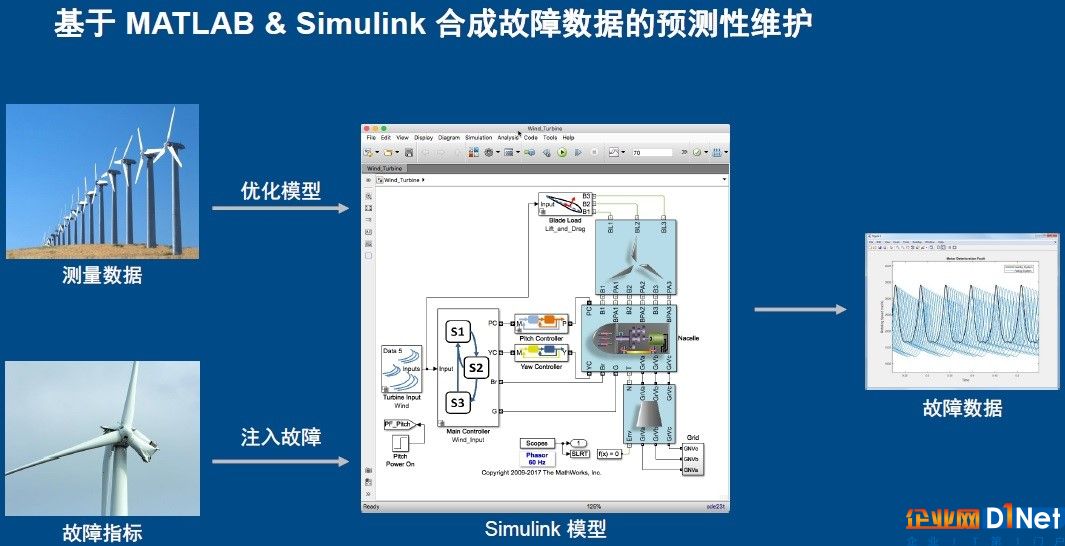
“沒有數(shù)據(jù)還玩什么AI?”這可能是很多人的第一反應。但在趙志宏給出的另一個案例中,用戶不可能等采集到大量風力發(fā)電機的故障數(shù)據(jù)之后再做預測,這樣不符合設備維護的目標。所以業(yè)內(nèi)人士的做法是先用Simulink模型建立一個風里發(fā)電機的模型,通過校正讓這個模型非常接近風力發(fā)電機,然后通過該模型產(chǎn)生故障數(shù)據(jù),進而訓練機器學習或者深度學習的神經(jīng)網(wǎng)絡。
20180613-mathworks-5
這就是基于模型設計的優(yōu)勢。它的開發(fā)理念是在真正做出產(chǎn)品之前,建好一個與實際產(chǎn)品非常接近的模型,不管是從數(shù)字計算、行為計算產(chǎn)生的結(jié)果與真正的結(jié)果都非常接近。然后在這個模型上加入故障情況就很容易產(chǎn)生故障數(shù)據(jù),這比在實際設備上產(chǎn)生的故障要容易很多。因此,可以進行故障預測和維護。
數(shù)據(jù)、算法和算力并稱為AI三大要素。除了數(shù)據(jù)外,快速迭代的神經(jīng)網(wǎng)絡算法和針對不用應用的算力,會在多大程度上影響MathWorks的工具開發(fā)?趙志宏對此回應稱,公司的研發(fā)團隊時刻都在關注AI算法的演進和變化,他們希望深度學習工具箱新增的功能與技術發(fā)展是同步的。此外,工具箱不僅是針對某一功能產(chǎn)生正確的結(jié)果,還要考慮如何把這個功能做得簡單易用。比如針對AI應用,MathWorks的愿景是希望把界面做得非常適合該專業(yè)領域,兼顧用戶感受,降低學習門檻,容易上手。
而在計算力方面,面對需要極強算力的場景(GPU應用)和需要在功耗/算力間取得平衡的場景,MathWorks的主要目的在于通過提供多樣化的代碼生成工具,加速用戶開發(fā)過程。以最新開發(fā)的GPU coder工具箱為例,工程師可以將訓練出來機器模型網(wǎng)絡直接下載到英偉達的芯片中,不必手動嘗試各種代碼,幾分鐘或者幾小時之內(nèi)就可以得到測試結(jié)果。






據(jù)、輸出和模型,你就敢擁抱人工智能嗎?")

 京公網(wǎng)安備 11010502049343號
京公網(wǎng)安備 11010502049343號